


分布式技术,在保障高可用和容错或弹性时,一般常用这两种手段:
对应英语一个是replication, 一个是partition。
复制,是把每次写入的数据多保存 N 份,这样在出故障的时候可以用来恢复,同时也可以进行读写分离,缓解读的压力。分区则是在数据超越了单台存储能力的时候,按一定规则分多台存储。分区的数据其实也是有复制的存在来保障这一个partition的数据不丢失。
复制了就可以高枕无忧了?
这都是理想情况,实际上每天都会出现机房故障,硬盘损坏,失误断电等等问题。
比如咱们自己把手机上的照片、文件等等备份到网盘,手机一清理, 欣喜腾出不少空间。某天去看的时候,网盘里一部分数据找不到了,客服告诉你某天机房备份文件的硬盘坏了,再也找不回来,你啥感觉?
你肯定愤怒的问客服为啥不再多存几份。可如果是整个硬盘所在机架都挂了呢?
和咱们搭应用的服务一样,为了应对问题,保证高可用,除了不出现单点,还得考虑实例部署在不同的机房,这样就算某个机房都出问题的时候,另一个机房也还能扛着。
对应到数据的复制和备份上,聪明的脑袋们想出了类似的思路,将备份存在不同的硬盘,不同的机架,甚至不同的机房上,像兔子一样,做到
「狡兔三窟」。 :-)
咱们一般使用网盘,云服务厂商提供的各类存储,背后都有一个分布式的存储服务,来保证应用的高可用,弹性容错等等,像咱们之前分享的神书 DDIA 里许多技术都在这些服务里有使用。
HDFS 做为Hadoop的核心存储实现,内部也支持这种更安全的多地存储备份实现。在 HDFS 中,这一技术称为 Rack Awareness。
Rack 就是机架,是在机房或者数据中心里存储着一堆的物理机,通过网络的技术来管理。
在 Hadoop 里为了在一个集群里提升网络读写 HDFS 文件的速度,管理MetaData信息的 NameNode 会根据 Rack 就近选取 DataNode去
读写。毕竟 NameNode存放着 rack id 和 DataNode 的对应信息,我们的备份数据真正写到了 DataNode里。rack id 相当于代号。
NameNode 根据 Rack id 选择一个更近的 DataNode 的过程,称之为 Rack Awareness。
默认的 Hadoop 按照所有的DataNode 属于同一个 Rack。这样就容易出问题,而打开 Awareness之后,效果类似下面这个图,
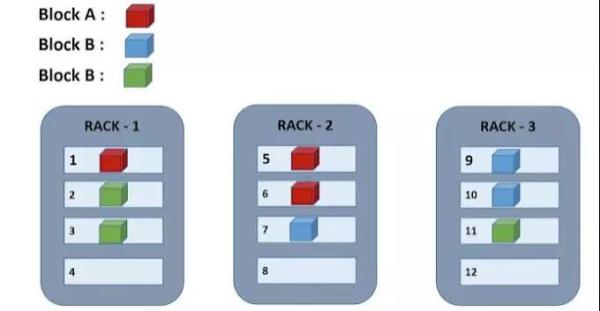
我们保存文件的时候,文件会被分成以128M为大小的 Block,之然通过NameNode来获得具体保存数据的DataNode 地址,默认是3 个备份,遵循的原则是「每个block,两个备份存在同一个 rack,第三个备份存在另一个不同的rack上」。这一规则也称为 Replica Placement Policy。
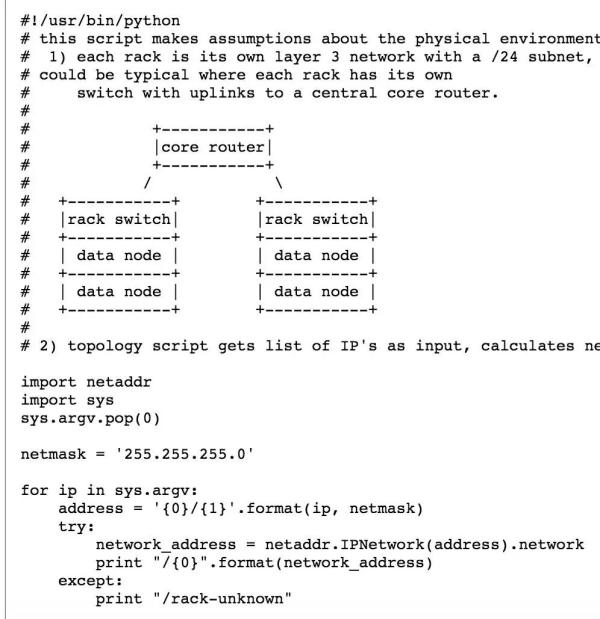
具体存放时如何确定放到哪个rack上?我们前面提到是通过 rack id 来判断的, HDFS 内部是可以通过执行一个外部脚本或者是在配置文件中指定一个 Java类来获得。
以下是官方文档给出的一个python 的例子
为什么需要 Rack Awareness?

Frost Sullivan于2020年9月28日发布的最新报告《由COVID-19引起的产业重塑》,确...
Nutanix(纳斯达克股票代码:NTNX)今天发布旨在重新定义合作伙伴关系的精英联盟合...
2020年,我们看到社会生活数字化转型步伐明显加快,从部委、央企到各大、中型企...
免备案 服务器 不限制内容 是真的吗?有很多人认为国外的服务器免备案,没有监管...
从安全专家到开发人员,再到分析师,越来越多的组织都在争夺IT人才。人们需要了...
网上平台与服务器二者是紧密联系的,如今许多公司或个人网页在经营的全过程中常...
前言 Tomcat 服务器是一个开源的轻量级Web应用服务器,在中小型系统和并发量小的...
自20世纪中叶以来,我们所见过的两个最大的社会变化就是远距离沟通和人们之间的...
笔者的一位朋友上周分享了一张有趣的图片。标题是谁在领导贵公司的数字化转型? ...
工信部网站今天发布,近两年,我国工业互联网发展已由概念普及与技术验证步入规...

