Hello Edge: Keyword Spotting on Microcontrollers
Hello Edge: Keyword Spotting on Microcontrollers

- Hello Edge: Keyword Spotting on Microcontrollers -
Keyword spotting (KWS) is a critical component for enabling speech based user interactions on smart devices. It requires real-time response and high accuracy forgood user experience.
Recently, neural networks have become an attractive choicefor KWS architecture because of their superior accuracy compared to traditionalspeech processing algorithms.
Due to its always-on nature, KWS application hashighly constrained power budget and typically runs on tiny microcontrollers withlimited memory and compute capability.
The design of neural network architecturefor KWS must consider these constraints. In this work, we perform neural networkarchitecture evaluation and exploration for running KWS on resource-constrainedmicrocontrollers.
We train various neural network architectures for keywordspotting published in literature to compare their accuracy and memory/compute requirements.
We show that it is possible to optimize these neural network architectures to fit within the memory and compute constraints of microcontrollers withoutsacrificing accuracy. We further explore the depthwise separable convolutional neural network (DS-CNN) and compare it against other neural network architectures.DS-CNN achieves an accuracy of 95.4%, which is ~10% higher than the DNNmodel with similar number of parameters.
Introduction
Deep learning algorithms have evolved to a stage where they have surpassed human accuracies in avariety of cognitive tasks including image classification and conversational speech recognition.
Motivated by the recent breakthroughs in deep learning based speech recognition technologies,speech is increasingly becoming a more natural way to interact with consumer electronic devices, forexample, Amazon Echo, Google Home and smart phones.
However, always-on speech recognitionis not energy-efficient and may also cause network congestion to transmit continuous audio streamfrom billions of these devices to the cloud. Furthermore, such a cloud based solution adds latencyto the application, which hurts user experience.
There are also privacy concerns when audio iscontinuously transmitted to the cloud. To mitigate these concerns, the devices first detect predefinedkeyword(s) such as "Alexa", "Ok Google", "Hey Siri", etc., which is commonly known as keywordspotting (KWS). Detection of keyword wakes up the device and then activates the full scale speechrecognition either on device or in the cloud.
In some applications, the sequence of keywordscan be used as voice commands to a smart device such as a voice-enabled light bulb. Since KWSsystem is always-on, it should have very low power consumption to maximize battery life.
On theother hand, the KWS system should detect the keywords with high accuracy and low latency, forbest user experience.
These conflicting system requirements make KWS an active area of researchever since its inception over 50 years ago. Recently, with the renaissance of artificial neuralnetworks in the form of deep learning algorithms, neural network (NN) based KWS has become verypopular.
Low power consumption requirement for keyword spotting systems make microcontrollers an obviouschoice for deploying KWS in an always-on system.
Microcontrollers are low-cost energy-efficientprocessors that are ubiquitous in our everyday life with their presence in a variety of devices rangingfrom home appliances, automobiles and consumer electronics to wearables.
However, deployment ofneural network based KWS on microcontrollers comes with following challenges:
- Limited memory footprint: Typical microcontroller systems have only tens to few hundred KB ofmemory available. The entire neural network model, including input/output, weights and activations,has to fit within this small memory budget.
- Limited compute resources: Since KWS is always-on, the real-time requirement limits the totalnumber of operations per neural network inference.
These microcontroller resource constraints in conjunction with the high accuracy and low latencyrequirements of KWS call for a resource-constrained neural network architecture exploration to findlean neural network structures suitable for KWS, which is the primary focus of our work. The maincontributions of this work are as follows:
- We first train the popular KWS neural net models from the literature on Googlespeech commands dataset and compare them in terms of accuracy, memory footprintand number of operations per inference.
- In addition, we implement a new KWS model using depth-wise separable convolutions andpoint-wise convolutions, inspired by the success of resource-efficient MobileNet [10] incomputer vision. This model outperforms the other prior models in all aspects of accuracy,model size and number of operations.
- Finally, we perform resource-constrained neural network architecture exploration and presentcomprehensive comparison of different network architectures within a set of compute andmemory constraints of typical microcontrollers. The code, model definitions and pretrainedmodels are available at https://github.com/ARM-software/ML-KWS-for-MCU.
