关于图注意力网络(Graph Attention Network,GAT)知识汇总1.0
原创关于图注意力网络(Graph Attention Network,GAT)知识汇总1.0
原创
什么是图注意力网络?
图结构
图是计算机中的一种数据结构,图的基本构成单元是顶点 和边。一个图是由多个顶点和多条边所构成的,对于图中的任意两个顶点,如果两个点之间的边是有方向的边,则称为有向图,如果边没有方向,则称为无向图。
在现实生活中,无论是我们的社交网络和目前非常热门的知识图谱,其抽象的结构都是一个图结构。
图注意力网络含义
图注意力网络将注意力机制引入到基于空间域的图神经网络,与之前介绍了基于谱域的图卷积神经网络不同,图注意力网络不需要使用拉普拉斯等矩阵进行复杂的计算,仅是通过一介邻居节点的表征来更新节点特征,所以算法原理从理解上较为简单。
作为一种代表性的图卷积网络,Graph Attention Network (GAT)引入了注意力机制来实现更好的邻居聚合。 通过学习邻居的权重,GAT可以实现对邻居的加权聚合。因此,GAT不仅对于噪音邻居较为鲁棒,注意力机制也赋予了模型一定的可解释性。
图注意力神经网络,就是以图结构为基础的,在图上运行的一种神经网络结构。图注意力网络在图神经网络(GNN)的基础上引入了注意力机制。
图注意力网络的输入
在图注意力网络中,其节点的特征表示和普通的图神经网络中的节点的特征表示是类似的,都是采用embedding的方式对节点的特征表示进行向量化。对于图注意力神经网络而言,其初始的输入也是各个节点的特征组合。用公式表示就是:
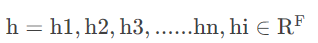
其中n表示图中节点的数量。F表示的是每一个节点的特征表示的数量。
图注意网络的输出
图注意力网络中,在输入图中节点的特征之后,经过神经网络内部的运算,特神经网络对于下一层输出仍然是一系列的特征,用公式表达是:
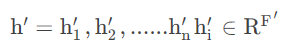
其中F‘输出的节点的特征数量,n表示节点的数量。
图注意力网络优化了图卷积神经网络的几个缺陷:
- 图卷积神经网络擅长处理transductive任务,无法完成inductive任务。图卷积神经网络进行图卷积操作时需要拉普拉斯矩阵,而拉普拉斯矩阵需要知道整个图的结构,故无法完成inductive任务,而图注意力网络仅需要一阶邻居节点的信息。(transductive指的是训练、测试使用同一个图数据,inductive是指训练、测试使用不同的图数据)
