

大数据之数据仓库分层
1. 什么是数据分层?
数据分层是一套行之有效的数据组织和管理方法,使得数据体系更有序。
2. 数据分层的好处
(1)清晰数据结构
每一个数据分层都有它的作用域和职责,在使用表的时候能更方便的定位和理解。
(2)减少重复开发
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
(3)统一数据口径
通过数据分层,提供统一的数据出口,统一对外输出的数据口径。
(4)复杂问题简单化
将一个复杂的任务分解成多个步骤完成,每一层解决特定的问题。
一种通用的数据分层设计

3. 举例
以下是一个电商网站的数据体系设计,只关注用户访问日志这部分数据。

4. 各层会用到的计算引擎和存储系统
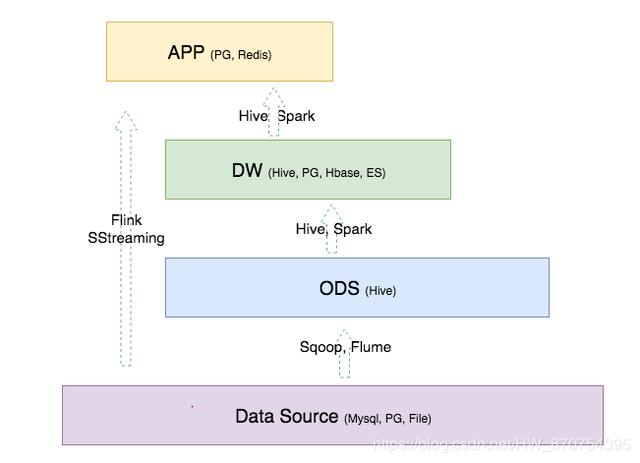
5.分层实现
在确定建模思路和模型类型之后,下一步的工作是数据分层。数据分层可以使得数据构建体系更加清晰,便于数据使用者快速对数据进行定位;同时数据分层也可以简化数据加工处理流程,降低计算复杂度。
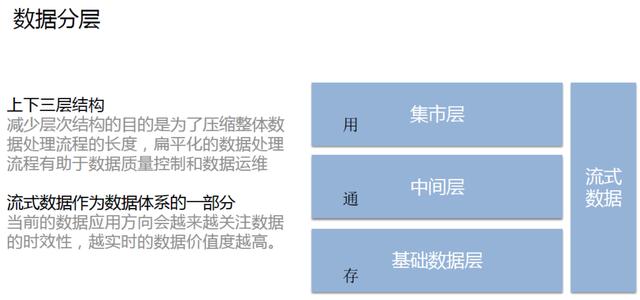
我们常用的数据仓库的数据分层通常分为集市层、中间层、基础数据层上下三层结构。由传统的多层结构减少到上下三层结构的目的是为了压缩整体数据处理流程的长度,同时扁平化的数据处理流程有助于数据质量控制和数据运维。
在上下三层的结构的右侧,我们增加了流式数据,将其添加成数据体系的一部分。这是因为当前的数据应用方向会越来越关注数据的时效性,越实时的数据价值度越高。
但是,由于流式数据集的采集、加工和管理的成本较高,一般都会按照需求驱动的方式建设;此外,考虑到成本因素,流式数据体系的结构更加扁平化,通常不会设计中间层。
下面来具体看下每一层的具体作用。
数据基础层

数据基础层主要完成的工作包括以下几点:
数据中间层

数据中间层最为重要的目标就是把同一实体不同来源的数据打通起来,这是因为当前业务形态下,同一实体的数据可能分散在不同的系统和来源,且这些数据对同一实体的标识符可能不同。此外,数据中间层还可以从行为中抽象关系。从行为中抽象出来的基础关系,会是未来上层应用一个很重要的数据依赖。例如抽象出的兴趣、偏好、习惯等关系数据是推荐、个性化的基础生产资料。
在中间层,为了保证主题的完整性或提高数据的易用性,经常会进行适当的数据冗余。比如某一实事数据和两个主题相关但自身又没有成为独立主题,则会放在两个主题库中;为了提高单数据表的复用性和减少计算关联,通常会在事实表中冗余部分维度信息。
数据集市层