Background
Keyword Spotting (KWS) System
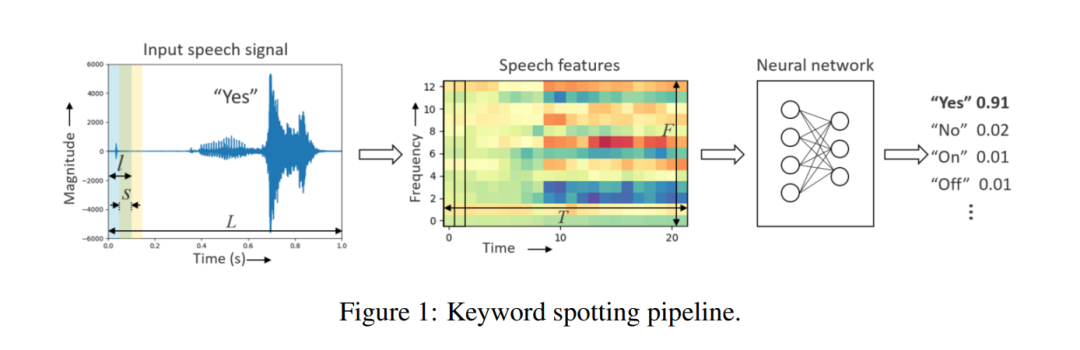
A typical KWS system consists of a feature extractor and a neural network based classifier as shownin Fig. 1. First, the input speech signal of length L is framed into overlapping frames of length lwith a stride s, giving a total of T =L?ls + 1 frames. From each frame, F speech features areextracted, generating a total of T × F features for the entire input speech signal of length L.
Log-melfilter bank energies (LFBE) and Mel-frequency cepstral coefficients (MFCC) are the commonlyused human-engineered speech features in deep learning based speech-recognition, that are adaptedfrom traditional speech processing techniques.
Feature extraction using LFBE or MFCC involvestranslating the time-domain speech signal into a set of frequency-domain spectral coefficients, whichenables dimensionality compression of the input signal.
The extracted speech feature matrix is fedinto a classifier module, which generates the probabilities for the output classes. In a real-worldscenario where keywords need to be identified from a continuous audio stream, a posterior handlingmodule averages the output probabilities of each output class over a period of time, improving theoverall confidence of the prediction.
Traditional speech recognition technologies for KWS use Hidden Markov Models (HMMs) andViterbi decoding. While these approaches achieve reasonable accuracies, they are hardto train and are computationally expensive during inference.
Other techniques explored for KWSinclude discriminative models adopting a large-margin problem formulation or recurrent neuralnetworks (RNN). Although these methods significantly outperform HMM based KWS in termsof accuracy, they suffer from large detection latency.
Traditional speech recognition technologies for KWS use Hidden Markov Models (HMMs) andViterbi decoding. While these approaches achieve reasonable accuracies, they are hardto train and are computationally expensive during inference.
Other techniques explored for KWSinclude discriminative models adopting a large-margin problem formulation or recurrent neuralnetworks (RNN). Although these methods significantly outperform HMM based KWS in termsof accuracy, they suffer from large detection latency.
KWS models using deep neural networks (DNN)based on fully-connected layers with rectified linear unit (ReLU) activation functions are introduced, which outperforms the HMM models with a very small detection latency.
Furthermore,low-rank approximation techniques are used to compress the DNN model weights achieving similaraccuracy with less hardware resources. The main drawback of DNNs is that they ignorethe local temporal and spectral correlation in the input speech features.
In order to exploit thesecorrelations, different variants of convolutional neural network (CNN) based KWS are explored, which demonstrate higher accuracy than DNNs.
The drawback of CNNs in modeling timevarying signals (e.g. speech) is that they ignore long term temporal dependencies. Combining thestrengths of CNNs and RNNs, convolutional recurrent neural network based KWS is investigated and demonstrate the robustness of the model to noise.
