DataV是阿里云的可视化产品,能帮助您通过图形化的界面轻松搭建专业水准的可视化应用,丰富表现日志分析数据。本文档介绍如何通过日志服务对接DataV进行大屏数据展示。
背景信息
实时大屏广泛应用于大型在线促销活动。实时大屏基于流式计算架构,该架构包含以下模块:
- 数据采集:将来自各源头数据实时采集。
- 中间存储:利用类Kafka Queue进行生产系统和消费系统解耦。
- 实时计算:数据处理关键环节,订阅实时数据,通过计算规则对窗口中数据进行运算。
- 结果存储:计算结果数据存入SQL和NoSQL。
- 可视化:通过API调用结果数据进行展示。
在阿里集团内,有大量成熟的产品可以完成此类工作,一般可供选型的产品如下: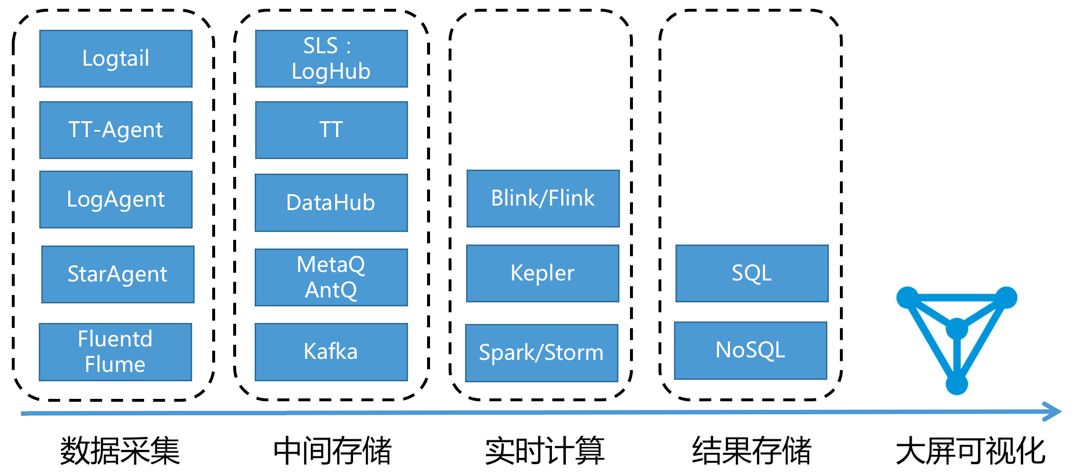
日志服务支持通过日志服务查询分析API直接对接DataV进行大屏数据展示。 
功能特点
计算方式根据数据量、实时性和业务需求会分为以下两种。
- 实时计算(流计算):固定的计算+变化的数据
- 离线计算(数据仓库+离线计算):变化的计算+固定的数据
在对实时性有要求的日志分析场景中,日志服务为您提供实时索引LogHub中数据机制,可通过LogSearch/Anlaytics直接进行查询分析。这种方式具有以下优势:
- 快速:一秒内查询(5个条件),可处理10亿级数据。一秒内分析(5个维度聚合+GroupBy),可聚合亿级别数据,无需等待和预计算结果。
- 实时:99.9%情况下可做到日志产生1秒内反馈到大屏。
- 动态:无论修改统计方法还是补数据,支持实时刷新显示结果,无需等待重新计算。
- 数据量:单次计算数据量限制为百亿行,当超过百亿行,需要限定时间段。
- 计算灵活度:计算限于SQL92语法,不支持自定义UDF。
DataV配置步骤
- 回调ID动态获取时间范围,以下步骤演示如何动态的显示15分钟的日志。
- 在交互页签,选中启用对应的响应事件,并将value绑定到变量中。
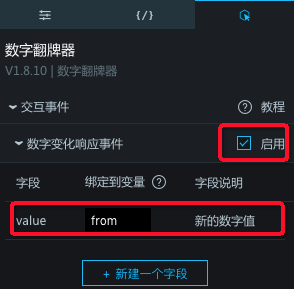
- 在交互页签,选中启用对应的响应事件,并将value绑定到变量中。
- 预览和发布。
- 单击预览图标对已编辑的视图进行预览。
- 单击发布图标即完成视图发布。
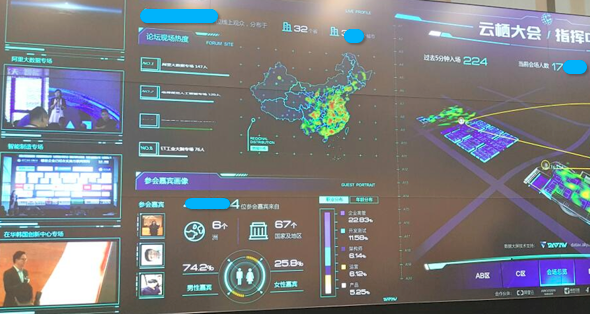
试用:Demo地址。URL中的参数from和to,您可以随意切换为任意时间。图 1. 实时大屏 
案例:调整不同统计口径下的云栖大会网站访问实时大屏
云栖大会期间有一个临时需求,需要您统计大会网站的全国各地访问量以在实时大屏上显示。此前您已配置采集全量日志数据,并且在日志服务中打开了查询分析,所以只要输入查询分析Query即可。在此过程中,需求是不断调整的,如下所列:
- 原始需求:在云栖大会的第一天,您需要统计UV(当日点击用户数量)。
您要查询所有访问日志中nginx下forward字段的数据(该字段记录访问用户的一个或多个IP,每条日志一个forward字段),通过
approx_distinct(forward)计算去重后的IP地址数量,获取从云栖大会首日零时到当前时刻的点击UV数,可以使用如下语句。* | select approx_distinct(forward) as uv - 需求第一次调整:云栖大会的第二天,需求调整为您需要统计yunqi.aliyun.com这个域名下的用户访问量数据。您可以增加一个过滤条件host进行实时查询,使用如下语句。
host:yunqi.aliyun.com | select approx_distinct(forward) as uv - 需求第二次调整:在统计过程中,您发现Nginx访问日志forward字段存在多个IP,您默认只要第一个IP。
使用如下语句。
host:yunqi.aliyun.com | select approx_distinct(split_part(forward,',',1)) as uv - 需求第三次调整:云栖大会的第三天,需求被加上限制条件,您需要剔除通过UC浏览器访问并点击该浏览器广告而来的用户访问量,统计非UC浏览器广告导流、不重复IP的全国各地用户访问量。
此时您可以加上一个过滤条件not,使用如下语句。
host:yunqi.aliyun.com not URL:uc-iflow | select approx_distinct(split_part(forward,',',1)) as uv图 2. 示例  大屏效果如下:
大屏效果如下:图 3. 大屏效果