R语言回归、anova方差分析、相关性分析 《精品购物指南》调研数据可视化|附代码数据
原创R语言回归、anova方差分析、相关性分析 《精品购物指南》调研数据可视化|附代码数据
原创
全文链接:http://tecdat.cn/?p=30990
最近我们被客户要求撰写关于回归、anova方差分析、相关性分析的研究报告,包括一些图形和统计输出。
在分析时,我们向客户演示了用R语言回归、anova方差分析、相关性分析可以提供的内容
第一节 研究背景与目的
《精品购物指南》是中国本土经营规模最大、最具影响力的时尚媒体品牌,1999年《精品购物指南》即进入全国报业广告十强,2005~2007连续三年获得国家新闻出版总署颁布的“全国生活服务类报纸竞争力10强”,并蝉联第一。2013年,《精品购物指南》被国家新闻出版广电总局评为“全国百强报纸”。
本研究使用对《精品购物指南》所做的一次调查结果作为本次案例分析的数据。试图分析目前阅读《精品购物指南》的群体特征,以及影响阅读《精品购物指南》的时间的因素,从而更好地对受众群体和市场做出分析。
第二节描述性统计
1. 数据预处理
##变量赋值
colnames(data)=c(
"编号",
"性别",
"年龄",
"婚姻状况",
"受教育程度",
"职业或身份",
"个人月平均收入",
"报摊购买",
"个人订阅",
"单位订阅",
"赠阅",
"借阅他人",
"其他",
"上班途中",
"下班途中",
"午休时间",
"逛衔购物时",
"不定时",
"对《精品购物指南》的零购情况",
"家人是否会提醒购买《精品》",
"是第几选择",
"家人是否阅读《精品》",
"",
"",
"一直购买(或订阅)本报(习惯)",
"豪华版内容吸引人",
"普通版文章吸引人",
"查找广告信息",
"参加读者乐园版的活动",
"逛商场购物需要",
"价格便宜",
"没有什么原因想起来就买",
"其他",
"住所",
"工作场所",
"车站或乘车路途",
"娱乐场所",
"其他场所",
"多少人阅读同一份报纸",
"阅读《精品》的时间",
"每天读报时间",
