每日学术速递1.10

1.Instruct-Imagen: Image Generation with Multi-modal Instruction

标题:Instruct-Imagen:使用多模式指令生成图像
作者:Hexiang Hu, Kelvin C.K. Chan, Yu-Chuan Su, Wenhu Chen, Yandong Li, Kihyuk Sohn, Yang Zhao, Xue Ben, Boqing Gong, William Cohen, Ming-Wei Chang, Xuhui Jia
文章链接:https://arxiv.org/abs/2401.01952


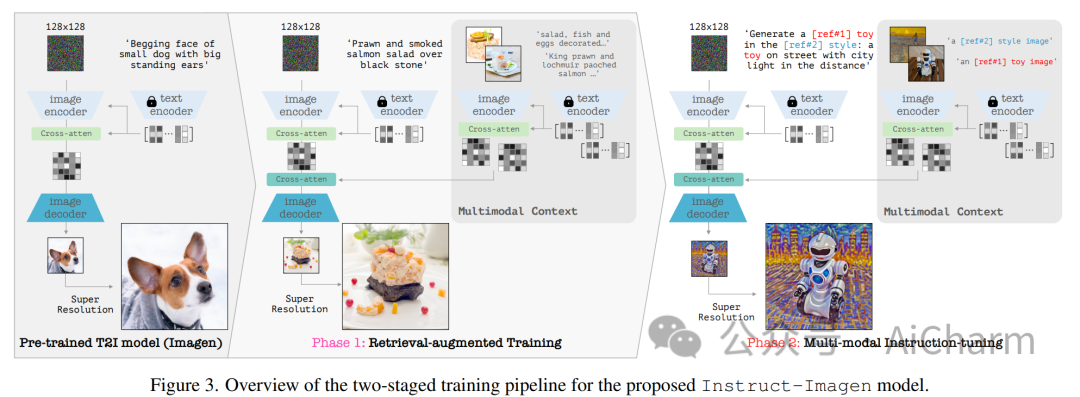
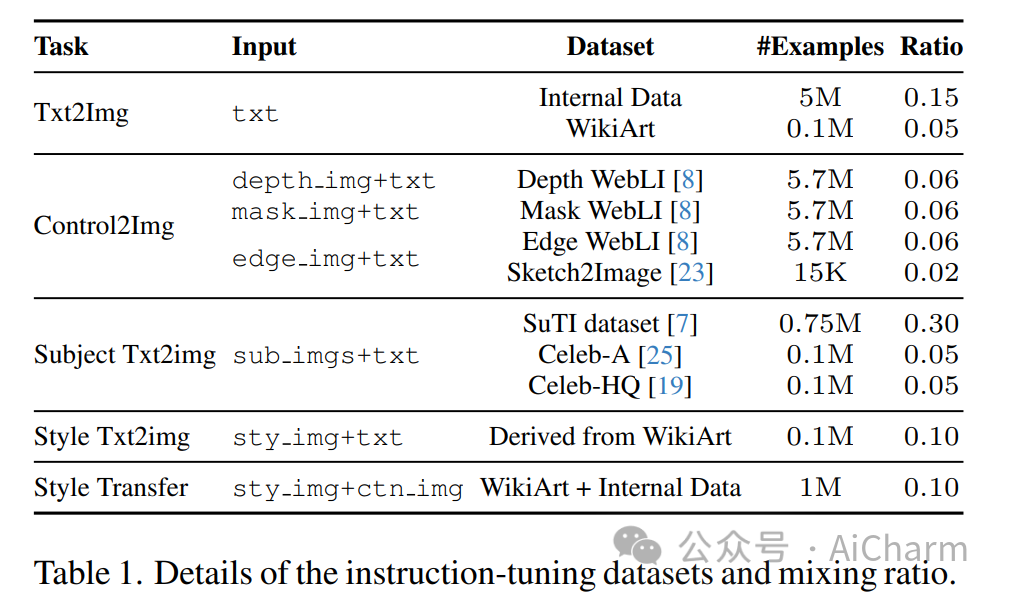
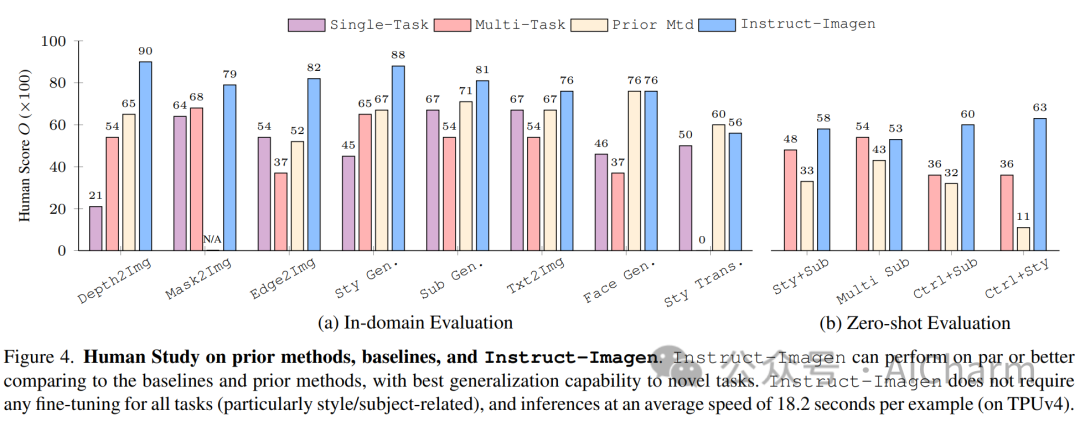




摘要:
本文提出了 instruct-imagen,这是一个处理异构图像生成任务并泛化未见过的任务的模型。我们引入了用于图像生成的“多模态指令”,这是一种精确阐明一系列生成意图的任务表示。它使用自然语言来合并不同的模式(例如文本、边缘、风格、主题等),以便可以以统一的格式标准化丰富的生成意图。然后,我们通过使用两阶段框架微调预先训练的文本到图像扩散模型来构建 instruct-imagen。