Stability AIΖΔ≤ΦΜυ”ΎΈ»Ε®ά©…ΔΒΡ“τΤΒ…ζ≥…ΡΘ–ΆStable Audio
Stability AIΖΔ≤ΦΜυ”ΎΈ»Ε®ά©…ΔΒΡ“τΤΒ…ζ≥…ΡΘ–ΆStable Audio

Ϋϋ»’Stability AIΆΤ≥ωΝΥ“ΜΩνΟϊΈΣStable AudioΒΡΦβΕΥ…ζ≥…ΡΘ–ΆΘ§ΗΟΡΘ–ΆΩ…“‘ΗυΨί”ΟΜßΧαΙ©ΒΡΈΡ±ΨΧα Ψά¥¥¥Ϋ®“τά÷ΓΘ‘ΎNVIDIA A100 GPU…œStable AudioΩ…“‘‘Ύ“ΜΟκ÷”ΡΎ“‘44.1 kHzΒΡ≤…―υ¬ ≤ζ…ζ95ΟκΒΡΝΔΧε…υ“τΤΒΘ§”κ‘≠ Φ¬Φ“τœύ±»Θ§ΗΟΡΘ–Ά¥Πάμ ±ΦδΒΡ¥σΖυΦθ…ΌΙι“ρ”ΎΥϋΕ‘―ΙΥθ“τΤΒ«±‘Ύ±μ ΨΒΡ”––ߥΠάμΓΘ
ΦήΙΙ
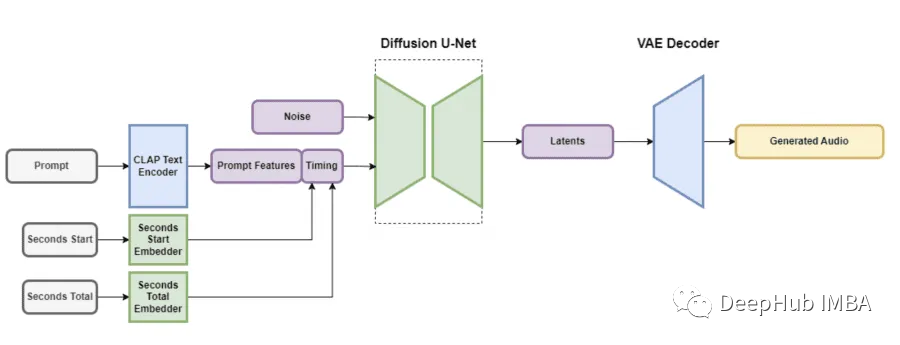
Ή‘Ε·±ύ¬κΤς(VAE)Θ§“ΜΗωΈΡ±Ψ±ύ¬κΤςΚΆU-Netά©…ΔΡΘ–ΆΓΘVAEΆ®ΙΐΜώ»Γ δ»κ“τΤΒ ΐΨί≤Δ±μ ΨΈΣ±ΘΝτΉψΙΜ–≈œΔ”Ο”ΎΉΣΜΜΒΡ―ΙΥθΗώ ΫΘ§“ρΈΣ Ι”ΟΝΥΨμΜΐΫαΙΙΘ§Υυ“‘≤Μ ήΟη ω“τΤΒ±ύΫβ¬κΤςΒΡ”ΑœλΘ§Ω…“‘”––ßΒΊ±ύ¬κΚΆΫβ¬κΩ…±δ≥ΛΕ»ΒΡ“τΤΒΘ§Ά§ ±±Θ≥÷ΗΏ δ≥ω÷ ΝΩΓΘ
ΈΡ±ΨΧα ΨΆ®Ιΐ‘Λœ»―ΒΝΖΒΡΈΡ±Ψ±ύ¬κΤς(≥ΤΈΣCLAP)ΈόΖλΦ·≥…ΓΘ’βΗω±ύ¬κΤς « Ι”ΟΨΪ–Ρ≤ΏΜ°ΒΡ ΐΨίΦ·¥”ΆΖΩΣ ΦΙΙΫ®ΒΡΘ§Ω…“‘±ΘΝτΝΥΈΡ±ΨΧΊ’ςΑϋΚ§ΝΥΉψΙΜΒΡ–≈œΔΘ§Ω…“‘‘ΎΒΞ¥ ΚΆœύ”ΠΒΡ…υ“τ÷°ΦδΫ®ΝΔ”–“β“εΒΡΝΣœΒΓΘ¥”CLAP±ύ¬κΤςΒΡΒΙ ΐΒΎΕΰ≤ψΧα»ΓΒΡ’β–©ΈΡ±ΨΧΊ’ςΘ§»ΜΚσΆ®ΙΐU-NetΒΡΉΔ“βΝΠ≤ψΫχ––“ΐΒΦΓΘ
