


1. 背景
在我们的业务开发中,往往会碰到下面这个场景:
所以传统的处理架构可能会这样:
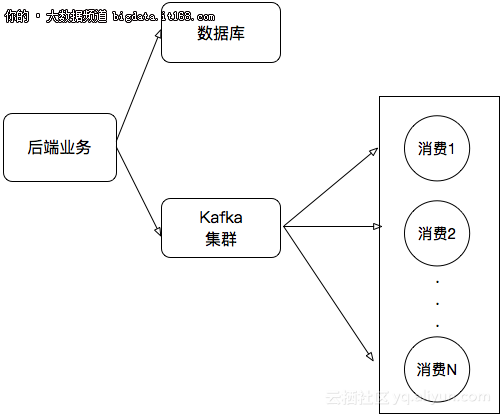
但这个架构也存在着不少弊端:我们需要在项目中维护很多发送消息的代码。新增或者更新消息都会带来不少维护成本。所以,更好的处理方式应该是直接将数据库的数据接入到流式系统中,如下图:
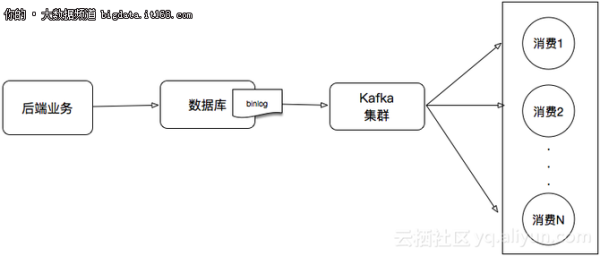
本文将演示如何在E-MapReduce上实现将RDS binlog实时同步到Kafka集群中。
2. 环境准备
实验中使用VPC网络环境,以下实例创建时默认都是在VPC环境下。
2.1 准备一个测试RDS数据库
创建一个RDS实例,版本选择5.7。这里不赘述如何创建RDS,详细流程请参考RDS文档。创建完如图:
2.2 准备一个Kafka集群
创建一个E-MapReduce Kafka集群,版本选择EMR-3.11.0。需要注意,这里必须选择EMR-3.11.0以上版本,否则不会默认安装启动Kafka Connect服务。详细创建流程请参考E-MapReduce文档。创建完如图:
注意:RDS实例和E-MapReduce Kafka集群***在同一个VPC中,否则需要打通两个VPC之间的网络。
3. Kafka Connect
3.1 Connector
Kafka Connect是一个用于Kafka和其他数据系统之间进行数据传输的工具,它可以实现基于Kafka的数据管道,打通上下游数据源。我们需要做的就是在Kafka Connect服务上运行一个Connector,这个Connector是具体实现如何从/向数据源中读/写数据。Confluent提供了很多Connector实现,你可以在这里下载。不过今天我们使用Debezium提供的一个MySQL Connector插件,下载地址。
下载这个插件,并将解压出来的jar包全部拷贝到kafka lib目录下。注意:需要将这些jar包拷贝到Kafka集群所有机器上。
在Kafka集群的服务列表中重启Kafka Connect组件。
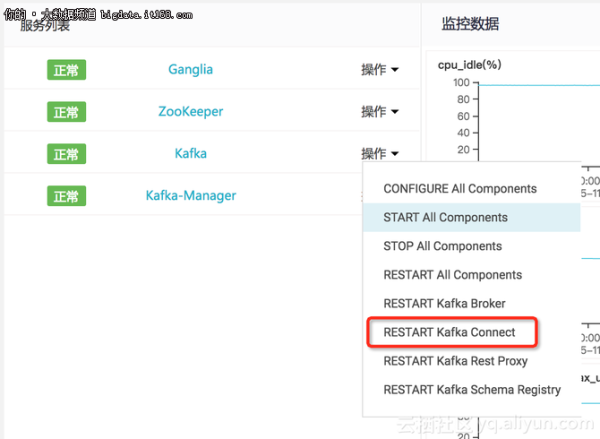
3.2 启动Connector
在创建connector前,我们需要做一番配置,这里罗列一些Debezium MySQL Connector的主要配置项:
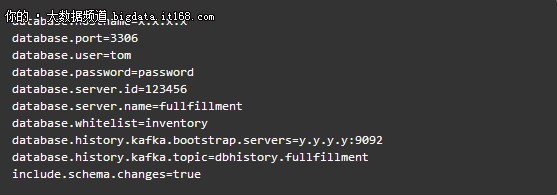
登录到Kafka集群,配置并创建一个connector,命令如下:

这时,我们可以看到一个创建好的connector,如图:
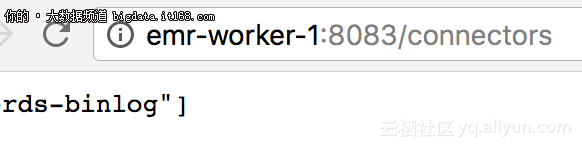
3.3 注意事项
server_id是多少?:你可以在RDS执行"SELECT @@server_id;"查到。
创建connector时可能会出现连接失败,请确保RDS的白名单已经授权了Kafka集群机器访问。
4 测试
4.1 创建一张表
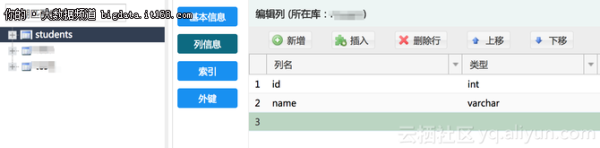
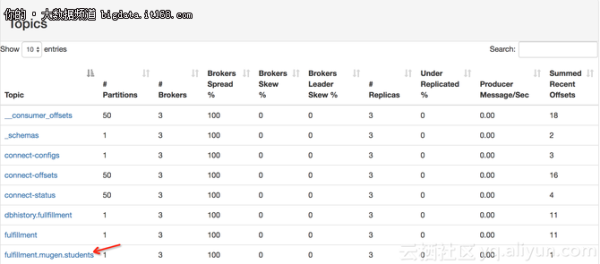
一会之后,Kafka集群中会自动创建一个对应的topic
插入几条数据

查看binlog数据
查看fulfillment.mugen.students这个topic,是否有刚刚新插入的数据

结果如图所示:

5. 资料

NSA Spy Cloud,NSA Spy Center,坐落于犹他州沙漠中的数据中心 Utah Data Cente...
访问速度慢,服务器不稳定 服务器是网站运行的根本,如果服务器不稳定,网站也就...
以下文章来源于信息通信技术与政策 ,作者谢家贵,齐超 等 1 引言 随着互联网和...
作为一个开发人员每天必不可少要提交代码,但是你真的懂代码提交吗?这篇文章带...
域名 都需要实名认证吗?我国要求域名进行实名认证,如果不完成实名,将会被禁止...
2019年3月9日(星期六)下午3点,无极教育云发布会暨平台年会在杭州市钱江新城剧...
如今人们对于虚拟会议这一概念并不陌生,尽管虚拟会议可以很好地传达信息,但是...
本文转载自微信公众号「三太子敖丙」,作者三太子敖丙。转载本文请联系三太子敖...
作者:铭毅天下 几个月以来,我一直在记录自己开发 Elasticsearch 应用程序的最...
当聊到React状态管理方案,很多人第一反应是Redux。 Redux为什么这么有名,个人...