首先,我们使用检索增强训练来调整模型,以增强模型的能力,使其生成基于外部多模态上下文。随后,我们针对需要视觉语言理解(例如,主题驱动生成等)的不同图像生成任务对适应模型进行微调,每个任务都与封装任务本质的多模态指令配对。对各种图像生成数据集的人类评估表明,instruct-imagen 匹配或超越了领域内先前的特定任务模型,并展示了对看不见的和更复杂的任务的有希望的泛化能力。
2.ODIN: A Single Model for 2D and 3D Perception

标题:ODIN:2D 和 3D 感知的单一模型
作者:Ayush Jain, Pushkal Katara, Nikolaos Gkanatsios, Adam W. Harley, Gabriel Sarch, Kriti Aggarwal, Vishrav Chaudhary, Katerina Fragkiadaki
文章链接:https://arxiv.org/abs/2401.02416
项目代码:https://odin-seg.github.io/
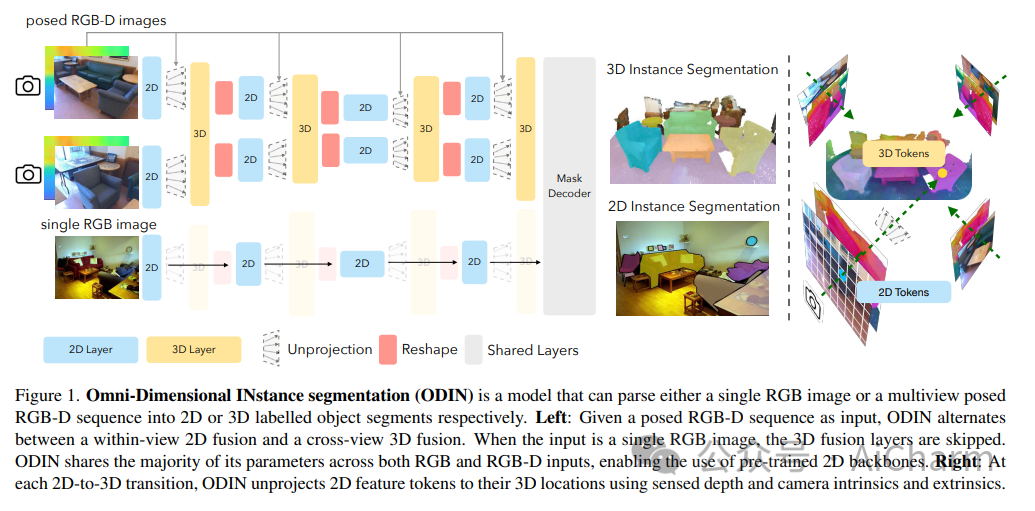
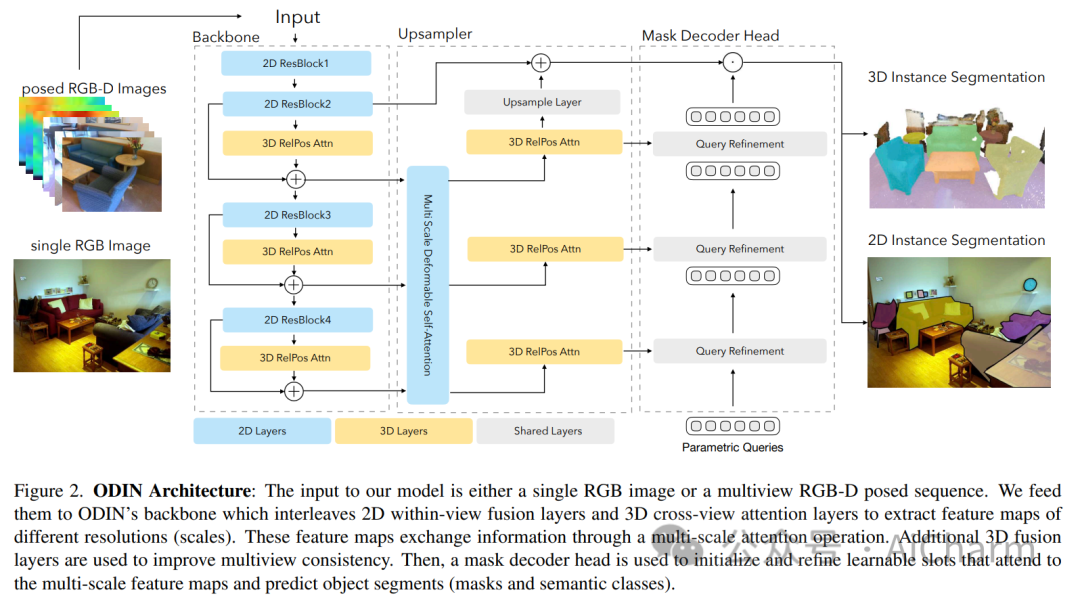
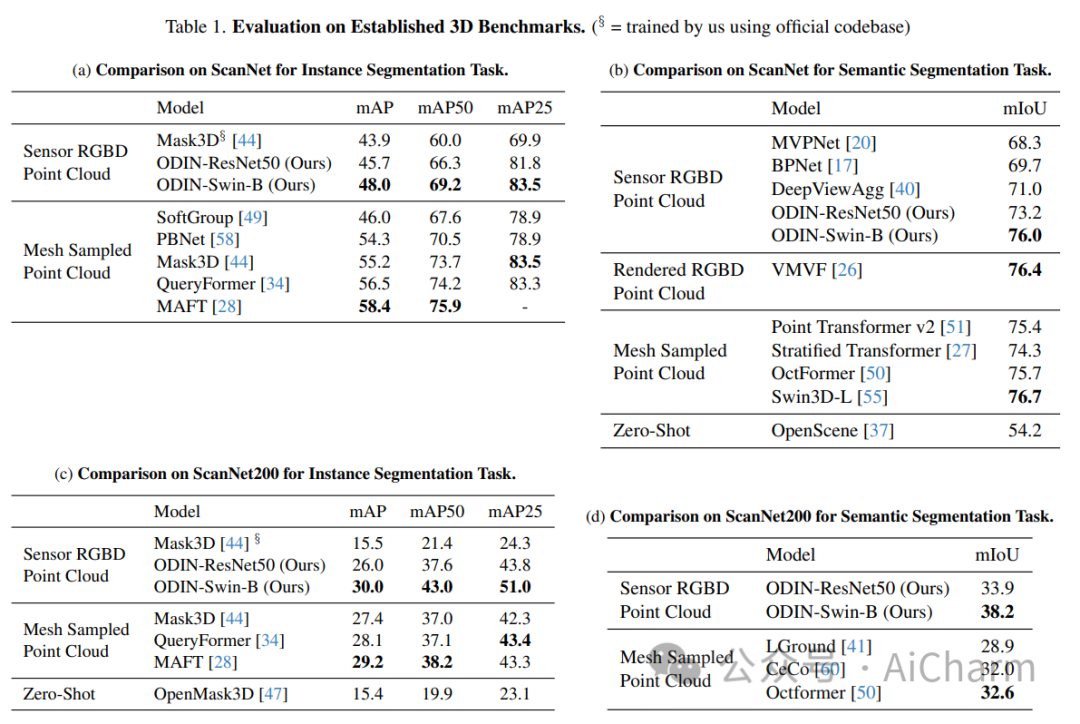
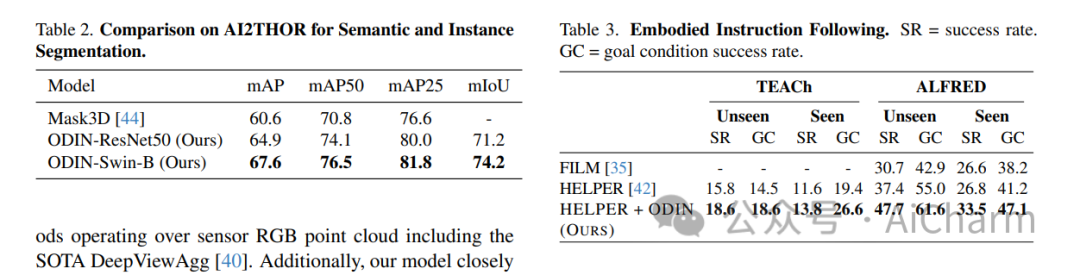
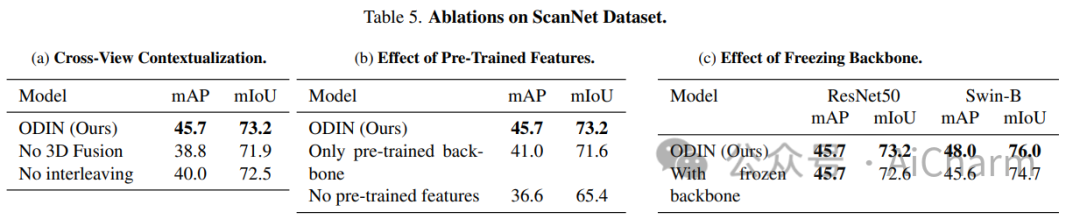
