

“某些语音识别系统(ASR)的准确性可能要比之前假定的差很多。”这是最近约翰·霍普金斯大学、波兰波兹南工业大学、弗罗茨瓦夫科技大学以及初创公司Avaya的研究人员一项正在进行的研究主要发现。

这项研究对内部创建的数据集上的商业语音识别模型进行了基准测试。共同作者声称,词错误率(Word Error Rate, WER)(一种常见的语音识别性能指标)要显著高于最佳报告结果,这可能表明自然语言处理(NLP)领域存在更多待克服的问题。
据了解,目前ASR已广泛应用于诸多场景中,如电话会议、电子邮件、智能设备等。ASR模型的综合基准中,标准语料库的WER仅有2%~3%,而正是这一统计数据遭到了上述作者的质疑。他们声称,大多数ASR的交互场景都是在“类似于聊天机器人”的背景下进行的,说话人往往因为意识到跟他们的交互对象是聊天机器人,因此通常会将命令简化成结构紧凑的简短词语,而非正常的自然对话。作者基于来自1595个供应商和1261个客户的50个呼叫中心对话数据集对几套ASR系统进行了评估。其通常时间长达8.5个小时,其中2.2个小时是对话。通过测试,作者发现ASR系统的错误率基本在15%以下,这与基准测试中的2%相悖。
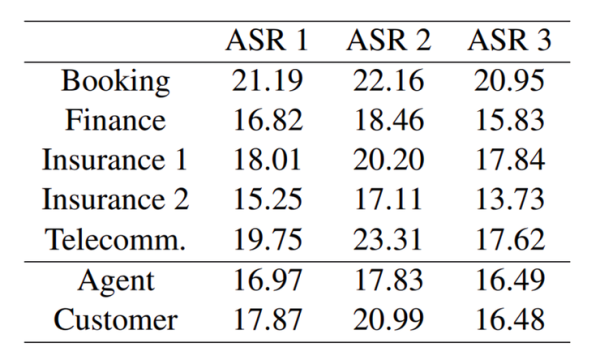
而基于保险、通信、预定等金融行业的语料库中,作者发现其WER的测试结果高达23.31%。其中,预定和通信的错误率最高,可能是因为对话涉及特定的日期、时间、订单金额、地点、产品和公司名称等。但在所有领域的测试中,其错误率均高于13.73%。
研究人员将这一问题归结为领域适应性问题——基准测试使用了单一性语料,例如Librispeech(1000小时英语有声读物录音)、WSJ(新闻口述的谈话)和Switchboard(电话交谈),这些都可能太过简单而无法真正挑战ASR系统的可靠性。
而且,尽管他们试图刻意模仿真实、自发的对话,但本质上还是受约束的,比如需要配音演员,就某一合适主题进行脚本/半脚本对话,而且正是由于配音演员的存在,几乎都不需要考虑因性别、母语因素而产生的发音问题。
作为一种补救措施,研究人员建议ASR和NLP社区收集和注释音频数据集,使其更好地与ASR系统的实际应用场景保持一致,他们还呼吁建立更具包容性的声学模型,更广泛的方言语料库,这些改变将会促进音频信号处理的技术改进。
因此,这些问题并非无法克服。“学界和工业界应该深思熟虑,考虑可以创建高质量的测试数据集。我们认为,对ASR准确性的过于乐观会损害NLP领域下游应用程序的开发。”研究人员最后表示。
本文转自雷锋网,如需转载请至雷锋网官网申请授权。

5G消息,被视为运营商5G时代重大业务创新。在运营商内部也称之为内循环背景下5G...
当前,尽管太阳能、风能等新能源崛起迅速,但传统能源重要性依然饱受关注。作为...
机器学习的快速发展,为智能语音处理奠定了坚实的理论和技术基...
日前国内公布了十四五规划和2035年远景目标纲要草案,引发各界的广泛热议,一些...
作为十三五规划的收官之年,2020年我国5G发展取得了显著成效。 根据工信部新闻发...
在新冠疫情爆发之前,远程工作更多的像是一种福利,而不是一种经营方式。现在,...
编者按:不论是设计网页还是 APP,在 UI设计的时候,确保产品的可访问性都是一件...
通过使用标准的光模块(例如CFP和QSFP28),数据中心内的100G传输成为可能。尽管它...
同样的事情,苹果又玩了一次,这真不是故意的吗? 今天有不少开发者在社交网络上...
美国微软终止对其移动操作系统Windows Mobile的支持已经有一年多的时间了。那时...


