动态环境SLAM | Remove, then Revert - 基于多分辨率深度图的动态物体移除方法
动态环境SLAM | Remove, then Revert - 基于多分辨率深度图的动态物体移除方法

作者:无疆WGH
编辑:郑欣欣@一点人工一点智能
原文地址:动态环境SLAM | Remove, then Revert - 基于多分辨率深度图的动态物体移除方法
00??前言
通常,按照执行时机的不同,动态物体过滤算法可以分为两类:一是在SLAM过程中在线过滤动态点云,为了保证实时性,通常只能利用相邻(时间相邻或空间相邻)几帧点云互相对比,检测出动态部分;二是用后处理的方式过滤动态点云,此时可以考虑整个SLAM过程中所有的帧的信息,从而更准确、更全面地过滤动态点云。
后处理的方式又可以细分为以下三种思路:
“segmentation-based(基于点云分割的方法)。该类方法通常基于聚类,比如,Litomisky等人基于确定视角下的特征分布直方图(VFH, Viewpoint Feature Histogram)来从静态聚类中区分出动态聚类;Yin等人则认为相邻帧配准过程中匹配误差较大的点很可能是动态点,用这些点作为种子进行区域生长,搜索出的聚类即是动态聚类;此外,Yoon等人也提出了一种基于区域生长过滤动态聚类的方案。基于分割的方法中不得不提的还有基于深度学习的语义分割方法,语义分割直接label出了哪些点是动态物体,建图算法只需要直接弃掉这些点即可,简单粗暴。但是,深度学习方法只能分割出训练过的动态类别,对其它类别的动态物体则无能为力”。
“ray tracing-based (or ray casting-based,基于光线投影的方法)。这类方法非常典型地要结合栅格去实现,可以是普通的占据栅格或者八叉树栅格。其基本原理是,激光点打到的栅格,hits计数+1,激光光束穿过的栅格,misses计数+1,通过hits和misses计算栅格的占据概率,占据概率低于阈值,则抹除掉这个栅格内的所有点。这种方法利用了动态点只会短暂地hit到某个栅格,这个栅格在随后的大部分时间里都会被miss的特点。这种方法的缺点是消耗计算资源,毕竟一个激光点不仅产生了一个hit,更会在光路上的所有栅格中各产生一次miss!实际工程中,Cartographer应用了这种策略,从实际效果来看,基本能较好的过滤掉动态点,但过滤效果不够精准,误杀现象也比较严重”。
“visibility-based(基于视点可见性的方法)。这类方法的基本假设是:如果一个激光点的光路穿过了另一个激光点,那么另一个激光点就是动态点。这个假设逻辑上完全说得通,但实现起来有两个问题:其一,入射角接近90度时的误杀问题,如下图所示,红色箭头指向的旧点因为与新点(五角星)光路很接近,会被误杀掉,考虑到一帧激光点云本身的角度误差、测距误差、光斑影响等,这种误杀会更严重。其二,遮挡问题,比如对于一些大型动态物体,它们完全挡住了激光雷达的视线,激光雷达没有机会看到这些动态物体后方的静态物体,意味着这些动态点永远不会被新的激光点穿过,此时就绝无可能把这些动态点滤除掉了”。
本篇,我们分析一篇基于视点可见性方法的代表作,发表于IROS-2020:Remove, then Revert: Static Point cloud Map Construction using Multiresolution Range Images
代码地址:https://github.com/irapkaist/removert
01??视点可见法的优点与局限
