SIGIR2023|当搜索遇到推荐: 搜索增强的序列推荐框架
SIGIR2023|当搜索遇到推荐: 搜索增强的序列推荐框架

TLDR: 本文针对移动互联网业务中用户在app中既使用搜索又使用推荐服务的场景,提出了一种搜索增强的序列推荐框架SESRec。该框架通过将用户的搜索与推荐兴趣相结合,解耦了用户搜索和推荐行为中相似和不相似兴趣之间的联系。另外,由于用户反馈中缺乏兴趣之间相似度的标签,我们利用了对比学习自监督兴趣的解耦。实验验证了所提出框架的有效性。

论文:arxiv.org/abs/2305.10822 代码:github.com/Ethan00Si/SESREC-SIGIR-2023
研究动机
推荐系统和搜索引擎广泛应用于各大在线平台,帮助用户减轻信息过载。随着互联网数据的增加,单独使用一个系统已不能满足用户需求。因此,流媒体平台,比如:快手和抖音,同时提供搜索和推荐服务。用户在这两种情景中表达了各种兴趣,联合建模两者行为来增强推荐系统是一个潜在的研究方向,关键挑战在于有效利用用户的搜索兴趣建模更加准确的推荐兴趣。

短视频场景中用户搜索和推荐行为的例子
如上图,用户观看了一段关于狗的视频后,选择点评论区推荐的query(被动搜索)以了解更多信息。稍后,用户观看了一段烤肉视频后,又主动键入(自发搜索)了与所观看视频无关的“World Cup 2022”这一个query。对于推荐行为来说,相似的搜索行为反映了用户在使用产品时重叠的强烈兴趣,应予以加强;不相似的搜索行为可能是未被推荐系统发现的兴趣,如:用户的新偏好,也应作为推荐兴趣的补充予以增强。综合来说,推荐系统应该共同考虑用户的搜索和推荐兴趣,并将其解耦成相似和不相似的部分,从而得到更精确的表征。
任务设置
序列推荐只考虑历史交互过的物品序列()建模用户。同传统的序列推荐不同,搜索增强的序列推荐同时考虑了用户的历史搜索行为(提出过的query以及点击过的物品序列,和)和推荐行为()来建模用户兴趣并预测下一次的交互。

所提算法
为了解决上述问题,我们设计了一个用于序列推荐的搜索增强框架,即SESRec,用于学习推荐中解耦开的搜索表示。具体而言,为了解耦两种行为之间的相似和不相似兴趣,我们提出将搜索和推荐序列分别进行建模,并且将每个历史序列分解为两个子序列,分别表示相似和不相似的兴趣,以便我们可以从多个方面提取用户的兴趣。

