本地部署ChatGLM-6B

今天在自己的 PC 上部署和体验了ChatGLM-6B的推理服务,简单记录一下流程。
ChatGLM-6B 简介
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
硬件环境
我的 PC 使用的是 RTX 2060 Super 显卡,具有 8GB 显存,可以满足 ChatGLM-6B 的部署要求。
环境准备
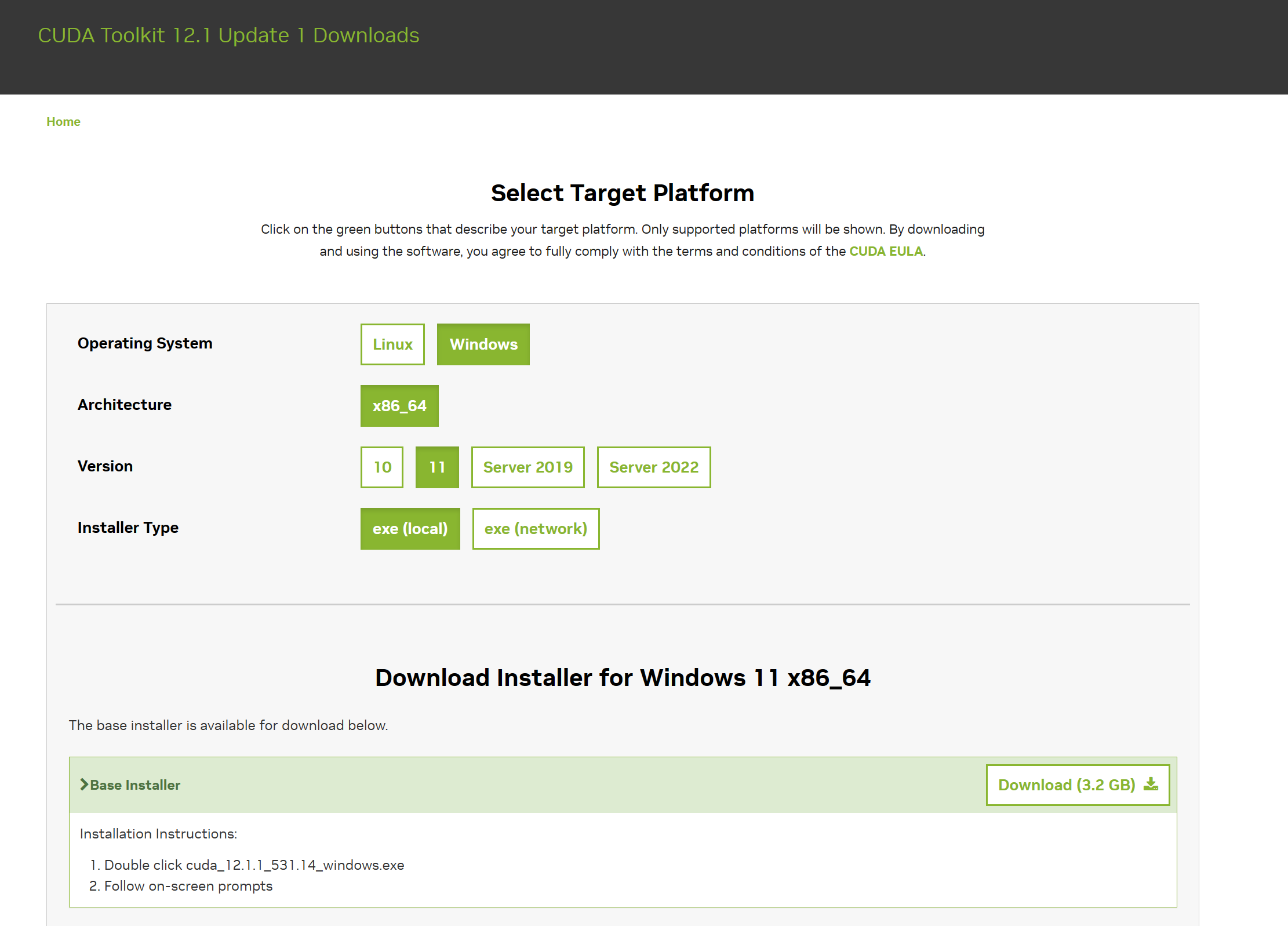
安装 cuda toolkit
前往Nvida 官网安装 cuda。
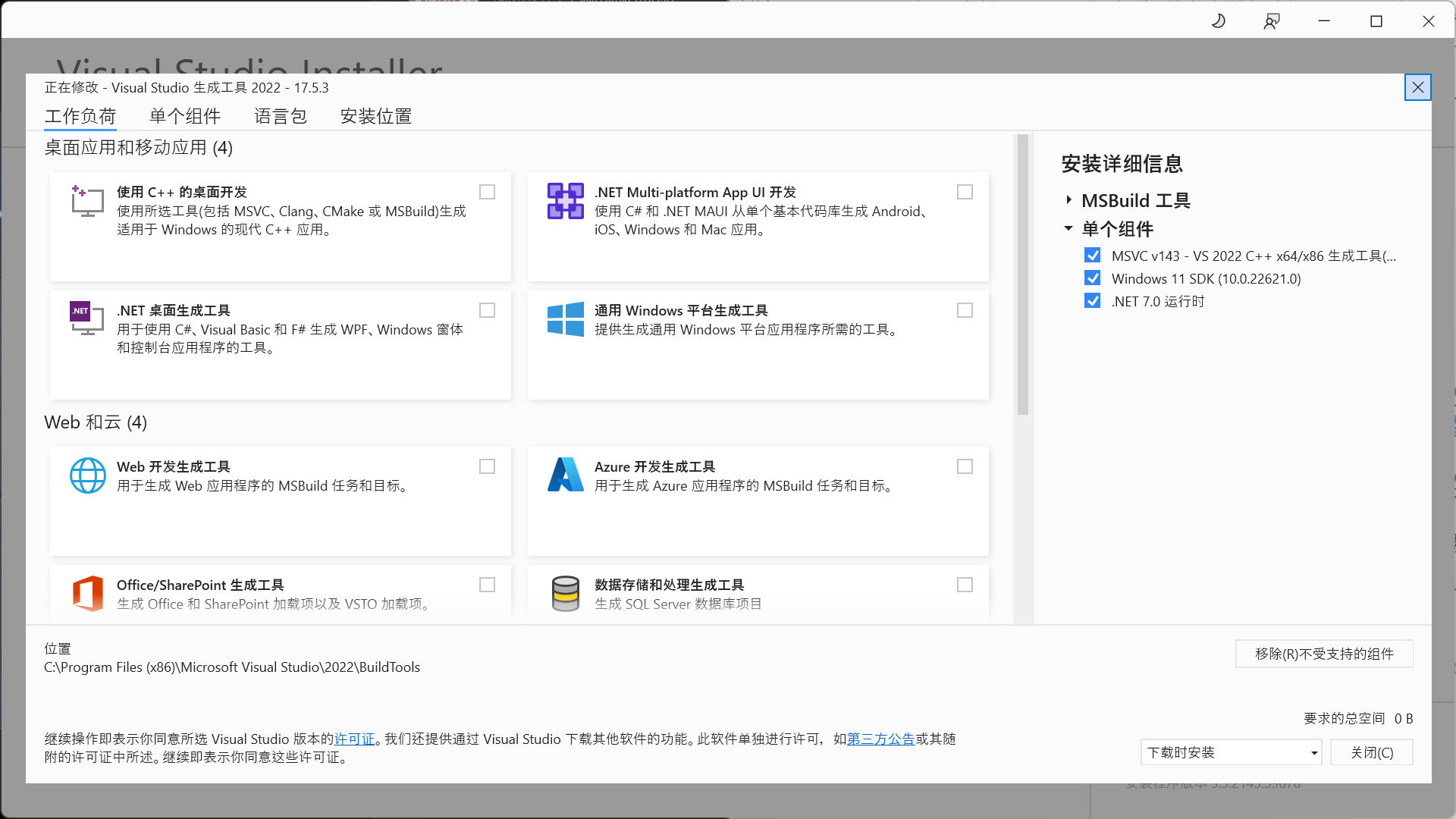
值得注意的是在 Windows 环境安装 cuda toolkit 前需要先安装 VC++构建工具,图省事的话可以只安装Visual C++生成工具,然后安装最新版本的 VC++与 Window SDK。
安装依赖
建议创建一个新的虚拟环境,防止与其他项目的依赖冲突。我习惯使用 pipenv 创建虚拟环境,不过传统的机器学习圈子应该更习惯使用 conda。