While all the prior KWS neural networksare trained with cross entropy loss function, a max-pooling based loss function for training KWSmodel with long short-term memory (LSTM) is proposed, which achieves better accuracy thanthe DNNs and LSTMs trained with cross entropy loss.
Although many neural network models for KWS are presented in literature, it is difficult to make afair comparison between them as they are all trained and evaluated on different proprietary datasets(e.g. "TalkType" dataset, "Alexa" dataset, etc.) with different input speech featuresand audio duration.
Also, the primary focus of prior research has been to maximize the accuracywith a small memory footprint model, without explicit constraints of underlying hardware, such aslimits on number of operations per inference.
In contrast, this work is more hardware-centric andtargeted towards neural network architectures that maximize accuracy on microcontroller devices.The constraints on memory and compute significantly limit the neural network parameters and thenumber of operations.
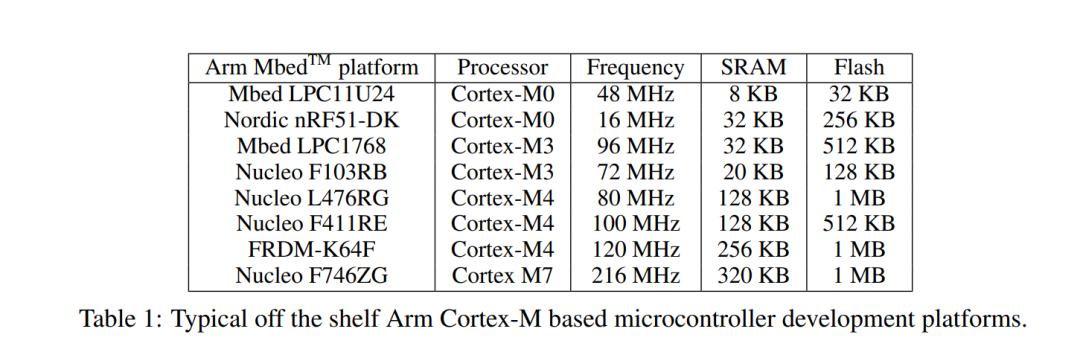
Microcontroller Systems
A typical microcontroller system consists of a processor core, an on-chip SRAM block and anon-chip embedded flash.
Table 1 shows some commercially available microcontroller developmentboards with Arm Cortex-M processor cores with different compute capabilities running at differentfrequencies (16 MHz to 216 MHz), consisting of a wide range of on-chip memory (SRAM: 8 KB to320 KB; Flash: 128 KB to 1 MB).
The program binary, usually preloaded into the non-volatile flash,is loaded into the SRAM at startup and the processor runs the program with the SRAM as the maindata memory. Therefore, the size of the SRAM limits the size of memory that the software can use.
Other than the memory footprint, performance (i.e., operations per second) is also a constraining factorfor running neural networks on microcontrollers.
Most microcontrollers are designed for embeddedapplications with low cost and high energy-efficiency as the primary targets, and do not have highthroughput for compute-intensive workloads such as neural networks.
Some microcontrollers haveintegrated DSP instructions that can be useful for running neural network workloads. For example,Cortex-M4 and Cortex-M7 have integrated SIMD and MAC instructions that can be used to acceleratelow-precision computation in neural networks.
Neural Network Architectures for KWS
This section gives an overview of all the different neural network architectures explored in thiswork including the deep neural network (DNN), convolutional neural network (CNN), recurrentneural network (RNN), convolutional recurrent neural network (CRNN) and depthwise separableconvolutional neural network (DS-CNN).
Deep Neural Network (DNN)
The DNN is a standard feed-forward neural network made of a stack of fully-connected layers andnon-linear activation layers. The input to the DNN is the flattened feature matrix, which feeds into astack of d hidden fully-connected layers each with n neurons. Typically, each fully-connected layeris followed by a rectified linear unit (ReLU) based activation function. At the output is a linear layerfollowed by a softmax layer generating the output probabilities of the k keywords, which are used forfurther posterior handling.
Convolutional Neural Network (CNN)
One main drawback of DNN based KWS is that they fail to efficiently model the local temporaland spectral correlation in the speech features.
