


前言
Hi,大家好,又见面了,我是Python进阶者,废话不多说,直接开始肝吧,奥里给!
爬虫管理效果图
依赖包
文件:requirements.txt
文件的内容这里直接贴出来了:
- appdirs==1.4.4
- APScheduler==3.5.1
- attrs==20.1.0
- Automat==20.2.0
- beautifulsoup4==4.9.1
- certifi==2020.6.20
- cffi==1.14.2
- chardet==3.0.4
- constantly==15.1.0
- cryptography==3.0
- cssselect==1.1.0
- Django==1.11.29
- django-apscheduler==0.3.0
- django-cors-headers==3.2.0
- djangorestframework==3.9.2
- furl==2.1.0
- gerapy==0.9.5
- gevent==20.6.2
- greenlet==0.4.16
- hyperlink==20.0.1
- idna==2.10
- incremental==17.5.0
- itemadapter==0.1.0
- itemloaders==1.0.2
- Jinja2==2.10.1
- jmespath==0.10.0
- lxml==4.5.2
- MarkupSafe==1.1.1
- orderedmultidict==1.0.1
- parsel==1.6.0
- Protego==0.1.16
- pyasn1==0.4.8
- pyasn1-modules==0.2.8
- pycparser==2.20
- PyDispatcher==2.0.5
- pyee==7.0.2
- PyHamcrest==2.0.2
- pymongo==3.11.0
- PyMySQL==0.10.0
- pyOpenSSL==19.1.0
- pyppeteer==0.2.2
- pyquery==1.4.1
- python-scrapyd-api==2.1.2
- pytz==2020.1
- pywin32==228
- queuelib==1.5.0
- redis==3.5.3
- requests==2.24.0
- Scrapy==1.8.0
- scrapy-redis==0.6.8
- scrapy-splash==0.7.2
- scrapyd==1.2.1
- scrapyd-client==1.1.0
- service-identity==18.1.0
- six==1.15.0
- soupsieve==2.0.1
- tqdm==4.48.2
- Twisted==20.3.0
- tzlocal==2.1
- urllib3==1.25.10
- w3lib==1.22.0
- websocket==0.2.1
- websockets==8.1
- wincertstore==0.2
- zope.event==4.4
- zope.interface==5.1.0
项目文件
项目文件:qiushi.zip
实现功能:糗事百科段子爬虫,
这是Scrapy项目,依赖包如上
运行项目步骤
配置Scrapyd
可以理解Scrapyd是一个管理我们写的Scrapy项目的,配置好这个之后,可以通过命令运行,暂停等操作控制爬虫
其他的就不说了,这个用的也不多,我们需要做的就是将它启动就可以了
启动Scrapyd服务
1.切换到qiushi爬虫项目目录下,Scrapy爬虫项目需要进入爬虫目录,才能执行命令

