ATAC-seq分析:比对(3)
原创
1. 质控
在比对之前,我们建议花一些时间查看 FASTQ 文件。一些基本的 QC 检查可以帮助我们了解您的测序是否存在任何偏差,例如读取质量的意外下降或非随机 GC 内容。
2. Greenleaf
在本节中,我们将稍微处理一下 Greenleaf 数据集。
我们将处理从 FASTQ 到 BAM 的 Greenleaf 数据的一个样本,以允许我们审查 ATACseq 数据的一些特征,并创建一些处理过的文件以供审查和进一步分析。
3.参考基因组
首先,我们需要创建一个参考基因组来比对我们的 ATACseq 数据。我们可以创建一个 FASTA 文件用于从 Bioconductor BSGenome 对象进行比对。
这次我们正在处理人类数据,因此我们将使用 BSgenome.Hsapiens.UCSC.hg19 库构建 hg19 基因组。
library(BSgenome.Hsapiens.UCSC.hg19)
mainChromosomes <- paste0("chr",c(1:21,"X","Y","M"))
mainChrSeq <- lapply(mainChromosomes,
function(x)BSgenome.Hsapiens.UCSC.hg19[[x]])
names(mainChrSeq) <- mainChromosomes
mainChrSeqSet <- DNAStringSet(mainChrSeq)
writeXStringSet(mainChrSeqSet,
"BSgenome.Hsapiens.UCSC.hg19.mainChrs.fa")4. Rsubread
对于 Rsubread,我们必须在 Rsubread 的对齐步骤之前建立我们的索引。
这里我额外指定参数 indexSplit 为 TRUE 并结合 memory 参数设置为 1000 (1000MB) 以控制 Rsubread 对齐步骤中的内存使用。
library(Rsubread)
buildindex("BSgenome.Hsapiens.UCSC.hg19.mainChrs",
"BSgenome.Hsapiens.UCSC.hg19.mainChrs.fa",
indexSplit = TRUE,
memory = 1000)5. 比对准备
现在我们有了索引,我们可以比对我们的 ATACseq 读数。由于 ATACseq 数据通常是双端测序,我们需要对比对步骤进行一些小的调整。
双端测序数据通常以两个文件的形式出现,通常在文件名中带有 _1 和 _2 或 _R1 和 _R2 来表示一个文件是成对的数字。
read1 <- "ATAC_Data/ATAC_FQs/SRR891269_1.fastq.gz"
read2 <- "ATAC_Data/ATAC_FQs/SRR891269_2.fastq.gz"我们的两个匹配的双端读取文件将(通常)包含相同数量的读取,并且两个文件中的读取顺序相同。读取名称将跨文件匹配以进行配对读取,但名称中的 1 或 2 除外,以表示读取是一对中的第一个还是第二个。
require(ShortRead)
read1 <- readFastq("data/ATACSample_r1.fastq.gz")
read2 <- readFastq("data/ATACSample_r2.fastq.gz")
id(read1)[1:2]
id(read2)[1:2]
成对读数之间的距离在 ATACseq 中很重要,它使我们能够区分读数映射与分别指示信号的无核小体和核小体部分的短或长片段。在比对步骤之后,插入大小为我们提供了 read1 和 read2 起点之间的总距离。
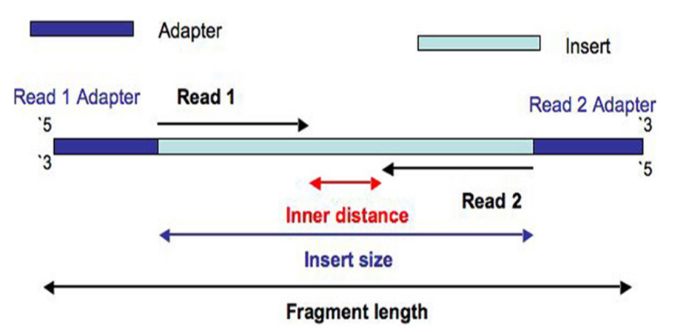
我们可以对 DNA 使用标准比对(对于 ChIPseq),但我们增加了最大允许片段长度以捕获代表多核小体信号的长片段。
此处设置的最大允许片段长度基于 Greenleaf 研究中使用的参数。为了控制允许的最大片段长度,我将 maxFragLength 参数设置为 2000。我还将 unique 参数设置为 TRUE 以仅包括唯一映射读取。
