


作者个人研发的在高并发场景下,提供的简单、稳定、可扩展的延迟消息队列框架,具有精准的定时任务和延迟队列处理功能。自开源半年多以来,已成功为十几家中小型企业提供了精准定时调度方案,经受住了生产环境的考验。为使更多童鞋受益,现给出开源框架地址:
https://github.com/sunshinelyz/mykit-delay
写在前面
说到Redis,往往更多的场景是被用作系统的缓存,说到缓存,尤其是分布式缓存系统,在实际高并发场景下,稍有不慎,就会造成缓存穿透、缓存击穿和缓存雪崩的问题。那什么是缓存穿透?什么是缓存击穿,又什么是缓存雪崩呢?它们是如何造成的?又该如何解决呢?今天,我们就一起来探讨这些问题。
缓存穿透
首先,我们来说说缓存穿透。什么是缓存穿透呢?缓存穿透问题在一定程度上与缓存命中率有关。如果我们的缓存设计的不合理,缓存的命中率非常低,那么,数据访问的绝大部分压力都会集中在后端数据库层面。
什么是缓存穿透?
如果在请求数据时,在缓存层和数据库层都没有找到符合条件的数据,也就是说,在缓存层和数据库层都没有命中数据,那么,这种情况就叫作缓存穿透。
我们可以使用下图来表示缓存穿透的现象。
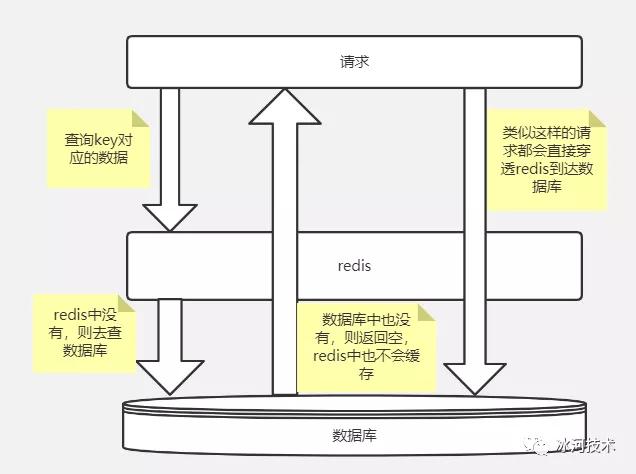
造成缓存穿透的主要原因就是:查询某个Key对应的数据,Redis缓存中没有相应的数据,则直接到数据库中查询。数据库中也不存在要查询的数据,则数据库会返回空,而Redis也不会缓存这个空结果。这就造成每次通过这样的Key去查询数据都会直接到数据库中查询,Redis不会缓存空结果。这就造成了缓存穿透的问题。
如何解决缓存穿透问题?
既然我们知道了造成缓存穿透的主要原因就是缓存中不存在相应的数据,直接到数据库查询,数据库返回空结果,缓存中不存储空结果。
那我们就自然而然的想到了第一种解决方案:就是把空对象缓存起来。当第一次从数据库中查询出来的结果为空时,我们就将这个空对象加载到缓存,并设置合理的过期时间,这样,就能够在一定程度上保障后端数据库的安全。
第二种解决缓存穿透问题的解决方案:就是使用布隆过滤器,布隆过滤器可以针对大数据量的、有规律的键值进行处理。一条记录是不是存在,本质上是一个Bool值,只需要使用 1bit 就可以存储。我们可以使用布隆过滤器将这种表示是、否等操作,压缩到一个数据结构中。比如,我们最熟悉的用户性别这种数据,就非常适合使用布隆过滤器来处理。
缓存击穿如果我们为缓存中的大部分数据设置了相同的过期时间,则到了某一时刻,缓存中的数据就会批量过期。
什么是缓存击穿?
如果缓存中的数据在某个时刻批量过期,导致大部分用户的请求都会直接落在数据库上,这种现象就叫作缓存击穿。
我们可以使用下图来表示缓存击穿的线程。
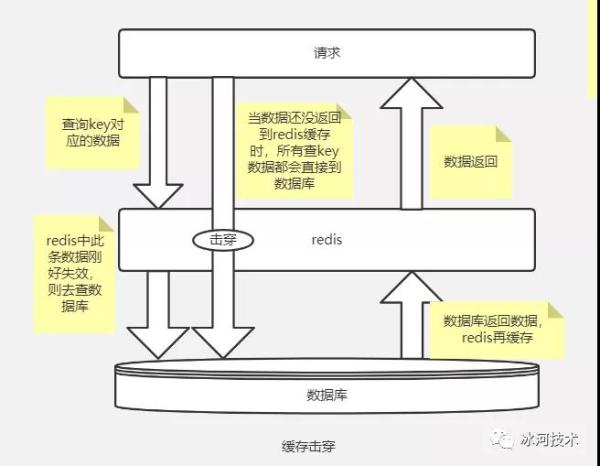
造成缓存击穿的主要原因就是:我们为缓存中的数据设置了过期时间。如果在某个时刻从数据库获取了大量的数据,并设置了相同的过期时间,这些缓存的数据就会在同一时刻失效,造成缓存击穿问题。
如何解决缓存击穿问题?