摘要:
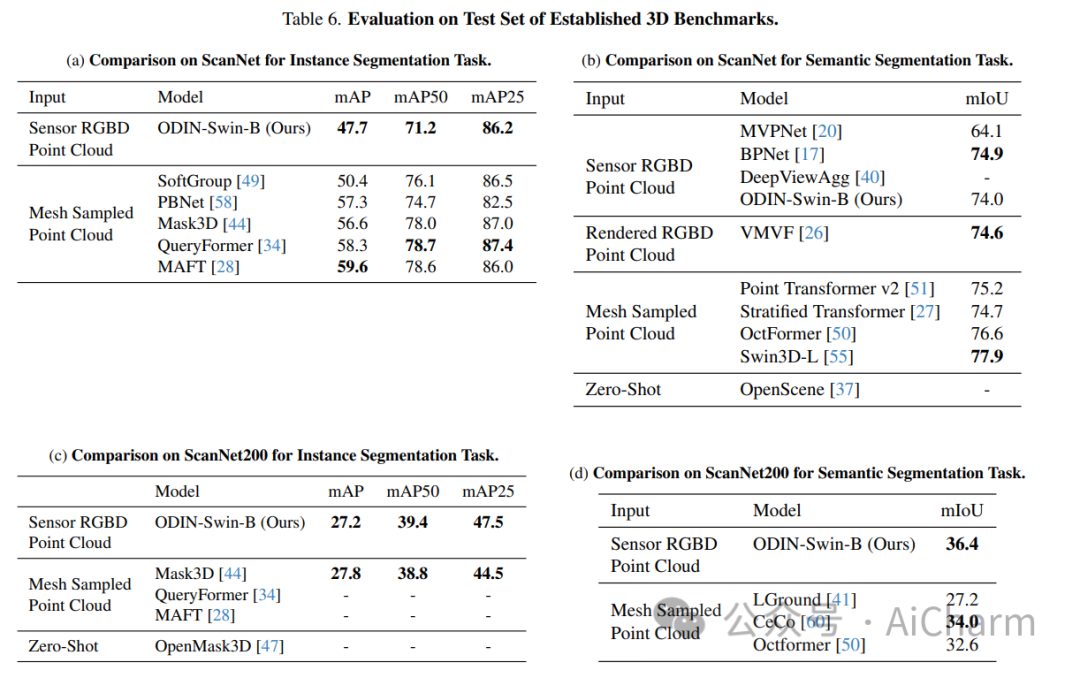
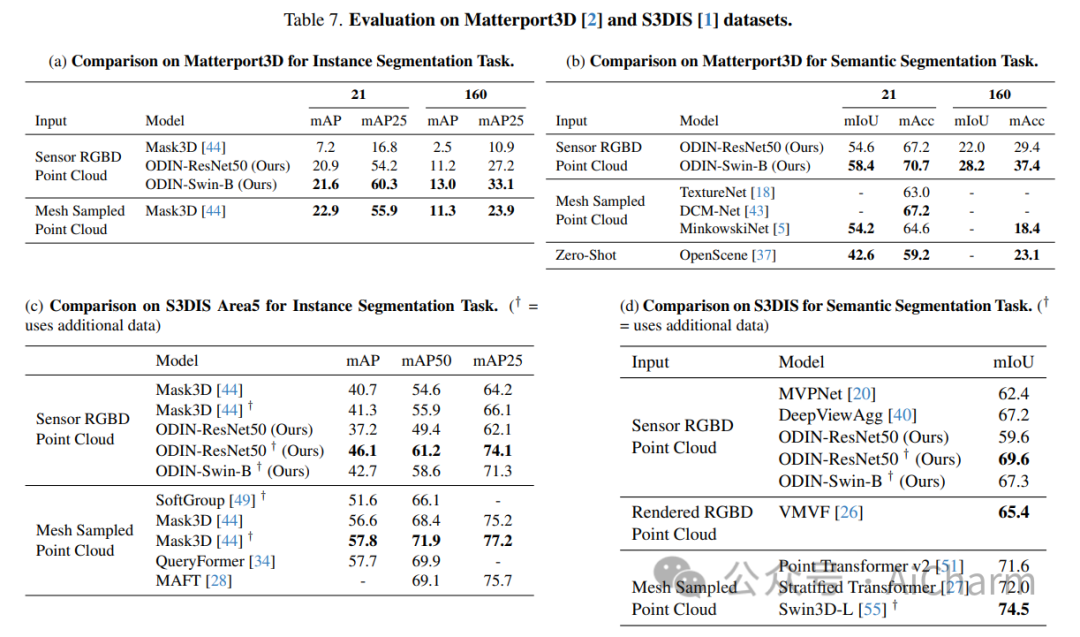
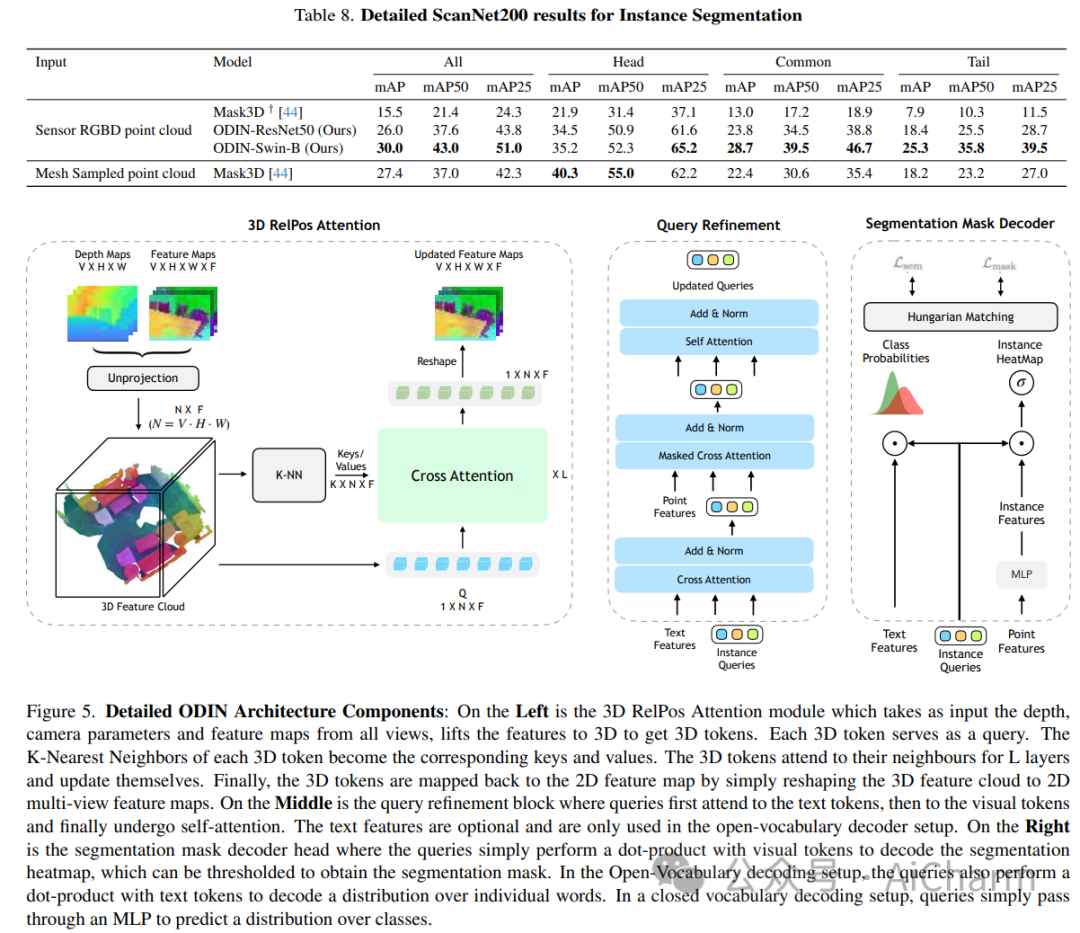
ScanNet 等当代 3D 感知基准的最先进模型使用并标记数据集提供的 3D 点云,这些点云是通过感测的多视图 RGB-D 图像的后处理获得的。它们通常在域内进行训练,放弃大规模 2D 预训练,并优于以 RGB-D 多视图图像为特征的替代方案。使用姿势图像的方法与后处理 3D 点云的方法之间的性能差距让人更加相信 2D 和 3D 感知需要不同的模型架构。