SESRec的整体框架
自监督兴趣解耦
为了学习两种行为之间的相似性,我们首先通过基于用户的查询-物品交互的InfoNCE损失函数来对齐查询和物品的向量表征。这是后续兴趣解耦的基础。
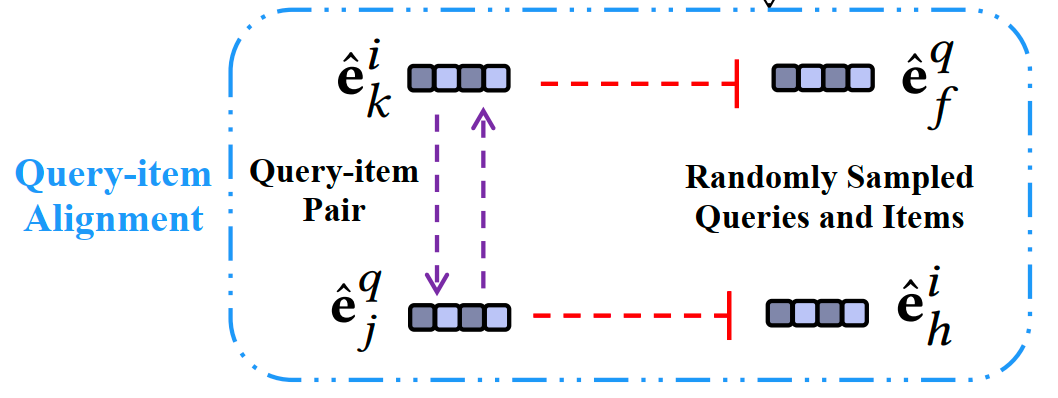
我们使用用户的搜索数据,将query-item交互pair分别进行了item2query和query2item的对齐,将两个loss求和作为最终的对齐的loss。
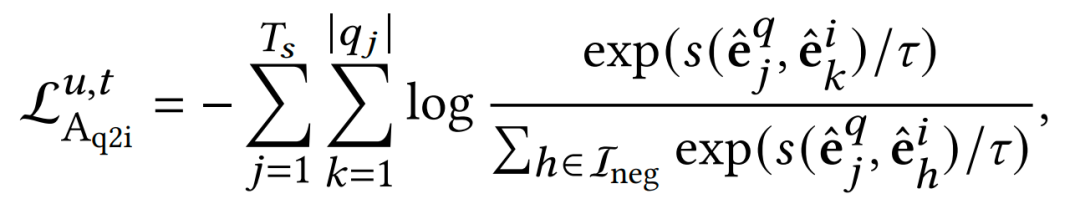
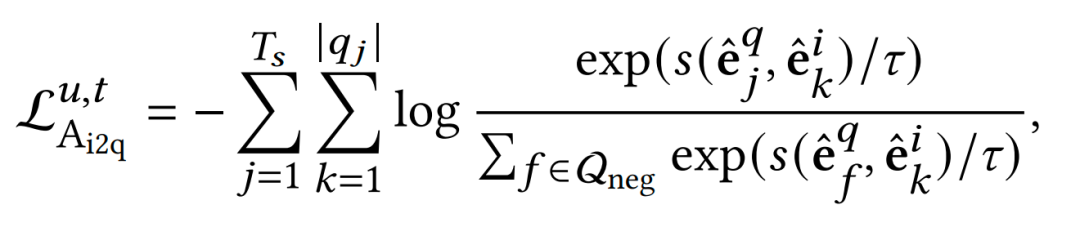
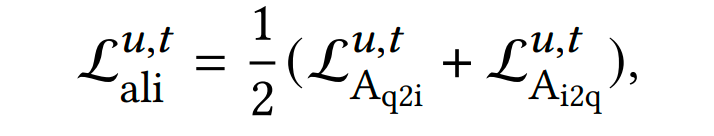
Alignment Loss
接下来,我们使用两个独立的编码器来建模搜索和推荐行为,并且将编码后的行为历史进行了兴趣解耦。由于缺乏搜推行为之间相似兴趣的标签,我们使用了自监督来引导模型学习相似和不相似的兴趣。
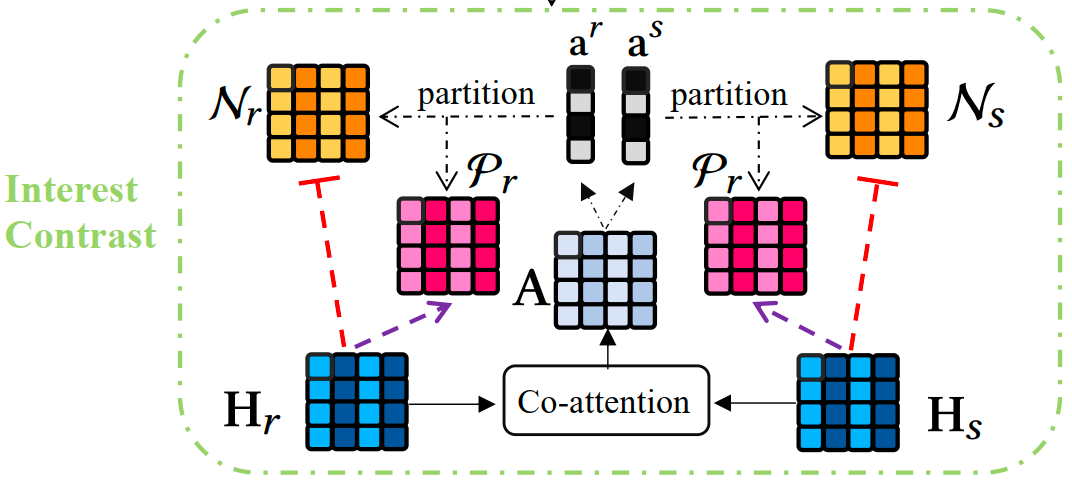
具体而言,我们利用协同注意机制来学习搜索和推荐表征之间的相关性。基于协同注意得分,对于两个序列表示,我们不仅将它们聚合起来生成锚点,这保持了搜索和推荐之间的共同兴趣,还将它们分割成两个子序列,分别表示搜索和推荐之间的相似和不相似兴趣(分别称为正样本和负样本)。接着,我们定义了一个triplet loss,将锚点与正样本之间的距离拉近,将锚点和负样本之间的距离推远。