"对我消费有指导",
"提高我的生活品位和档次",
"信息实用性强",
"关注社会新闻",
"信息量大",
"信息质量高",
"报道领域全面",
"内容贴近市场",
"寻找有用的信息和广告",
"放松自我",
"通俗易懂",
"广告信息丰富",
"版面编排合理",
"售价合理",
"订阅或零购方便",
"其他",
"平均每月阅读几期《精品》",
"首先欣赏豪华版",
"先看标题,再拣有意思的看",
"我只看自己喜欢的固定栏目",
"看完喜欢的文章,再浏览其他内容",
"只查找对自己有用的信息",
"无目的地翻阅报纸",
"如果未能看到某一期《精品》",
"能够阅读完《精品》内容",
"封面要闻",
"百姓生活新闻",
"北京都市新闻",
"消费新闻",
"读者乐园",
"体坛新闻",
"关注足球",
"篮球时空",
"绿茵评说",
"精品回顾",
"文化资讯",
"影视介绍",
"读书生活",
"音乐欣赏",
"外企专递",
"留学必备",
"充电课堂",
"人才聚焦",
"处世情感",
"健康",
"美食",
"休闲旅游",
"保险",
"律师",
"百货新品",
"休闲宠物",
"户外休闲",
"美食",
"家庭保健",
"超市SHOPPER"
,"新品试验"
,"样品透视"
,"汽车时代"
,"电脑"
,"市场行情"
,"通讯网络"
,"楼市了望"
,"房产金融"
,"政策扫描"
,"家具世界"
,"家装热点"
,"选材指南"
,"饰品快递"
,"非常男人"
,"特别女人"
,"新新人类"
,"网络家庭"
,"扮美家居"
,"今日妈咪"
,"选题大众化"
,"信息实用性强"
,"可读性强"
,"帮助我消费选择"
,"趣味性强"
,"报道领域全面"
,"帮助我了解市场行情"
,"放松自我"
,"文字优美"
,"观点新颖"
,"版式活泼"
,"品位高雅"
,"风格突出"
,"广告内容丰富"
,"其他"
,"招商展览"
,"电脑"
,"通讯"
,"汽车"
,"房地产"
,"家电"
,"食品酒类"
,"旅游娱乐"
,"商场饭店"
,"服装服饰"
,"美容用品"
