

【51CTO.com快译】无监督机器学习和人工智能显然对组织的业务增长很有帮助,但是它们是如何工作的?人们需要了解一些关键指南,以使其市场研究、趋势预测和其他用途是有效的。
人们如今正处在数字化转型时代,只有一个不变的因素——进化。而组织采用的高科技解决方案正在引入数字化转型。因此,毫不奇怪的是,技术进步已完全取代了平凡的业务。机器学习、人工智能(AI)、无监督机器学习正在重塑组织在市场中竞争的方式。因此,人们需要了解无监督机器学习在各行业中的广泛应用。
什么是无监督机器学习?
如果人们了解深度学习,那么可能已经听说过两种机器学习方法:监督机器学习和无监督机器学习。
例如组装宜家的沙发无论采用什么方法,但其结果始终是相同的。但有些方法比其他方法更高效。通过宜家提供的组装说明书,并按照预定义步骤进行组织当然很好。但是,对于经验丰富的家具组装商来说,则可以不用采用说明书组装。
机器学习几乎与这个例子相似。如果用户标记了可以作为示例的训练数据,人们将其称为监督机器学习。但是,如果没有预先存在的标签,并且需要整理数据集,则称之为无监督机器学习。
无监督机器学习的基础知识
与监督机器学习不同,人们不用管理无监督机器学习的模型。无监督机器学习采用算法得出未标记数据集的结论。
因此,无监督机器学习算法比监督机器学习算法更加复杂,因为几乎没有信息或无法预测结果。
无监督机器学习算法用于:
(1)查找组或簇;
(2)进行密度估算;
(3)降维。
总体而言,无监督机器学习算法达到了未指定数据位的程度。
在这方面,无监督机器学习分为两组算法:聚类和降维。
聚类–数据探索
聚类分析的目的是根据相似性准则将对象分为类。聚类与分类的主要区别在于簇的列表没有明确定义,在算法操作过程中是有意义的。
聚类过程可以分为以下几个阶段:
聚类方法是无监督机器学习中使用的最简单算法之一。但是,它们可以帮助获取有价值的数据见解。
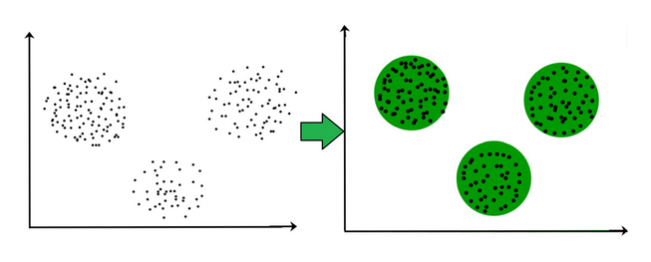
聚类是各个行业的首选分组方法:
总体而言,聚类是许多领域中用于统计数据分析的常用技术。
降维–修改数据
是否曾经尝试过获取具有3万个以上变量的数据集?这是一项艰巨的任务。缺少值、错误和不相关的信息将失去平衡,并阻碍数据解释。
降维可以最大程度减少特征数量,同时保留原始信息的有意义的属性。
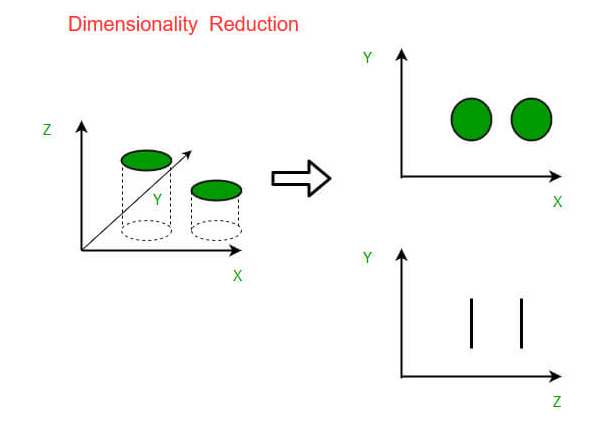
从技术的角度来看,它意味着一套减少训练数据中输入变量数量的技术。
无监督机器学习算法的实际示例
k均值聚类–文档聚类、数据挖掘
在无监督机器学习的操作中,k均值聚类算法是最常用的算法。它将对象划分为相似的簇,这些簇与属于另一个簇的对象不同。
在数据挖掘中,k-means聚类用于将观察分类为没有预定义关系的相关观察值。