2.执行命令scrapyd
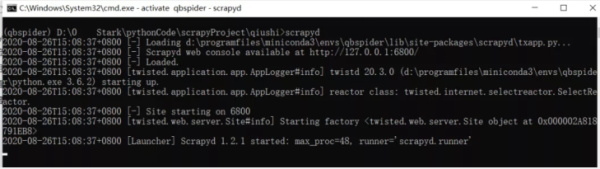
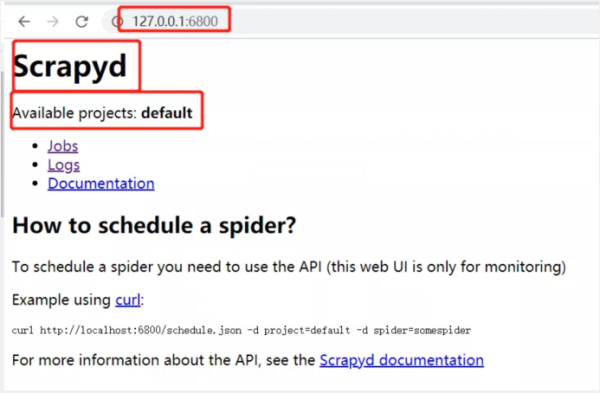
3.游览器输入http://127.0.0.1:6800/,出现以下图片代表正确
打包Scrapy上传到Scrapyd
上述只是启动了Scrapyd,但是并没有将Scrapy项目部署到Scrapy上,需要配置以下Scrapy的scrapy.cfg文件
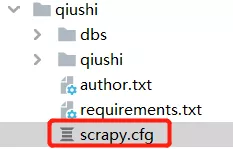
配置如下
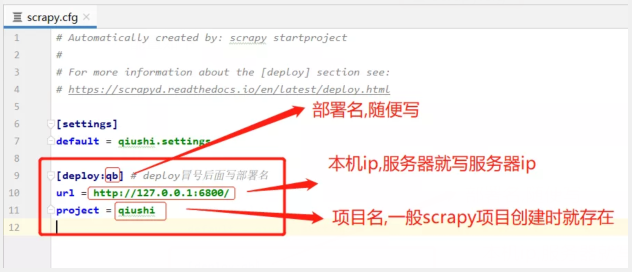
打包命令
- scrapyd-deploy <部署名> -p <项目名>
本次示例命令
- scrapyd-deploy qb -p qiushi
如图所示,出现以下图片表示成功

注:过程可能会有问题,解决办法我放在后面了!!!
再次回到游览器,会多了一个项目qiushi,到此为止,Scrapyd已经配置完毕
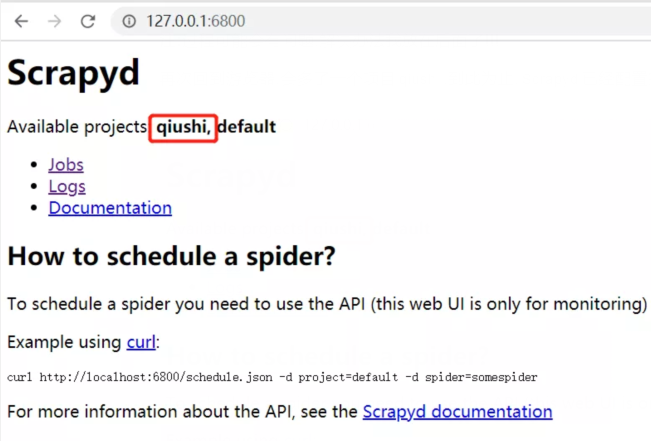
配置Gerapy
上述都配置完毕之后,就可以进行Gerapy配置了,其实Scrapyd的功能远不止上述那么少,但是是命令操作的,所以不友好,
Gerapy可视化的爬虫管理框架,使用时需要将Scrapyd启动,挂在后台,其实本质还是向Scrapyd服务发请求,只不过是可视化操作而已
基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发
配置步骤
Gerapy和Scrapy是没有关系的,所以可以随便选一个文件夹,这里我创建了一个gerapyDemo文件夹