,"保健品"
,"医疗器械"
,"家居用品"
,"航空订票"
,"招生"
,"人才招聘"
,"公益广告"
,"文化用品"
,"房屋祖赁"
,"金融证券"
,"发行广告"
,"其他"
,"广告对于消费是否有帮助"
,"广告数量适中"
,"广告信息丰富"
,"广告信息及时"
,"广告设计新颖"
,

删除缺失
data=complete.cases(data)2.绘制不同变量之间的关系
geom_point() +
geom_smooth(method=method, ...)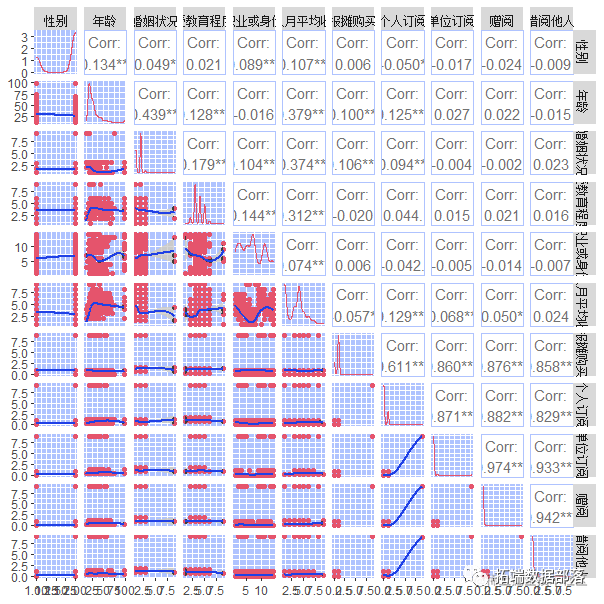
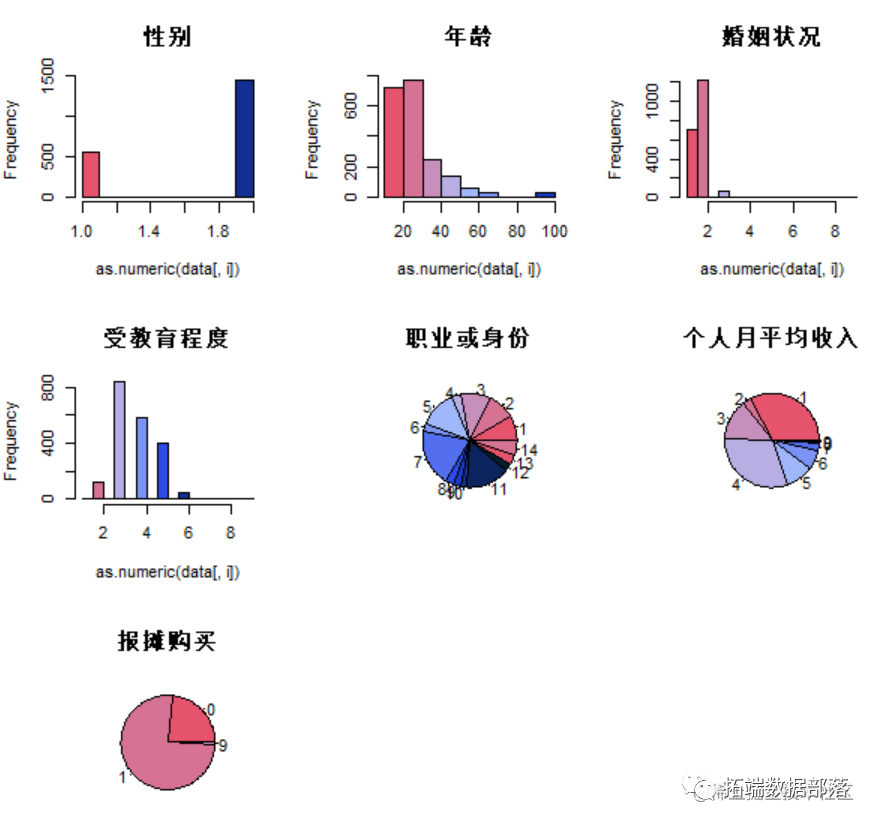
从每个变量的直方图可以看到变量的大概分布情况。绘制各个变量的饼图可以看到基本人口信息的各个取值的所占的百分比。
点击标题查阅往期内容

PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化

左右滑动查看更多

01
02
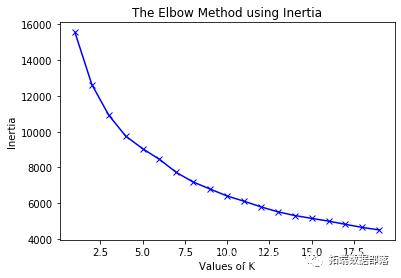
03
04
第三节 回归,方差分析与模型比较
1.相关性分析
for(i in 1:ncol(data))datacor[,i]=as.numeric(data[,i])
#数据归一化
data=scale(datacor)查看性别和阅读《精品》的时间之间是否有相关关系
cor.test(datacor$"性别",
???????? datacor$"阅读《精品》的时间")
##
##? Pearson's product-moment correlation
##
## data:? datacor$性别 and datacor$"阅读《精品》的时间"
## t = 0.63616, df = 1995, p-value = 0.5247
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
##? -0.02964101? 0.05806894