- 图卷积神经网络对于同一个节点的不同邻居在卷积操作时使用的是相同的权重 W(详见图卷积神经网络最终使用的卷积公式),而图注意力网络则可以通过注意力机制针对不同的邻居学习不同的权重。
理解图注意力机制
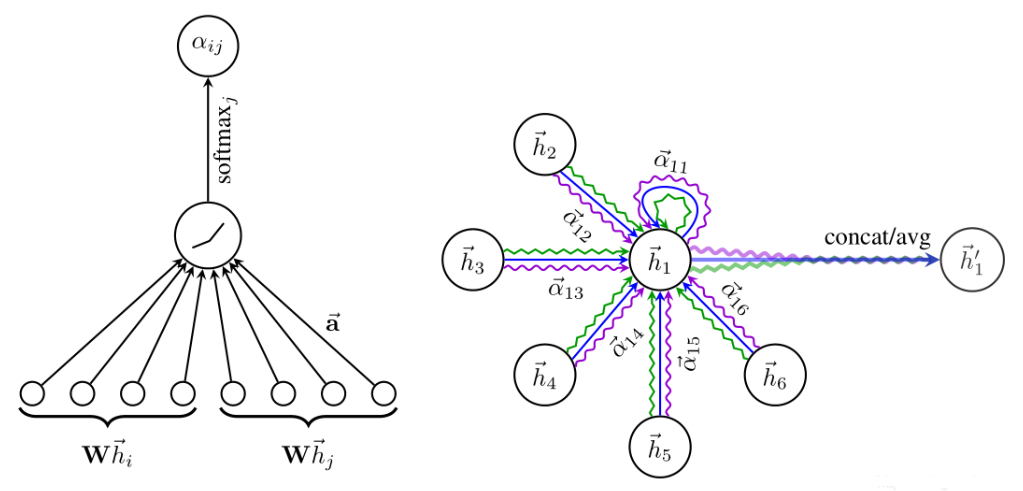
非对称的注意权重
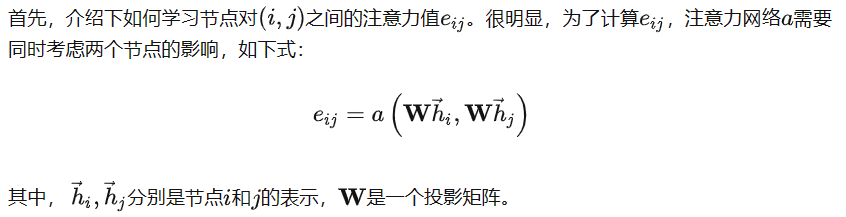


GAT的计算复杂度
下面来推导一下单头GAT模型的计算复杂度,为了与主流文献中的介绍保持一致,用 |V| 表示图中的顶点数, |E| 表示图中的边数, F 表示原始的特征维度, F′ 表示输出的特征维度。
计算复杂度是由运算中的乘法次数决定的,从上面的公式(1)-(4)可以看出,GAT的运算主要涉及如下两个乘法运算环节:

图注意力网络原理
图注意力网络是一种基于图结构数据的新型神经网络架构,它通过引入注意力机制到基于空间域的图神经网络中,以优化图卷积神经网络的一些缺陷。
与基于谱域的图卷积神经网络不同,图注意力网络不需要使用拉普拉斯等矩阵进行复杂的计算,而是通过一阶邻居节点的信息来更新节点特征。这使得算法原理从理解上较为简单。
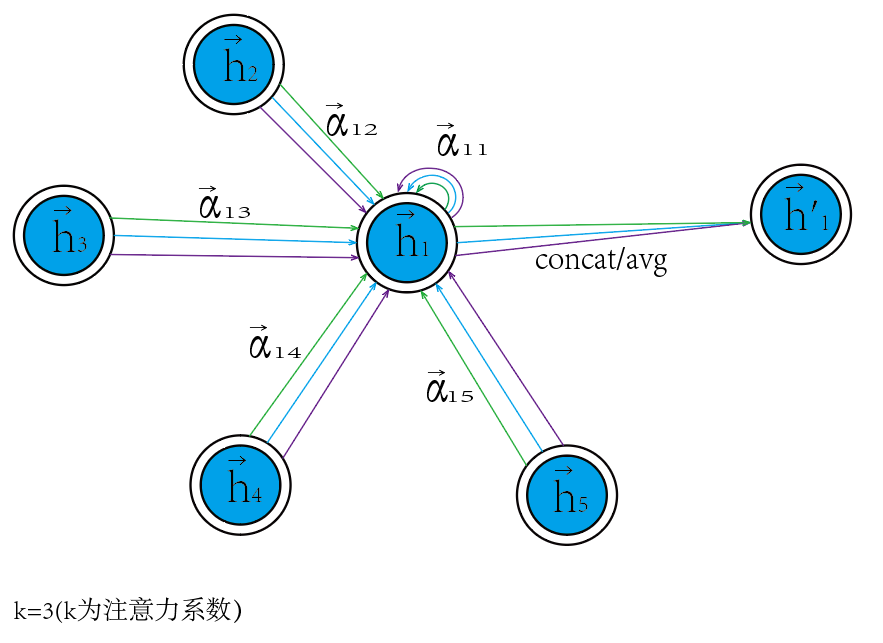
图注意力网络通过堆叠层,节点能够参与到邻居的特征中,可以(隐式地)为邻域中的不同节点指定不同的权值。这个权值矩阵就是输入的特征与输出的特征之间的关系,起到映射的作用。
通过这种方法,图注意力网络克服了基于谱的故神经网络的几个关键挑战,并使得模型适用于归纳和推理问题。
在四个数据集上实现或匹配了最先进的结果(Cora,Citeseer,Pubmed citation network,protein-protein interaction dataset)。
GAT结构图
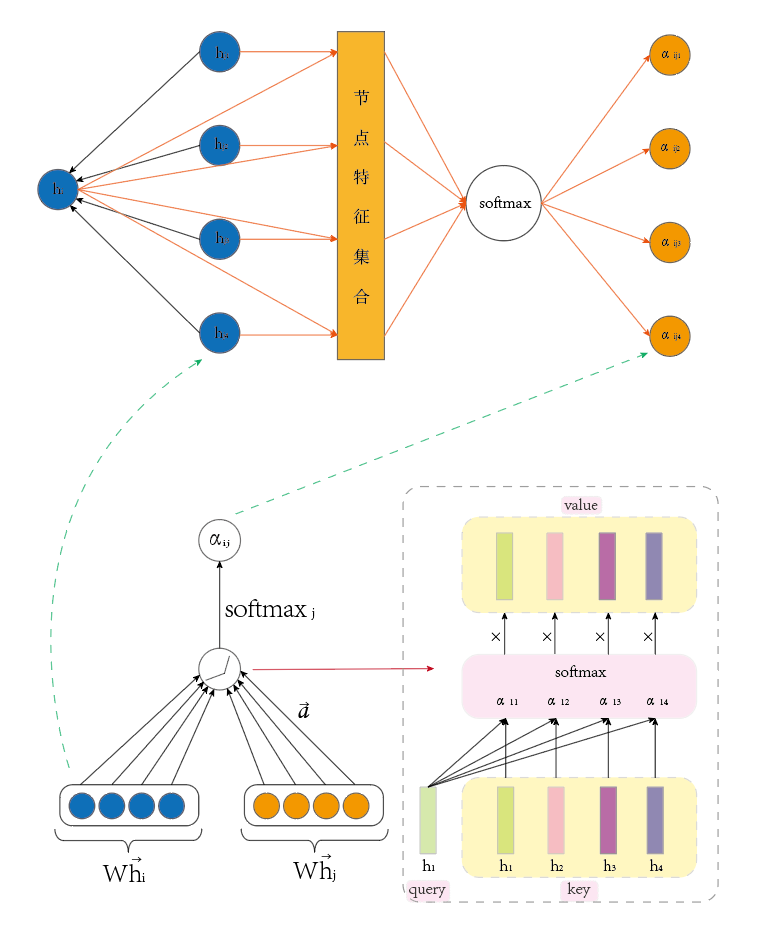
图注意力网络的结构
图注意力网络(GAT)的基本结构包括以下部分:
- 图注意力层(Graph Attentional Layer)。这是构成GAT的唯一一种层。该层的输入是多个节点的特征向量,通过注意力机制计算节点间的权重,然后将邻居节点的特征加权求和,得到更新后的节点特征表示。
- 叠加层(Stacked Layers)。通过叠加多个图注意力层,使节点能够参与其邻域的特征,以隐式地为其邻域的不同节点指定不同的权重。
GAT层代码
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
class GraphAttentionLayer(nn.Module):
"""
Simple GAT layer, similar to https://arxiv.org/abs/1710.10903
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GraphAttentionLayer, self).__init__()
self.dropout = dropout
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.concat = concat
self.W = nn.Parameter(torch.empty(size=(in_features, out_features)))
nn.init.xavier_uniform_(self.W.data, gain=1.414)
self.a = nn.Parameter(torch.empty(size=(2*out_features, 1)))
nn.init.xavier_uniform_(self.a.data, gain=1.414)
self.leakyrelu = nn.LeakyReLU(self.alpha)
def forward(self, h, adj):
Wh = torch.mm(h, self.W) # h.shape: (N, in_features), Wh.shape: (N, out_features)
a_input = self._prepare_attentional_mechanism_input(Wh)
e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))
zero_vec = -9e15*torch.ones_like(e)
attention = torch.where(adj > 0, e, zero_vec)
attention = F.softmax(attention, dim=1)
attention = F.dropout(attention, self.dropout, training=self.training)
h_prime = torch.matmul(attention, Wh)
if self.concat:
return F.elu(h_prime)
else:
return h_prime
def _prepare_attentional_mechanism_input(self, Wh):