ΈΣΝΥ…ζ≥…”Ο”Ύ ±Φδ«Ε»κΒΡ“τΤΒΤ§ΕΈΘ§–η“ΣΦΤΥψΝΫΗωΙΊΦϋ≤Έ ΐ:Τ§ΕΈΒΡΤπ Φ ±Φδ(“‘ΟκΈΣΒΞΈΜ)(≥ΤΈΣΓΑseconds_startΓ±)ΚΆ‘≠ Φ“τΤΒΈΡΦΰΒΡΉή≥÷–χ ±Φδ(“‘ΟκΈΣΒΞΈΜ)(≥ΤΈΣΓΑseconds_totalΓ±)ΓΘ’β–©÷Β±ΜΉΣΜΜ≥…άκ…Δ―ßœΑΒΡ«Ε»κΘ§‘Ύ δ»κΒΫU-NetΒΡΉΔ“β≤ψ÷°«Α”κ≤ι―·Νν≈ΤΝ§Ϋ”ΓΘ‘ΎΆΤάμΫΉΕΈΘ§’β–©÷ΒΉςΈΣΧθΦΰ‘ –μ”ΟΜß÷ΗΕ®Υυ–ηΒΡΉν÷’“τΤΒ δ≥ω≥ΛΕ»ΓΘ
Stable Audio÷–ΒΡά©…ΔΡΘ–Ά «“ΜΗωU-NetΦήΙΙΘ§ΨΏ”–«Ω¥σΒΡ9.07“ΎΗω≤Έ ΐΘ§ΝιΗ–ά¥Ή‘Mo?sai ΡΘ–ΆΓΘΥϋΫαΚœ≤–≤ν≤ψΓΔΉ‘ΉΔ“βΝΠ≤ψΚΆΫΜ≤φΉΔ“βΝΠ≤ψΘ§Μυ”ΎΈΡ±ΨΚΆ ±Φδ«Ε»κΕ‘ δ»κ ΐΨίΫχ––”––ßΫΒ‘κΓΘ
ΐΨίΦ·
Stable Audio‘ΎΑϋΚ§≥§Ιΐ80ΆρΗω“τΤΒΈΡΦΰΒΡΙψΖΚ ΐΨίΦ·…œΫχ––ΝΥ―ΒΝΖΓΘ’βΗωΕύ―υΜ·ΒΡΦ·ΚœΑϋά®“τά÷ΓΔ“τ–ßΓΔά÷Τς―υ±ΨΦΑΤδœύΙΊΒΡΈΡ±Ψ‘Σ ΐΨίΘ§Ήή ±≥Λ≥§Ιΐ19,500–Γ ±ΓΘ’βΗωΙψΖΚΒΡ ΐΨίΦ· «Ά®Ιΐ”κ“τά÷ΩβAudioSparxΒΡΚœΉςΕχΧαΙ©ΒΡΓΘ
ΉήΫα
Stability AIΒΡStable Audio AIΡΘ–Ά±ξ÷ΨΉ≈»ΥΙΛ÷«Ρή«ΐΕ·ΒΡΧΐΨθ¥¥‘λΝΠΒΡ÷Ί¥σΖ…‘ΨΓΘΥϋΈΣ“τά÷ΚΆ…υ“τΑ°ΚΟ’Ώ¥ρΩΣΝΥ–¬ΒΡ ”“ΑΓΘ‘ΎΈ¥ά¥ΜΙΜαΧαΙ©Ϋχ“Μ≤Ϋ‘ω«ΩΡΘ–ΆΓΔ ΐΨίΦ·ΚΆ―ΒΝΖΦΦ θΒΡΧεœΒΫαΙΙΘ§ΖΔ≤ΦΜυ”ΎStable AudioΒΡΩΣ‘¥ΡΘ–ΆΘ§≤ΔΫΪΧαΙ©±Ί“ΣΒΡ¥ζ¬κΘ§“‘ΖΫ±ψΕ®÷Τ“τΤΒΡΎ»ί…ζ≥…ΡΘ–ΆΒΡ―ΒΝΖΓΘ
œνΡΩΒΡΙΌΖΫΆχ’ΨΘΚ
https://www.stableaudioweb.com/
±ΨΈΡΖ÷œμΉ‘ DeepHub IMBA ΈΔ–≈ΙΪ÷ΎΚ≈Θ§«ΑΆυ≤ιΩ¥
»γ”–«÷»®Θ§«κΝΣœΒ cloudcommunity@tencent.com …Ψ≥ΐΓΘ
±ΨΈΡ≤Έ”κ?ΧΎ―Ε‘ΤΉ‘ΟΫΧεΖ÷œμΦΤΜ°? Θ§ΜΕ”≠»»Α°–¥ΉςΒΡΡψ“ΜΤπ≤Έ”κΘΓ