除了数据挖掘之外,该工具在以下领域中是按需使用的:
隐马尔可夫模型–模式识别、生物信息学、数据分析
如今,对文本进行数字化的需求,即对将数据从纸张转换为数字的软件的需求日益增长。光学字符识别可用于识别来自多媒体文件,例如图像、音频或视频。尤其是,隐马尔可夫模型使用户可以高度准确地识别文本或符号。
通常情况下,隐马尔可夫模型(HMM)是最复杂的机器学习算法之一。它指的是一种统计模型,该模型识别可观察事件的演变并对元素进行分组。这是一条不可见的马尔可夫链,每个状态都会生成其中一个对人们可见的观测值。
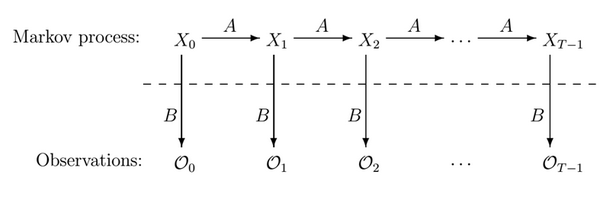
该技术在强化学习、时间模式识别、生物信息学等领域得到了广泛的应用。该算法被证明比所有竞争的方法都更有效,这使得它成为主要的处理范例。
隐马尔可夫模型(HMM)用例还包括:
DBSCAN群集-市场研究和数据分析
基于噪声的应用程序基于密度的空间聚类或DBSCAN是一种流行的数据聚类算法,已在数据挖掘和机器学习中找到了广泛的应用。根据许多点,DBSCAN将在距离方向上彼此接近元素分组。
总体而言,DBSCAN处理包括以下几个阶段:

DBSCAN的实际示例包括:
主成分分析(PCA)-人脸识别和推荐系统
主成分分析(PCA)是一种降维算法,通过减少仍然保留具有价值信息的大量变量来减少大型数据集的维数。在所有无监督机器学习算法中,主成分分析(PCA)可能不是最复杂的方法,但它无疑是最重要的方法之一。
它没有消除功能,而是以特定方式对输入变量进行分组,从而跳过了最不重要的变量,并保留了最有价值的部分。
作为一种可视化工具,主成分分析(PCA)非常适合显示过程的鸟瞰图。它也适用于以下领域:
T-SNE –非线性可视化方法
T分布随机邻域嵌入是另一种无监督的随机算法,仅用于可视化。从技术上讲,它是一种降维算法,特别适合于高维数据集的可视化。T-SNE方法的主要优点是它是非线性的,因此比PCA算法更直观。因此,T-SNE适用于各种数据集。
从音乐分析和复杂的受众细分到计算机安全研究、癌症研究和生物信息学,T-SNE已广泛用于各种应用程序的可视化。
奇异值分解(SVD)–推荐系统
奇异值分解(SVD)是一种广泛用于处理矩阵的有效方法。奇异值分解演示了矩阵SVD结构的几何形状,并有助于可视化可用数据。
该算法是用于解决各种问题(从最小二乘解到图像压缩和面部识别)的首选工具。SVD定义了突出的数据功能,使其适合于进一步处理。出色的SVD用例是一种产品推荐,可向用户显示相关的产品信息。

奇异值分解也适用于:
关联规则–市场的购物分析
关联规则是无监督机器学习的核心方法之一。最初,它用于查找超市中的典型购买模式——购物分析。
换句话说,关联规则的目的是揭示项目如何相互关联。最后,它归结为一个简单且受欢迎的市场公式,也就是购买X商品的人,也有购买Y商品的人。
因此,关联规则是一种主要的市场工具,它可以:
结语
机器学习已经成为获取可行的业务见解的强大工具。但是,由于机器学习算法千差万别,因此了解无监督机器学习算法如何成功实现部分业务的自动化至关重要。
原文标题:An Important Guide To Unsupervised Machine Learning,作者:Kayla Matthews
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】

距离2020年结束仅剩一个月,国内社会秩序正快速恢复并步入正轨,但各个领域依然...
累计建设开通5G基站超70万个,建成800个面向行业的虚拟专网,在10多个领域初步形...
评价WiFi好坏的关键点都是:快!上网快、连接快、不卡顿,是大多数人对WiFi的需求...
随着销售行业的不断发展,销售策略和技术也在不断进步,以帮助销售团队吸引新客...
明年,人工智能技术将在企业运营中更加根深蒂固。 人工智能(AI)和机器学习(ML)一...
1.我甚至一秒都没有拥有过你,却感觉失去了你一万次。 2.有这么一个人,曾经占...
根据云计算服务提供商Rackspace Technology公司最近进行的一项调查,大多数组织...
眼下,在新一代信息技术快速发展的背景下,越来越多新兴产业迎来不断崛起,其中...
今年以来,我国5G发展按下快进键,各地5G建设纷纷完成既定目标,推动了5G商用步...
对于绝大多数用户而言,几乎都在使用中频段的 5G 网络,不过 5G 网络同样需要低...