执行命令初始化gerpay
- gerapy init

1.会生成一个gerapy文件夹
2.进入生成的gerapy文件夹中

3.执行命令,会生成一表
- gerapy migrate
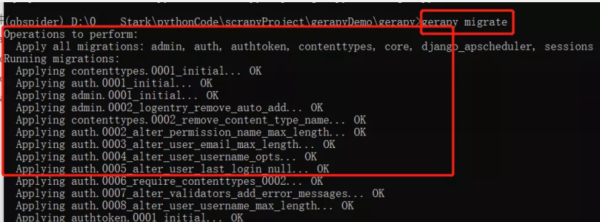
4.启动gerapy服务,默认是8000端口,可以指定端口启动
- gerapy runserver
- gerapy runserver 127.0.0.1:9000 本机 9000端口启动
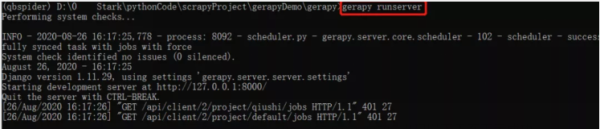
4.打开游览器,输入http://127.0.0.1:8000/,出现以下界面表示成功
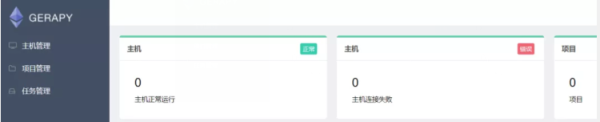
当然,一般情况下,大概是这样的界面,我们需要生成账号密码
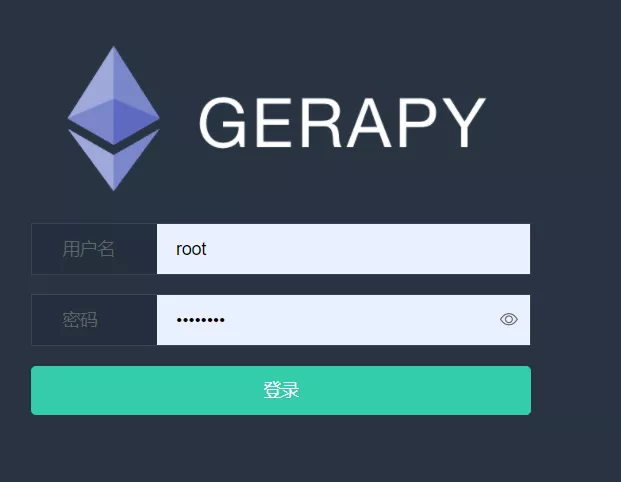
停止服务,输入命令gerapy creatsuperuser,根据提示创建账号密码就使用账号登录了

在Gerapy添加爬虫项目
上述都配置之后,我们就可以配置爬虫项目了,通过点点点的方式,就可以运行爬虫了
点击 主机管理-->创建,ip是Scrapyd服务的主机,端口是Scrapyd的端口,默认6800,填写后点击创建
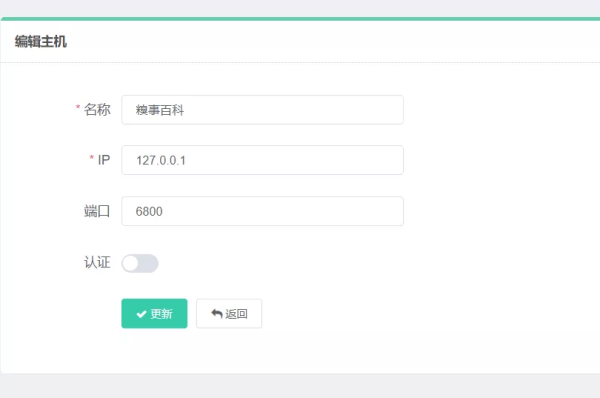
然后在主机列表,调度中,就可以运行爬虫了

运行爬虫
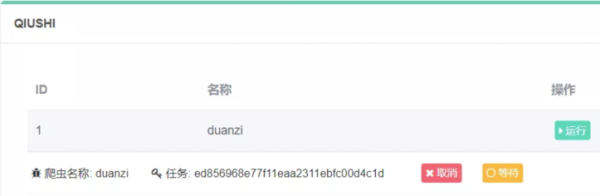
获取结果,结果已经写入本地
打包爬虫上传
上述过程,我们只是能玩爬虫了,但是并不彻底,按照道理来说,我们还差一个打包过程,只有打包爬虫了,才算是真正的结合在一起了
步骤
1.首先需要将爬虫项目拷贝到gerapy下面的projects文件夹下
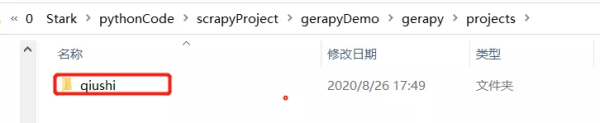
2.刷新页面,点击项目管理,可以看到可配置和打包都是x号状态