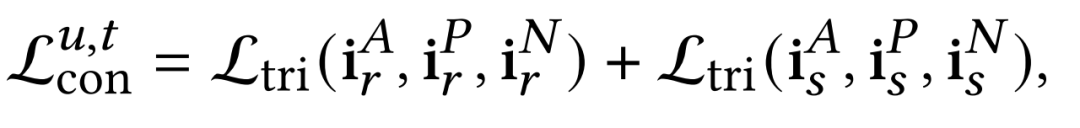
Interest Contrast Loss
基于原始行为以及包含相似和不相似兴趣的解耦开的行为,我们从聚合的、相似的和不相似的兴趣三个方面提取用户兴趣。给定候选物品?,我们利用注意机制重新分配与候选物品相关的用户兴趣。我们分别对搜索和推荐行为提取了用户兴趣表征。下图展示了抽取推荐兴趣的过程,搜索兴趣的抽取过程相同。
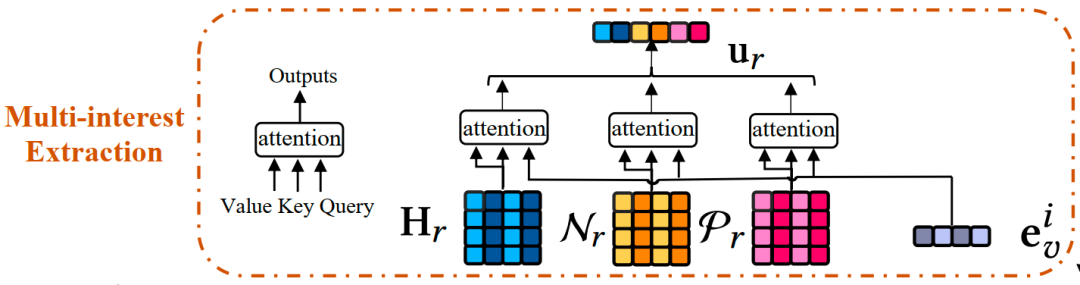
得到用户的搜索、推荐历史兴趣表征向量后,结合用户和物品画像的表征向量,我们使用了MLP进行了最终的交互预测:
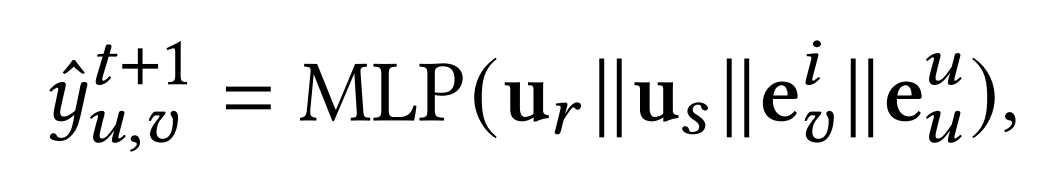
多任务训练
模型的主任务是推荐任务,所以使用BCE loss作为主任务的损失函数。
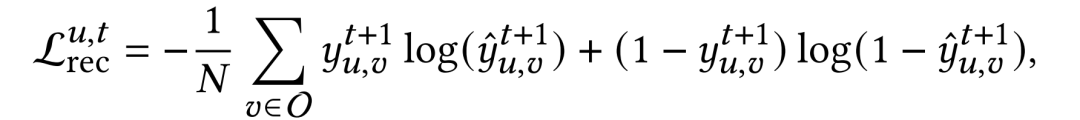
并且考虑到还有额外引入的两个自监督任务的loss,我们使用了多任务学习的范式进行模型训练。其中是额外任务的权重系数,是两个超参数。
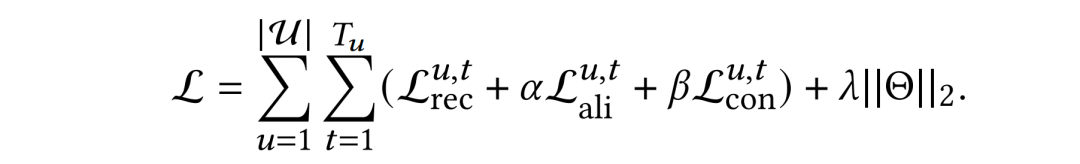
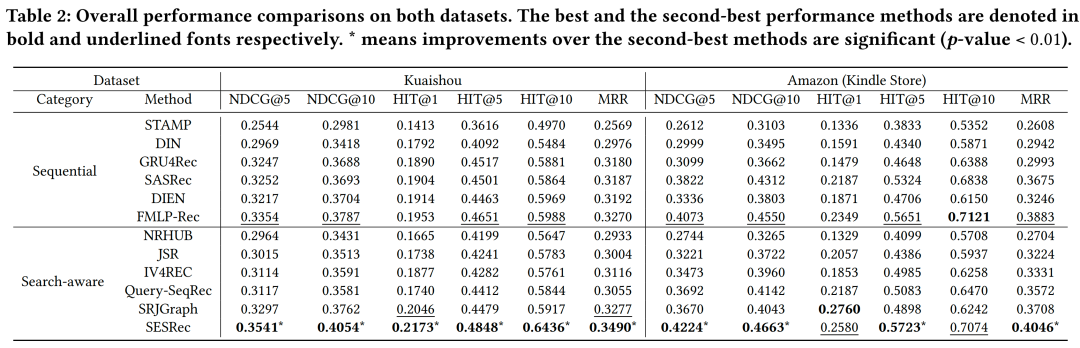
实验结果
在一个工业数据集Kuaishou和一个开源的模拟数据集Amazon上进行的广泛实验表明,本文所提出的SESRec超过了以往的序列推荐模型和引入搜索数据的模型取得了SOTA的效果。