N = Wh.size()[0] # number of nodes
# Below, two matrices are created that contain embeddings in their rows in different orders.
# (e stands for embedding)
# These are the rows of the first matrix (Wh_repeated_in_chunks):
# e1, e1, ..., e1, e2, e2, ..., e2, ..., eN, eN, ..., eN
# '-------------' -> N times '-------------' -> N times '-------------' -> N times
#
# These are the rows of the second matrix (Wh_repeated_alternating):
# e1, e2, ..., eN, e1, e2, ..., eN, ..., e1, e2, ..., eN
# '----------------------------------------------------' -> N times
#
Wh_repeated_in_chunks = Wh.repeat_interleave(N, dim=0)
Wh_repeated_alternating = Wh.repeat(N, 1)
# Wh_repeated_in_chunks.shape == Wh_repeated_alternating.shape == (N * N, out_features)
# The all_combination_matrix, created below, will look like this (|| denotes concatenation):
# e1 || e1
# e1 || e2
# e1 || e3
# ...
# e1 || eN
# e2 || e1
# e2 || e2
# e2 || e3
# ...
# e2 || eN
# ...
# eN || e1
# eN || e2
# eN || e3
# ...
# eN || eN
all_combinations_matrix = torch.cat([Wh_repeated_in_chunks, Wh_repeated_alternating], dim=1)
# all_combinations_matrix.shape == (N * N, 2 * out_features)
return all_combinations_matrix.view(N, N, 2 * self.out_features)
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'GAT模型
import torch
import torch.nn as nn
import torch.nn.functional as F
from layers import GraphAttentionLayer, SpGraphAttentionLayer
class GAT(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads):
"""Dense version of GAT."""
super(GAT, self).__init__()
self.dropout = dropout
self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)]
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention)
self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False)
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training=self.training)
x = torch.cat([att(x, adj) for att in self.attentions], dim=1)
x = F.dropout(x, self.dropout, training=self.training)
x = F.elu(self.out_att(x, adj))
return F.log_softmax(x, dim=1)对论文《Graph Attention Network》中GAT的核心代码进行简要的解读:
def attn_head(seq, out_sz, bias_mat,
activation, in_drop=0.0, coef_drop=0.0, residual=False):这里有3个比较核心的参数:
- seq 指的是输入的节点特征矩阵,大小为[num_graph, num_node, fea_size]
- out_sz指的是变换后的节点特征维度,也就是W?→后的节点表示维度。
- bias_mat是经过变换后的邻接矩阵,大小为[num_node, num_node]。
W?→
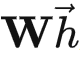
首先将原始节点特征seq进行变换得到了seq_fts。这里,作者使用卷积核大小为1的1D卷积模拟投影变换,投影变换后的维度为out_sz。注意,这里投影矩阵W是所有节点共享,所以1D卷积中的多个卷积核也是共享的。
seq_fts = tf.layers.conv1d(seq, out_sz, 1, use_bias=False)也就是说,seq_fts的大小为[num_graph, num_node, out_sz]。
回顾前面的公式展开
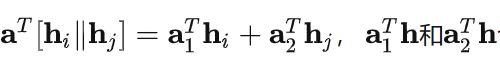
也可以认为是投影变换,只不过投影到1维表示。注意,这里节点及其邻居的投影是分开的,有两套投影参数a1,a2,对应下面两个conv1d中的参数。
f_1 = tf.layers.conv1d(seq_fts, 1, 1)
f_2 = tf.layers.conv1d(seq_fts, 1, 1)经过tf.layers.conv1d(seq_fts, 1, 1)之后的f_1和f_2维度均为[num_graph, num_node, 1]。
将f_2转置之后与f_1叠加,通过广播得到的大小为[num_graph, num_node, num_node]的logits,就是一个注意力矩阵,
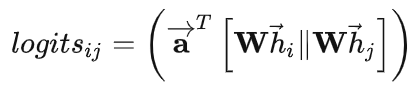
按照GAT的公式,我们只要对logits进行softmax归一化就可以拿到注意力权重α_ij,也就是代码里的coefs。但是,这里为什么会多一项bias_mat呢?