3.点击部署,写好描述,点击打包
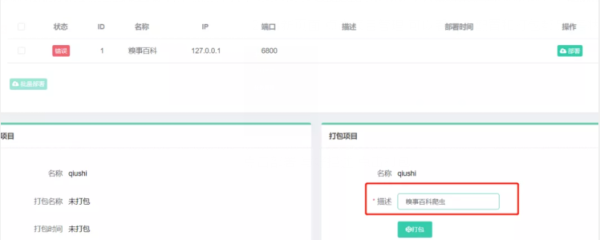
4.再次回到主界面,可以发现打包已经是正确的了

至此,基本整个流程结束。
解决scrapyd-deploy不是内部外部命令
通常情况下,在执行scrapyd-deploy时,会提示scrapyd-deploy不是内部或外部命令,嗯...这个是正常操作
解决步骤
1.找到Python解释器下面的Scripts,新建scrapy.bat和scrapyd-deploy.bat两个文件
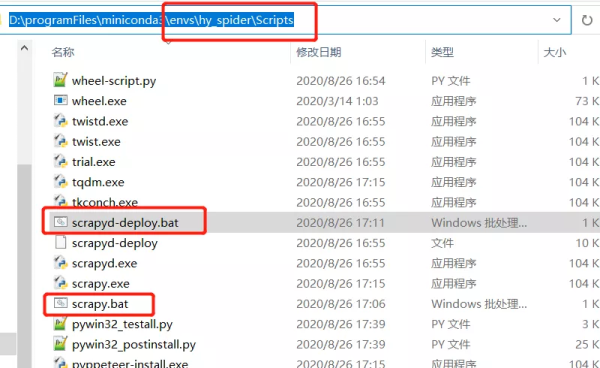
修改这两个文件,内容如下
- scrapy.bat
- @echo off
- D:\programFiles\miniconda3\envs\hy_spider\python D:\programFiles\miniconda3\envs\hy_spider\Scripts\scrapy %*

- scrapyd-deploy.bat
- @echo off
- D:\programFiles\miniconda3\envs\hy_spider\python D:\programFiles\miniconda3\envs\hy_spider\Scripts\scrapyd-deploy %*
注:红色方框表示是解释器的位置,上述内容是一行的,我粘贴过来怎么调都是两行...,一一对应好就好了。
Gerapy使用流程总结
- 1.gerapy init 初始化,会在文件夹下创建一个gerapy文件夹
- 2.cd gerapy
- 3.gerapy migrate
- 4.gerapy runserver 默认是127.0.0.1:8000
- 5.gerapy createsuperuser 创建账号密码,默认情况下都是没有的
- 6.游览器输入127.0.0.1:8000 登录账号密码,进入主页
- 7.各种操作,比如添加主机,打包项目,定时任务等
总结
上述以入门的方式解决了安排了以下如何通过Gerapy + Scrpyd + Scrapy可视化部署爬虫。

本期导读 :【数据迁移】第三讲主题:如何将 HDFS 海量文件归档到 OSS讲师:辰石...
说明 JetBrains 全系列产品永久激活教程 适用于 JetBrains 全系列产品 2018、201...
一、你是怎么阅读PDF文件的? 作为已经软件开发人员,阅读代码或者 PDF文件是家常...
特邀嘉宾 项昭贵 项公 -阿里巴巴高级技术专家 视频地址: https://summit.aliyun....
11月18日,中国社会科学院中国产业与企业竞争力研究中心与社会科学文献出版社联...
操作场景 本节为您介绍通过控制台提供的CloudShell登录云服务器的操作步骤。 登...
由于上次主要分析如何解决异步获取不到Session问题,所以没有展开分析留下的那个...
国内有哪些 云服务器品牌 ?因为 云计算 这几年发展非常迅速,国内提供云服务的...
通过流我们可以将一大块数据拆分为一小部分一点一点的流动起来,而无需一次性全...
如果您需要对FunctionGraph的函数资源,给企业中的员工设置不同的访问权限,以达...