对于比较热点的数据,我们可以在缓存中设置这些数据永不过期;也可以在访问数据的时候,在缓存中更新这些数据的过期时间;如果是批量入库的缓存项,我们可以为这些缓存项分配比较合理的过期时间,避免同一时刻失效。
还有一种解决方案就是:使用分布式锁,保证对于每个Key同时只有一个线程去查询后端的服务,某个线程在查询后端服务的同时,其他线程没有获得分布式锁的权限,需要进行等待。不过在高并发场景下,这种解决方案对于分布式锁的访问压力比较大。
缓存雪崩
如果缓存系统出现故障,所有的并发流量就会直接到达数据库。
什么是缓存雪崩?
如果在某一时刻缓存集中失效,或者缓存系统出现故障,所有的并发流量就会直接到达数据库。数据存储层的调用量就会暴增,用不了多长时间,数据库就会被大流量压垮,这种级联式的服务故障,就叫作缓存雪崩。
我们可以用下图来表示缓存雪崩的现象。
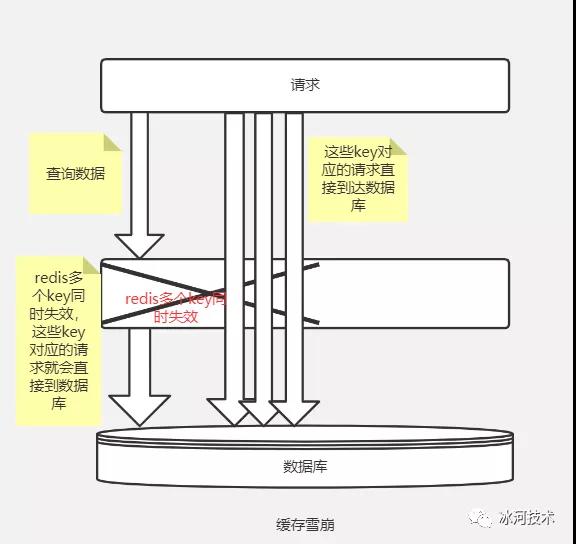
造成缓存雪崩的主要原因就是缓存集中失效,或者缓存服务发生故障,瞬间的大并发流量压垮了数据库。
如何解决缓存雪崩问题?
解决缓存雪崩问题最常用的一种方案就是保证Redis的高可用,将Redis缓存部署成高可用集群(必要时候做成异地多活),可以有效的防止缓存雪崩问题的发生。
为了缓解大并发流量,我们也可以使用限流降级的方式防止缓存雪崩。例如,在缓存失效后,通过加锁或者使用队列来控制读数据库写缓存的线程数量。具体点就是设置某些Key只允许一个线程查询数据和写缓存,其他线程等待。则能够有效的缓解大并发流量对数据库带来的巨大冲击。
另外,我们也可以通过数据预热的方式将可能大量访问的数据加载到缓存,在即将发生大并发访问的时候,提前手动触发加载不同的数据到缓存中,并为数据设置不同的过期时间,让缓存失效的时间点尽量均匀,不至于在同一时刻全部失效。
本文转载自微信公众号「冰河技术」,可以通过以下二维码关注。转载本文请联系冰河技术公众号。


麻省理工学院信息系统研究中心首席研究科学家Jeanne Ross在企业架构研究方面具有...
今天的CIO会感觉自己就像是马戏团的表演者,同时处理多个项目,还要确保没有一个...
在如今的生活中,游戏行业是受到网络攻击最为明显的行业,所以很多游戏的企业都...
爱因斯坦在给他的第一个传记作者卡尔-塞利格的信中说:我没有什么特殊的才能,我...
随着越来越多的组织转向数字化转型,他们正在迅速采用行业领先的技术。这通常从...
Julius Neudorfer是北美接入技术有限公司(NAAT)的创始人和首席技术官。北美接入...
早咯~ 转眼九月快临近尾声,新的一周又开始啦,照例来一份TOP云(zuntop.com) ...
网络攻击一直以来都是互联网行业的痛点,目前随着中小型互联网企业数量的迅速增...
1.如果眼泪可以承载悲哀,我宁愿它泛滥成海。 2.这辈子最对不起的就是自己的心...
很多人在选择VPS时都希望能够找到一个好的VPS,只不过在选择 美国私人vps https:...