pipenv --python 3.11然后在虚拟环境中安装 PyTorch、 transformers 以及其他必要的库。 pytorch 的安装命令可以在官网找到。
pipenv shell
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
pip install transformers sentencepiece cpm-kernels mdtex2html accelerate gradio为了方便在 Visual Studio Code 中直接编写 notebook,我还安装了 ipykernel
pip install ipykernel下载 ChatGLM-6B 模型
直接通过 git clone 将 ChatGLM-6B 仓库克隆到本地。过程可能会很慢,因为有很大的模型文件需要下载。
git clone https://huggingface.co/THUDM/chatglm-6b
测试模型
创建一个新的 notebook,导入并加载模型。
from transformers import AutoModel,AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("chatglm-6b", trust_remote_code=True).quantize(4).half().cuda()
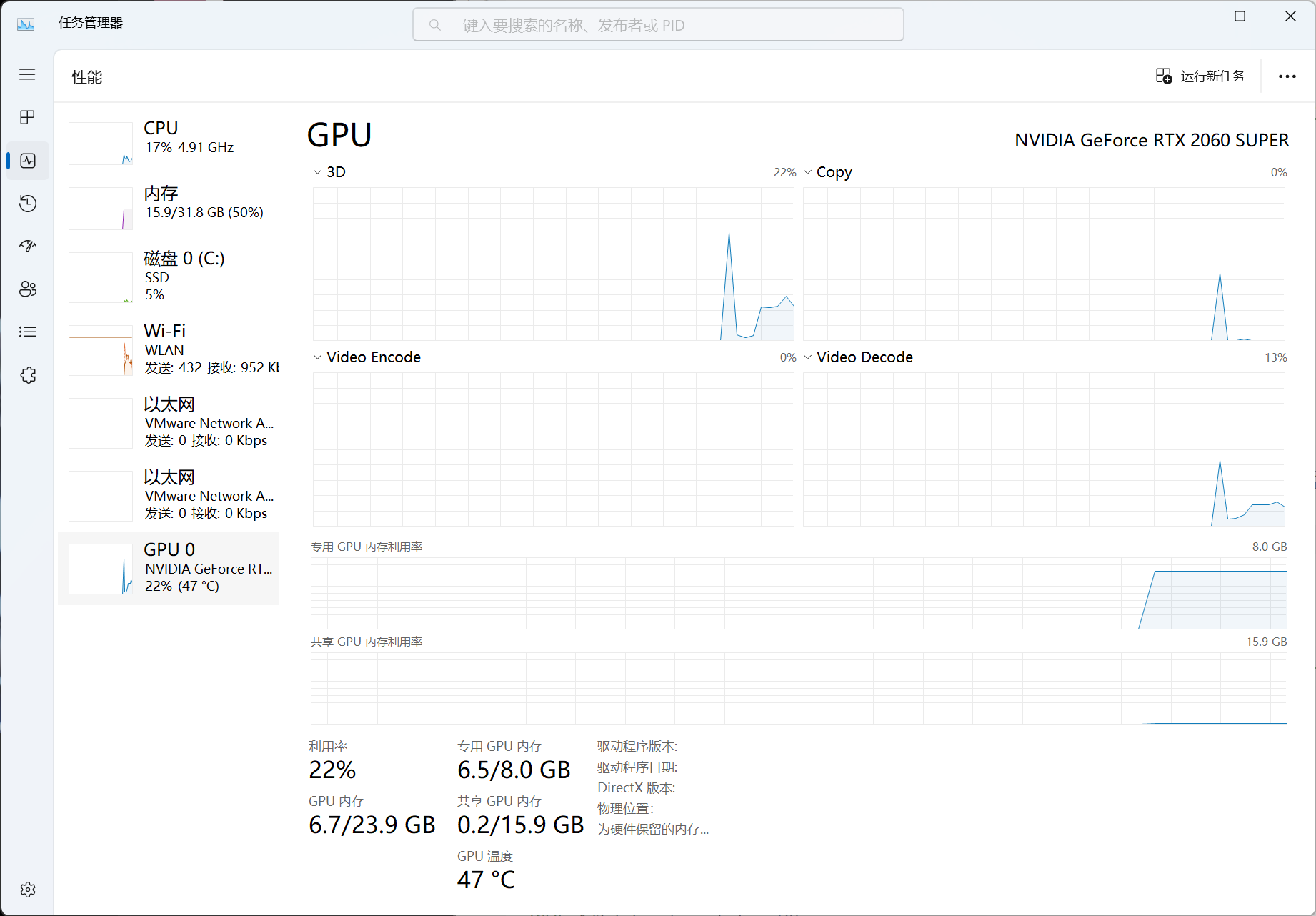
model = model.eval()我的 2060s 显卡只有 8GB 显存,这里使用了 INT4 量化级别,由于精度的降低,最终的模型效果可能会有所下降。
整个加载过程需要一分多钟,加载完成后可以看到模型占用了 6G 多的显存。
调用 model.chat()方法进行对话。


受限于机器的性能,模型的推理速度并不快,但是对话效果还是不错的。
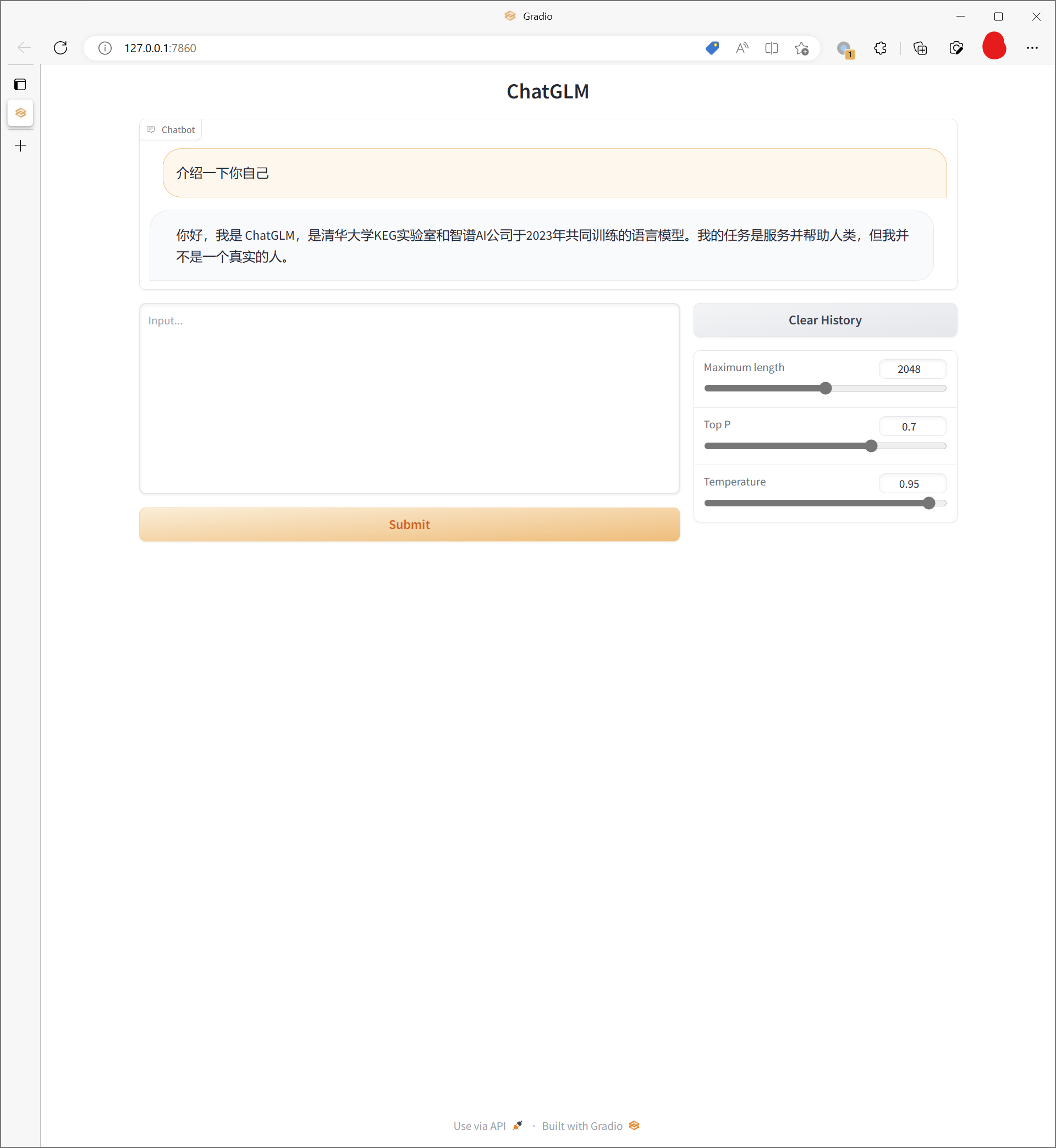
使用 web ui
我直接从官方仓库下载了web demo的代码,然后在本地运行。 需要对 web_demo.py 进行一些修改,同样使用 int4 量化级别。 然后直接运行 web_demo.py 即可。
python -m web_demo经过一段时间的模型加载后,可以通过浏览器访问 http://localhost:7860/ 。
像 openai playground 一样,可以通过调整参数来控制模型的生成效果(Maximum Length,Top P 与 Temperature)。
可以通过修改 web_demo.py 中的最后一行 lanuch 方法的 share 改为 True,将模型通过 gradio 部署到公网上,不过国内的网络环境访问 gradio 的速度可能会很慢。
另外这个 web ui 的功能还是相对有些捡漏,并且缺乏必要的安全措施,不建议直接部署到公网上。
demo.queue().launch(share=True, inbrowser=True)总结
ChatGLM 在模型尺寸和效果中取得了比较好的平衡,可以在消费级显卡上部署,同时生成的对话效果也不错。