## sample estimates:
##??????? cor
## 0.01424136检验的结果是,由于P =0.5247> 0.05,因此在0.05的显署性水平下,接受原假设,认为两者之间不具有相关关系。
查看婚姻状况和阅读《精品》的时间之间是否具有相关关系
cor.test(datacor$"婚姻状况",
???????? datacor$"阅读《精品》的时间")
##
##? Pearson's product-moment correlation
##
## data:? datacor$婚姻状况 and datacor$"阅读《精品》的时间"
## t = -1.7215, df = 1995, p-value = 0.08531
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
##? -0.082238962? 0.005358859
## sample estimates:
##???????? cor
## -0.03851404检验的结果是,由于P =0.08531> 0.05,因此在0.05的显署性水平下,所以接受原假设,认为两者之间不具有相关关系
查看受教育程度和阅读《精品》的时间之间是否具有相关关系
cor.test(datacor$"受教育程度",
???????? datacor$"阅读《精品》的时间")
##
##? Pearson's product-moment correlation
##
## data:? datacor$受教育程度 and datacor$"阅读《精品》的时间"
## t = -0.71111, df = 1995, p-value = 0.4771
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
##? -0.05974084? 0.02796468
## sample estimates:
##??????? cor
## -0.0159187检验的结果是,由于P =0.4771>0.05,因此在0.05的显著性水平下,接受原假设,认为两者之间不具有相关关系。
2.回归分析
查看共线性关系
which(abs(cormatrix)>0.6,arr.ind = T)
##????????????????????????????? row col
## 编号?????????????????????????? 1?? 1
## 性别?????????????????????????? 2?? 2
## 年龄?????????????????????????? 3?? 3从结果看,没有相关系数大于0.6的不同变量。因此,变量间不存在共线性问题。
回归分析
summary(model)
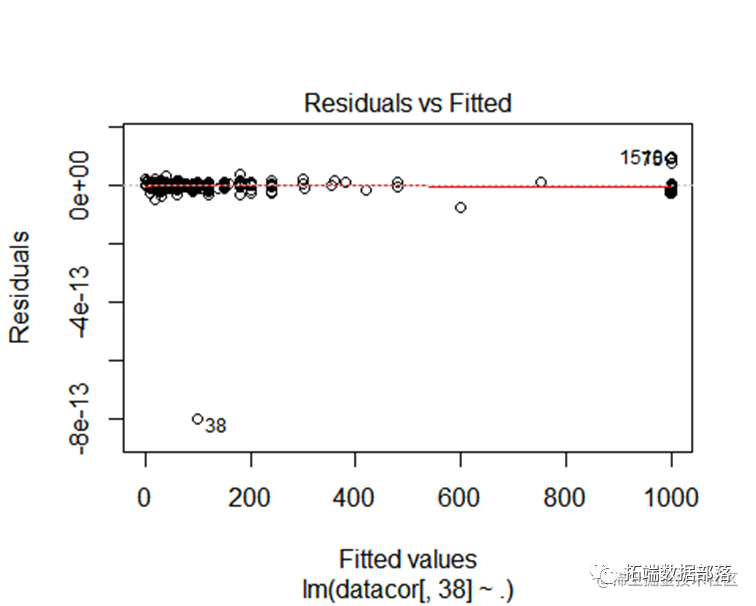
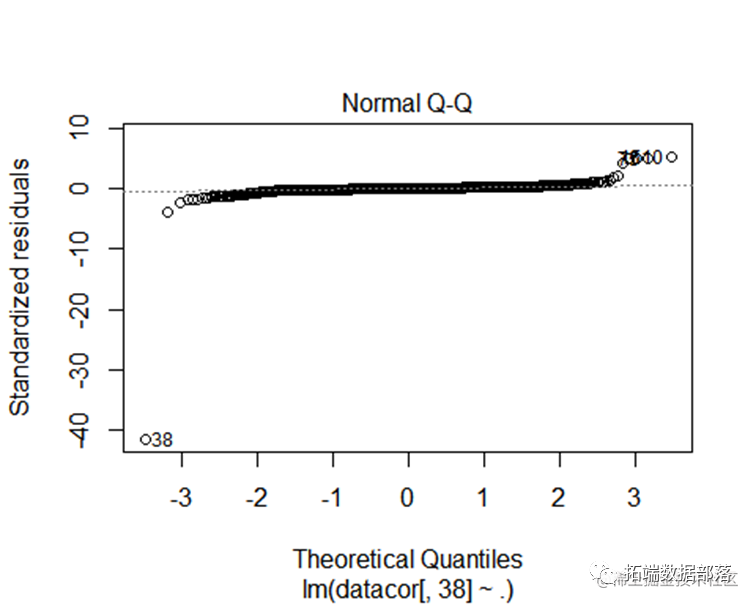
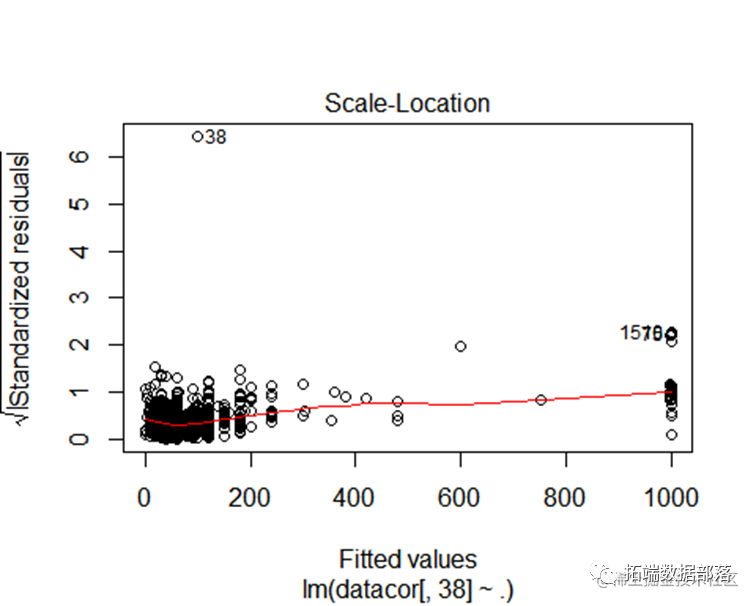
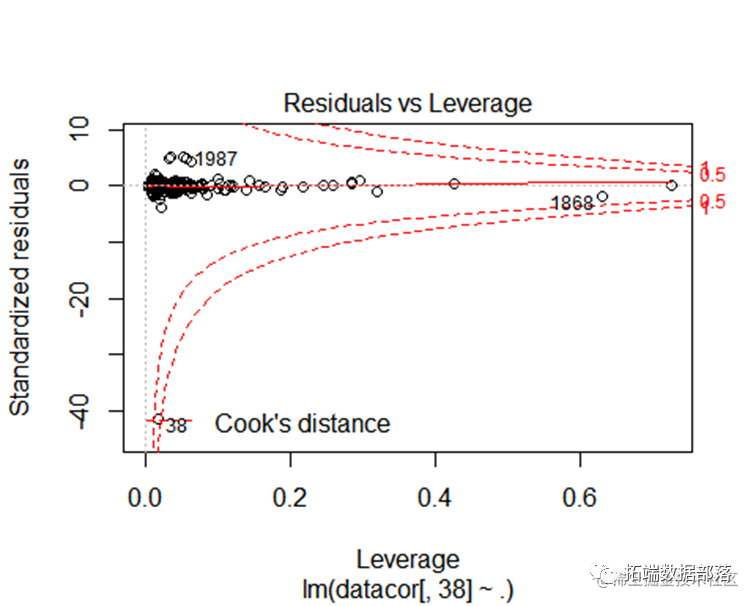
从回归模型的结果来看,可以看被调查者的职业或身份,家人是否阅读《精品》`,以及豪华版内容是否吸引人等因素对被调查对象否阅读《精品》的时间有比较大的影响,p值小于0.05,因此该变量对被调查者选择去看报纸有显著的影响 。
3.模型筛选与比较
无常数项模型拟合

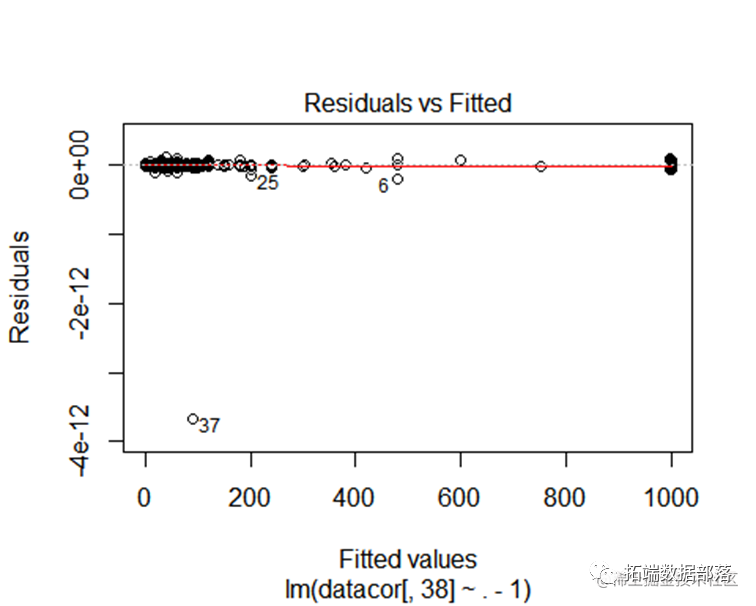
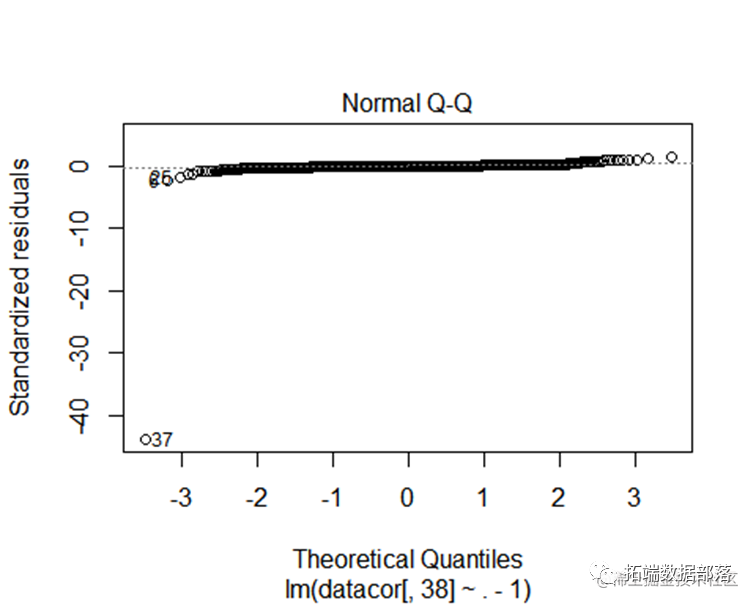
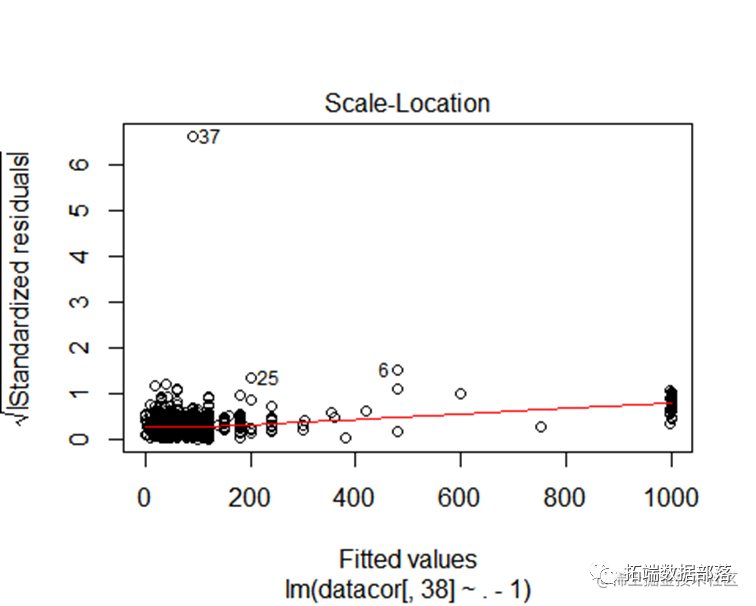
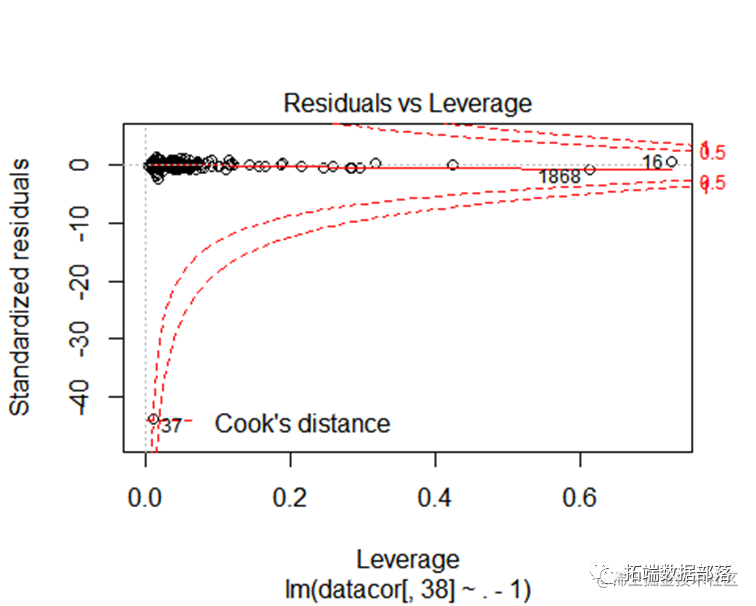
回归模型校正
利用qqPlot()函数提供的正态假设检验方法,它画出了在n-p-1个自由度的t分布下的学生化残差图形,再配合Shapiro检验得出检测结果,而Shapiro样本量的大小范围 配合下图可以发现除了Providence,所有的点都离直线很近,都落在置信区间内,这表明与正态性假相符。