所谓视点可见法(visibility-based method),一个直观的理解是,你在某一个视线方向上,只能看到离你最近的物体,该物体后方的物体则被遮挡,是不可见的。试想你站在路边,有一辆公交车(动态物体)由远及近驶来,当公交车行驶到你面前的时候,你本来能够看得见的马路对面的奶茶店此刻就被遮挡了。如果环境中全部都是静态物体的话,是不会出现这种遮挡的,如果发生了,那我们就倾向于认为,在这个视线方向上更近处的点(脸前的公交车)是动态点。在这种环境下做SLAM建图,如果不加处理的话,动态物体的轨迹(“鬼影”)就会完全留在地图中。
现在,我们用更严谨的SLAM语言来重述视点可见法:给定一组由SLAM得到的原始scan,选择若干个相邻scan拼成一个(sub) map(含有鬼影),从这些scan中选择一个作为query scan,将query scan投影到map中,如果query scan中某个点的光路被map中的某个点遮挡,那么map中的这个点即是动态点。相信你不难想象:公交车的鬼影点遮挡了query scan中“打向路对面建筑物”的点的光路的画面。当然,这个query scan可能也包含了公交车在某个位置的鬼影点,那么这个query scan中的鬼影点可以通过别的query scan以同样的方法去除。
了解了视点可见法的原理后,下面我们来考虑一下这种方法可能有什么缺点。
缺点 1:对SLAM位姿精度敏感。点云拼接成map也好,query scan投影到map也好,都直接根据各个scan的pose进行坐标变换的。那如果pose不准呢?尤其是各个姿态角roll/pitch/yaw,一点偏差都会造成投影误差,进而造成误杀和漏杀,这一点尤其容易发生在物体的边缘处和细长物体(如路灯杆)上。
缺点 2:对点云畸变敏感。同样的道理,运动畸变造成一个点落在了它本不属于的位置上,引入误差。
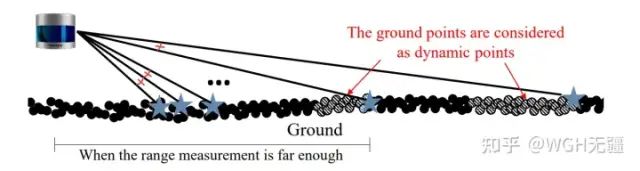
缺点 3:容易误杀地面点。这一点在本专题第一篇文章中已经提到过,如下图,对于query scan中的点(五角星表示),当入射光线贴近地面时,部分地面点(红色箭头所指的点云)因为靠近五角星点的光路,会被认为遮挡了query scan中的点,从而被误杀!这种现象在大入射角时尤其明显。
02??论文问题定义&算法框架
给定一组位姿已知的scan (位姿由SLAM提供),以及由所有scan 构成的点云地图,Romovert 的目的是过滤掉地图中的动态点云。为了使文章更清晰,这里先给出符号定义:
记一帧scan 为P^Q ,取Point cloud of Query scan之意;
记P^Q 附近的一个子地图为P^M ,子地图也即由P^Q 附近的若干个scan 拼成的局部点云地图。
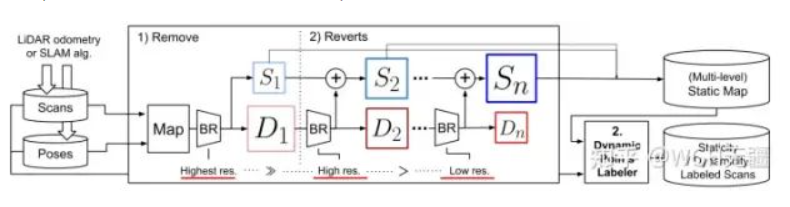
Romovert 的策略是:先通过对比P^Q 和P^M ,识别出P^M 中的动态点集合,记作P^{\hat{D}M} ;剩下的点自动构成静态点集合,记作P^{\hat{s}M} 。【该环节称为Remove 】
但是——如前言部分所说,对比P^Q 和P^M 识别出动态点的过程一定有误差,因此,P^{\hat{D}M} 中有很多点是被误杀的静态点,而P^{\hat{s}M} 则是一个偏保守的静态点集合。
Removert 的核心策略,就是通过多分辨率深度图对比(下文细讲)的方法,将P^{\hat{D}M} 中被误杀的静态点恢复到P^{\hat{s}M} 中。【该环节将动态点反转为静态点,因此称为Revert 】
以上,这种Remove-then-revert 的策略,就称为Removert !论文的算法如下图所示。
细心的读者会发现,这里有两个问题:①Remove 部分通过对比P^Q 和P^M 来识别出动态点的原理是什么,与视点可见法有什么联系?②分辨率深度图对比的原理是什么,如何恢复被误杀的点?我们接着往下看。
03??论文基本思想
首先讨论第一个问题:通过对比P^Q 和P^M 来识别出动态点的具体做法是怎样的,与与视点可见法有什么联系?