数据集市层是上下三层架构的最上层,通常是由需求场景驱动建设的,并且各集市间垂直构造。在数据集市层,我们可以深度挖掘数据价值。值得注意的是,数据集市层需要能够快速试错。
数据架构

数据架构包括数据整合、数据体系、数据服务三部分。其中,数据整合又可以分为结构化、半结构化、非结构化三类。
数据整合

结构化数据采集又可细分为全量采集、增量采集、实时采集三类。三种采集方式的各自特点和适应场合如上图所示,其中全量采集的方式最为简单;实时采集的采集质量最难控制。

在传统的架构中,日志的结构化处理是放在数仓体系之外的。在大数据平台仓库架构中,日志在采集到平台之前不做结构化处理;在大数据平台上按行符分割每条日志,整条日志存储在一个数据表字段;后续,通过UDF或MR计算框架实现日志结构化。
在我们看来,日志结构越规范,解析成本越低。在日志结构化的过程中,并不一定需要完全平铺数据内容,只需结构化出重要常用字段;同时,为了保障扩展性,我们可以利用数据冗余保存原始符合字段(如useragent字段)。

非结构化的数据需要结构化才能使用。非结构化数据特征提取包括语音转文本、图片识别、自然语言处理、图片达标、视频识别等方式。尽管目前数仓架构体系中并不包含非结构化数据特征提取操作,但在未来,这将成为可能。
数据服务化

数据服务化包括统计服务、分析服务和标签服务:
6.数据分层的一些概念说明
大数据数据仓库是基于HIVE构建的数据仓库,分布文件系统为HDFS,资源管理为Yarn,计算引擎主要包括MapReduce/Tez/Spark等,分层架构说明如下:
星型模式的基本思想就是保持立方体的多维功能,同时也增加了小规模数据存储的灵活性。
说明:
例如,某地区商品的销量,是从地区这个角度观察商品销量的。事实表就是销量表,维度表就是地区表
4、主题表:主题(Subject)是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。例如“销售分析”就是一个分析领域,因此这个数据仓库应用的主题就是“销售分析”。
面向主题的数据组织方式,就是在较高层次上对分析对象数据的一个完整并且一致的描述,能刻画各个分析对象所涉及的企业各项数据,以及数据之间的联系。所谓较高层次是相对面向应用的数据组织方式而言的,是指按照主题进行数据组织的方式具有更高的数据抽象级别。与传统数据库面向应用进行数据组织的特点相对应,数据仓库中的数据是面向主题进行组织的。例如,一个生产企业的数据仓库所组织的主题可能有产品订货分析和货物发运分析等。而按应用来组织则可能为财务子系统、销售子系统、供应子系统、人力资源子系统和生产调度子系统。
5、汇总数据层:聚合原子粒度事实表及维度表,为满足固定分析需求,以提高查询性能为目的,形成的高粒度表,如周报、月报、季报、年报等。
6、应用层:
为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形结构的数据。应用层为前端应用的展现提现数据,可以为关系型数据库组成。
7、【补充】
数据缓存层:
临时数据表层:
7. 大数据相关基础概念

参考消息网7月21日报道 港媒称,中国消费者已经习惯了把日常生活的一切交给手机A...
对于小型企业管理者来说,在商业世界更新的软件和开发中承担风险和机会是可怕的...
客户介绍 新浪微博(Sina Weibo)是基于用户关系的社交媒体平台,用户可以通过 P...
Step By Step 1、创建独享实力,并在独显实力下面创建产品, 控制台地址 2、pom....
客户简介 深圳盒子信息科技有限公司成立于2011年,是国家高新技术企业、深圳市高...
11月16日下午消息,世界互联网大会期间,CNNIC向腾讯、百度、美团、360、拼多多...
一、CPU Cache 存储设备往往是速度越快价格越昂贵,速度越快价格越低廉。 在计算...
Oracle云基础设施作为网络安全领军企业的首选云平台,可为其提供更高的性价比和安...
背景 我们知道 如果在Kubernetes中支持GPU设备调度 需要做如下的工作 节点上安装...
公司简介 陕西集群物联网服务管理股份有限公司旗下的“集群e家”是专注于社区商...