coefs = tf.nn.softmax(tf.nn.leaky_relu(logits) + bias_mat)因为的logits存储了任意两个节点之间的注意力值,但是,归一化只需要对每个节点的所有邻居的注意力进行(下式标红的部分)。所以,引入了bias_mat就是将softmax的归一化对象约束在每个节点的邻居上,如下式的红色部分。
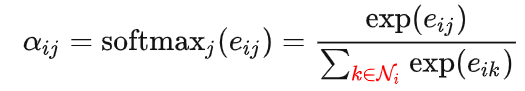
那么,bias_mat是如何实现的呢?直接的想法就是只含有0,1的邻接矩阵与注意力矩阵相乘,从而对邻居进行mask。但是,直接用0,1mask会有问题。
假设注意力权值[1.2, 0.3, 2.4]经过[0,1,1]的乘法mask得到[0, 0.3, 2.4],再送入到softmax归一化,实际上变为:
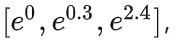
这里本应该被mask掉的1.2变成了e^0=1,还是参与到了归一化的过程中。
作者这里用一个很大的负数,如?1e9,将原始邻居矩阵进行下面的变换。
def adj_to_bias(adj, sizes, nhood=1):
...
...
return -1e9 * (1.0 - mt)然后,将bias_mat和注意力矩阵相加,进而将非节点邻居进行mask。
例如,[1.2, 0.3, 2.4]经过[?1e9,0,0]的加法mask得到[1.2?1e9,0.3,2.4]。这样softmax就达到了我们的目的。
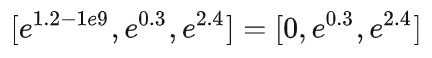
因为较大的负数e^较大的负数=0。最后,将mask之后的注意力矩阵coefs与变换后的特征矩阵seq_fts相乘,即可得到更新后的节点表示vals。
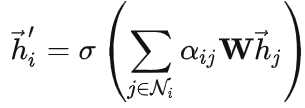
vals = tf.matmul(coefs, seq_fts)代码中的train_mask,val_mask,test_mask
train_mask,val_mask,test_mask是为了划分训练,验证和测试的。因为AX一次会得到所有节点的表示,但是计算loss只在部分节点上进行(训练集)。
与GCN的联系与区别
本质上而言:GCN与GAT都是将邻居顶点的特征聚合到中心顶点上(一种aggregate运算),利用graph上的local stationary学习新的顶点特征表达。不同的是GCN利用了拉普拉斯矩阵,GAT利用attention系数。一定程度上而言,GAT会更强,因为 顶点特征之间的相关性被更好地融入到模型中。
图注意力网络优点
图注意力网络(GAT)是作者对图卷积网络(GCN)的改进。它的主要创新点在于利用了注意力机制(Attention Mechanism)来自动的学习和优化节点间的连接关系,这一作法有以下几个优点:
克服了GCN只适用于直推式学习的缺陷(在训练期间需要测试时的图数据),可以应用于我们熟悉的归纳式学习任务(在训练期间不需要测试时的图数据)。
使用注意力权重代替了原先非0即1的节点连接关系,即两个节点间的关系可以被优化为连续数值,从而获得更丰富的表达
由于attention值的计算是可以在节点间并行进行的,网络的计算相当高效。
图注意力网络不足
1、没有充分使用边的特征:GAT没有充分利用边的信息,只利用到了连接性,即在邻接矩阵中值为1表示有连接,值为0,表示不相连。然而,图中的边通常具有很多信息,例如强度、类型等。并且不仅仅是二进制的变量,可能是连续的、多维的。 GCN能够利用一维的边的特征,也就是边的权重,但是仅限于使用一维的边的特征。
2、原始邻居矩阵可能存在噪声:每个GAT或GCN层根据作为输入的原始邻接矩阵过滤节点特征。原始邻接矩阵可能存在噪声且不是最优的,这将限制滤波操作的有效性。
参考资料
图神经网络13-图注意力模型GAT网络详解 - 知乎 (zhihu.com)
[1710.10903] Graph Attention Networks (arxiv.org)
DeepLearning | 图注意力网络Graph Attention Network(GAT)论文、模型、代码解析_图注意力网络gan-CSDN博客
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。