具体做法其实很简单,首先将P^Q 在其自身视角下转换为深度图(rang image)——记作I^Q ;然后,将P^M 转换到P^Q 的坐标系下(统一视点),再将转换坐标后的P^M 也转换为深度图——记作I^M 。注意:在P^M 中,同一个方向上是可能有多个点的,但是这里只取最近的那个点的深度作为I^M 中相应像素的深度值。
接着,既然深度图都是在同样的视点下得到的,那直接将I^Q 和I^M 作差,如果I^M 中某一个像素的深度小于I^Q 中对应像素的深度,那就意味着地图中的相应点遮挡了query scan中的点,地图中的这个点就是动态点——这正是上文中所说的视点可见法。
04??基本思想的延伸:Batch Romoval
以上的内容相当于single scan removal,也即用单个scan来决定谁是动态点。但实际的做法是,我们划定一组scan来构成batch(批量),在batch内部,轮流用每个scan去决定“剩下的scan构成的 submap”中谁是动态点。轮流一遍后,每个点都可能被标记了多次,多次的标记结果进行投票,来判定该点到底是动态点,还是静态点。
也就是说——Removert算法中的Remove部分,实际上不是用单个scan决定submap中动/静态类别的,而是用Batch-Removal的策略。
相比于下文Revert,Remove环节所使用的深度图的分辨率是最高的(最精细),Revert环节所用的深度图分辨率均低于Remove部分(更大粒度)。
在Batch Removal中,还有一个很重要的细节——遍历scan的顺序。想象有一辆在激光雷达前方、且和激光雷达等速同向移动的车辆,该车辆在每一个scan中的深度都是一样的。如果我们按顺序来轮流每个scan,就无法把出租车的“鬼影”去除干净。因此作者提出,在Batch内部,应当以随机的顺序来遍历scan。
05??恢复被误杀的点:多分辨率方法
由前言部分可知,即使用Batch Removal,也无法避免大量的错杀。作者发现,用不同分辨率的深度图做Remove时,所得到的结果是不一样的,并且用低分辨率的深度图做Remove时,错杀情况明显更少!如下图所示:

图中,请注意高分辨率深度图对应的I^{diff} 中,物体边缘处的误杀。
低分辨率时错杀减少,这是一个非常重要的性质。其背后的机理是,由SLAM位姿误差或者点云畸变引起的角度投影误差可能也就是0.x度的样子,如果我们用角度分辨率同样为0.x度的range Image做对比时,0.x度的误差带来的影响就不那么明显了!
因此,所谓多分辨率方法恢复被误杀的点,就是利用更低分辨率的深度图把“曾经被无识别为动态点”的点,重新标记为静态,恢复到静态点集合P^{\hat{s}M} 中!
不断地降低分辨率并重复上述过程(一轮Revert),经过多轮Revert后,越来越多的点被回复到P^{\hat{s}M} 中,等所有设定的分辨率都执行完成后,此时的P^{\hat{s}M} 就是最终的静态地图!剩下的部分自动构成动态地图。
在论文中,作者以KITTI和senmantic?KITTI数据集作为测试用例,以0.4角度分辨率作为最高分辨率,进行Remove操作。后续角分辨率每次递增0.1度,用于进行Revert操作。
最后,我给出了算法在执行时的具体流程,如下:
输入:所有的scan,以及每个scan的位姿。
输出:静态地图和动态地图。
流程:
将所有scan划分为一个个batch;
遍历每个batch,在每个batch内部;
step01:以最高图像分辨率做Remove,初步区分静态地图和动态地图;
step02:降低图像分辨率,做Revert,将被误杀的点恢复到静态点集合中;
step03:重复step02,直至所有设定的分辨率执行完成;
step04:获得该batch范围内的最终静态地图和动态地图;
将所有batch的静态地图合到一起,得到最终的静态地图(不同分辨率层级);
将所有batch的动态地图合到一起,得到最终的动态地图(不同分辨率层级);
完成。
06??效果展示与评价
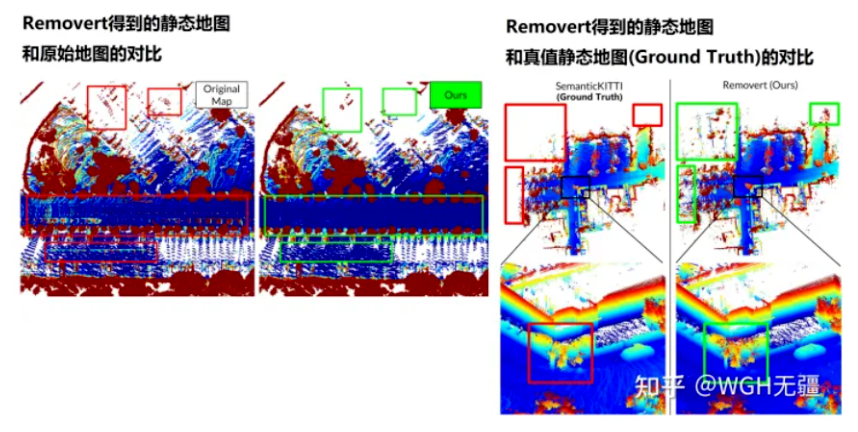
用多分辨率特性解决误杀问题,提供了新的思路,具有很好的参考价值。
从理论上推测,该算法的处理耗时可能比较久,因为在每个batch中都要进行不同分辨率的重复计算,何况SLAM建大地图时,batch的数量是非常多的。实际落地中,性能和代价的平衡必须要考虑。
本文系转载,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。
本文系转载,前往查看
如有侵权,请联系?cloudcommunity@tencent.com 删除。