CNNs exploit this correlation by treating the inputtime-domain and spectral-domain features as an image and performing 2-D convolution operationsover it.
The convolution layers are typically followed by batch normalization, ReLU basedactivation functions and optional max/average pooling layers, which reduce the dimensionality ofthe features. During inference, the parameters of batch normalization can be folded into the weightsof the convolution layers. In some cases, a linear low-rank layer, which is simply a fully-connectedlayer without non-linear activation, is added in between the convolution layers and dense layers forthe purpose of reducing parameters and accelerating training .
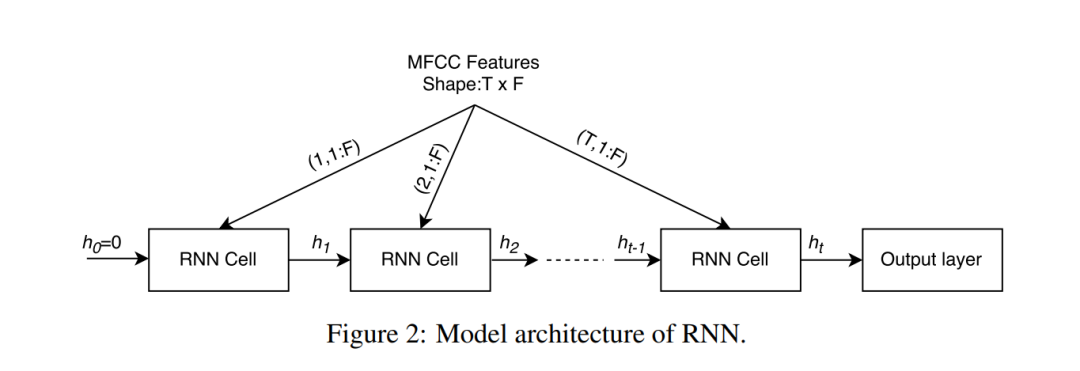
Recurrent Neural Network (RNN)
RNNs have shown superior performance in many sequence modeling tasks, especially speech recognition [20], language modeling [21], translation [22], etc. RNNs not only exploit the temporal relationbetween the input signal, but also capture the long-term dependencies using "gating" mechanism
Convolutional Recurrent Neural Network (CRNN)
Convolution recurrent neural network is a hybrid of CNN and RNN, which takes advantages ofboth. It exploits the local temporal/spatial correlation using convolution layers and global temporaldependencies in the speech features using recurrent layers. As shown in Fig. 3, a CRNN model
Depthwise Separable Convolutional Neural Network (DS-CNN)
Recently, depthwise separable convolution has been proposed as an efficient alternative to the standard3-D convolution operation [29] and has been used to achieve compact network architectures in thearea of computer vision
Experiments and ResultsConclusions
Hardware optimized neural network architecture is key to get efficient results on memory and computeconstrained microcontrollers.
We trained various neural network architectures for keyword spottingpublished in literature on Google speech commands dataset to compare their accuracy and memoryrequirements vs. operations per inference, from the perspective of deployment on microcontrollersystems.
We quantized representative trained 32-bit floating-point KWS models into 8-bit fixed-pointversions demonstrating that these models can easily be quantized for deployment without any lossin accuracy, even without retraining. Furthermore, we trained a new KWS model using depthwiseseparable convolution layers, inspired from MobileNet.
Based on typical microcontroller systems,we derived three sets of memory/compute constraints for the neural networks and performed resourceconstrained neural network architecture exploration to find the best networks achieving maximumaccuracy within these constraints.
In all three sets of memory/compute constraints, depthwiseseparable CNN model (DS-CNN) achieves the best accuracies of 94.4%, 94.9% and 95.4% comparedto the other model architectures within those constraints, which shows good scalability of the DS-CNNmodel.
The code, model definitions and pretrained models are available at https://github.com/ARMsoftware/ML-KWS-for-MCU.
本文分享自 SmellLikeAISpirit 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与?腾讯云自媒体分享计划? ,欢迎热爱写作的你一起参与!