align("BSgenome.Hsapiens.UCSC.hg19.mainChrs",
readfile1=read1,readfile2=read2,
output_file = "ATAC_50K_2.bam",
nthreads=2,type=1,
unique=TRUE,maxFragLength = 2000)要使用 Rbowtie2,我们还必须在比对之前构建我们的索引。在这里,我们使用 bowtie2_build() 函数指定我们的 FASTA 文件的参数来构建索引和所需的索引名称。
library(Rbowtie2)
bowtie2_build(references="BSgenome.Hsapiens.UCSC.hg19.mainChrs.fa",
bt2Index="BSgenome.Hsapiens.UCSC.hg19.mainChrs_bowtie2")6. 解压
一旦我们有了索引,我们必须使用 gunzip() 函数解压缩我们的 FASTQ 文件。
gunzip("ATAC_Data/ATAC_FQs/SRR891269_1.fastq.gz")
gunzip("ATAC_Data/ATAC_FQs/SRR891269_2.fastq.gz")7. 比对
现在我们可以使用 bowtie2() 函数将我们的 FASTQ 与基因组对齐,指定我们的 read1 和 read2 到 seq1 和 seq2 参数。最后,我们可以使用 asBam() 函数将输出的 SAM 文件转换为 BAM 文件。
注意NOTE: SAM 和未压缩的FASTQ 文件会占用大量磁盘空间。完成后,最好重新压缩 FASTQ 并使用 unlink() 函数删除 SAM 文件。
library(Rsamtools)
bowtie2(bt2Index = "BSgenome.Hsapiens.UCSC.hg19.mainChrs_bowtie2",
samOutput = "ATAC_50K_2_bowtie2.sam",
seq1 = "ATAC_Data/ATAC_FQs/SRR891269_1.fastq",
seq1 = "ATAC_Data/ATAC_FQs/SRR891269_2.fastq"
)
asBam("ATAC_50K_2_bowtie2.sam")8. 排序
比对后,我们希望对 BAM 文件进行排序和索引,以便与外部工具一起使用。首先,我们按序列顺序对比对数据进行排序(此处不是 Read Name)。然后我们索引我们的文件,允许其他程序(例如 IGV、Samtools)和我们将使用的 R/Bioconductor 包快速访问特定的基因组位置。
library(Rsamtools)
sortedBAM <- file.path(dirname(outBAM),
paste0("Sorted_",basename(outBAM))
)
sortBam(outBAM,gsub("\\.bam","",basename(sortedBAM)))
indexBam(sortedBAM)9. 结果探索
在 ATACseq 中,我们将要检查映射读取跨染色体的分布。我们可以使用 idxstatsBam() 函数检查每条染色体上映射读取的数量。已知 ATACseq 在线粒体染色体上具有高信号,因此我们可以在此处进行检查。
library(Rsamtools)
mappedReads <- idxstatsBam(sortedBAM)我们现在可以使用映射的读取数据框来制作跨染色体读取的条形图。在这个例子中,我们看到了线粒体基因组映射率很高的情况。
library(ggplot2)
ggplot(mappedReads, aes(seqnames, mapped, fill = seqnames)) + geom_bar(stat = "identity") +
coord_flip()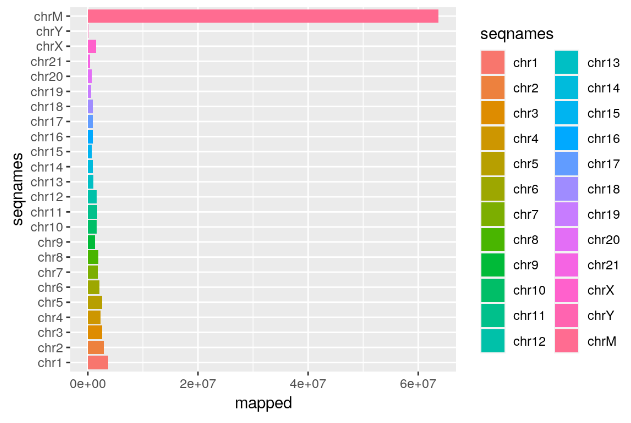
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。