library(car)
qqPlot(model2,labels = row.names(datacor))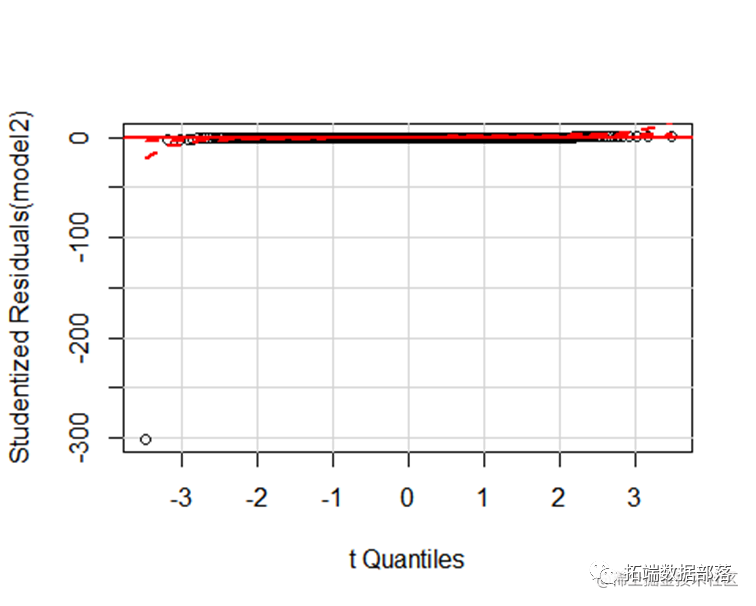
方差齐性
利用残差绘制曲线图并配合Durbin-Watson检验,此检验方法能够检测误差的序列相关性,再配合下表检验结果显著性为0.7604表示接受原假设,因此误差项独立性检验通过。
dwtest(model2)
##
##? Durbin-Watson test
##
## data:? model2
## DW = 2.0242, p-value = 0.7604
## alternative hypothesis: true autocorrelation is greater than 0方差分析

所有变量的p值都小于0.05,说明在0.05的显著水平上,不同特征的被调查对象的阅读精品时间之间有明显差别。

点击文末 “阅读原文”
获取全文完整代码数据资料。
本文选自《R语言回归、anova方差分析、相关性分析 《精品购物指南》调研数据可视化》。
点击标题查阅往期内容
PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化 R语言广义线性模型(GLM)、全子集回归模型选择、检验分析全国风向气候数据 R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM) R语言用潜类别混合效应模型(Latent Class Mixed Model ,LCMM)分析老年痴呆年龄数据 R语言贝叶斯广义线性混合(多层次/水平/嵌套)模型GLMM、逻辑回归分析教育留级影响因素数据R语言估计多元标记的潜过程混合效应模型(lcmm)分析心理测试的认知过程 R语言因子实验设计nlme拟合非线性混合模型分析有机农业施氮水平 R语言非线性混合效应 NLME模型(固定效应&随机效应)对抗哮喘药物茶碱动力学研究 R语言用线性混合效应(多水平/层次/嵌套)模型分析声调高低与礼貌态度的关系 R语言LME4混合效应模型研究教师的受欢迎程度R语言nlme、nlmer、lme4用(非)线性混合模型non-linear mixed model分析藻类数据实例 R语言混合线性模型、多层次模型、回归模型分析学生平均成绩GPA和可视化 R语言线性混合效应模型(固定效应&随机效应)和交互可视化3案例 R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据R语言 线性混合效应模型实战案例 R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据 R语言如何用潜类别混合效应模型(LCMM)分析抑郁症状 R语言基于copula的贝叶斯分层混合模型的诊断准确性研究 R语言建立和可视化混合效应模型mixed effect model R语言LME4混合效应模型研究教师的受欢迎程度 R语言 线性混合效应模型实战案例 R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM) R语言基于copula的贝叶斯分层混合模型的诊断准确性研究 R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题 基于R语言的lmer混合线性回归模型 R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型 R语言分层线性模型案例 R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型 使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型 SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据 用SPSS估计HLM多层(层次)线性模型模型
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。