在本文中,我们挑战了这一观点,并提出了 ODIN(全维实例分割),这是一种可以分割和标记 2D RGB 图像和 3D 点云的模型,使用在 2D 视图内和 3D 跨视图之间交替的转换器架构。视图信息融合。我们的模型通过所涉及标记的位置编码来区分 2D 和 3D 特征操作,该编码捕获 2D 补丁标记的像素坐标和 3D 特征标记的 3D 坐标。ODIN 在 ScanNet200、Matterport3D 和 AI2THOR 3D 实例分割基准上实现了最先进的性能,在 ScanNet、S3DIS 和 COCO 上实现了具有竞争力的性能。当使用感测到的 3D 点云代替从 3D 网格采样的点云时,它的性能大大优于以前的所有工作。当在可指导的具体代理架构中用作 3D 感知引擎时,它在 TEACh 对话行动基准上树立了新的最先进水平。
3.aMUSEd: An Open MUSE Reproduction

标题:aMUSEd:开放式 MUSE 再现
作者:Suraj Patil, William Berman, Robin Rombach, Patrick von Platen
文章链接:https://arxiv.org/abs/2401.01808
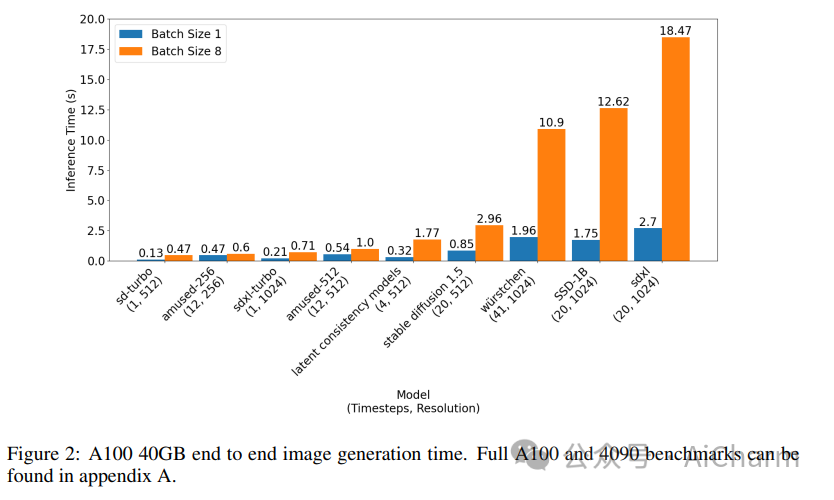
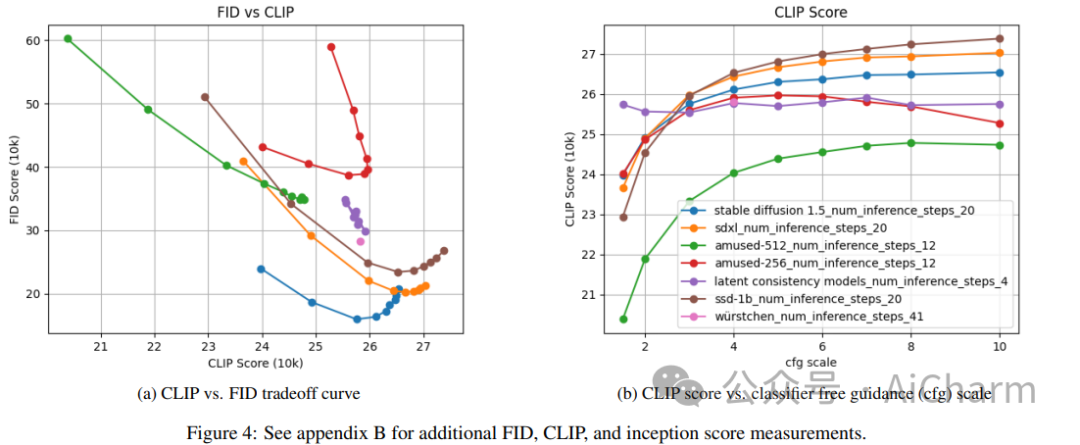

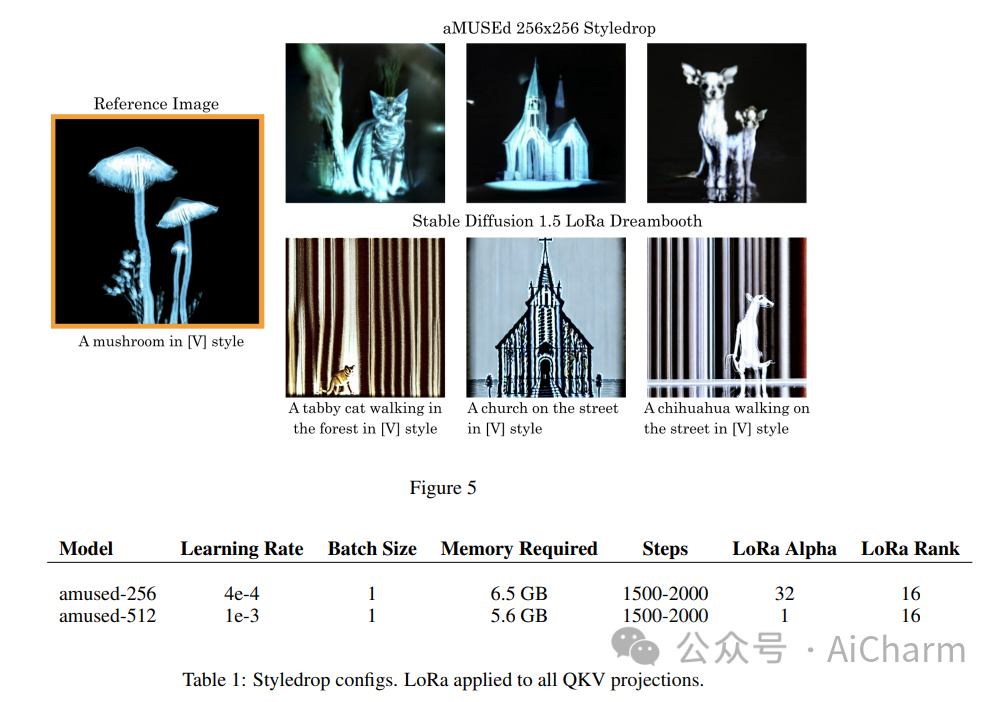


摘要:
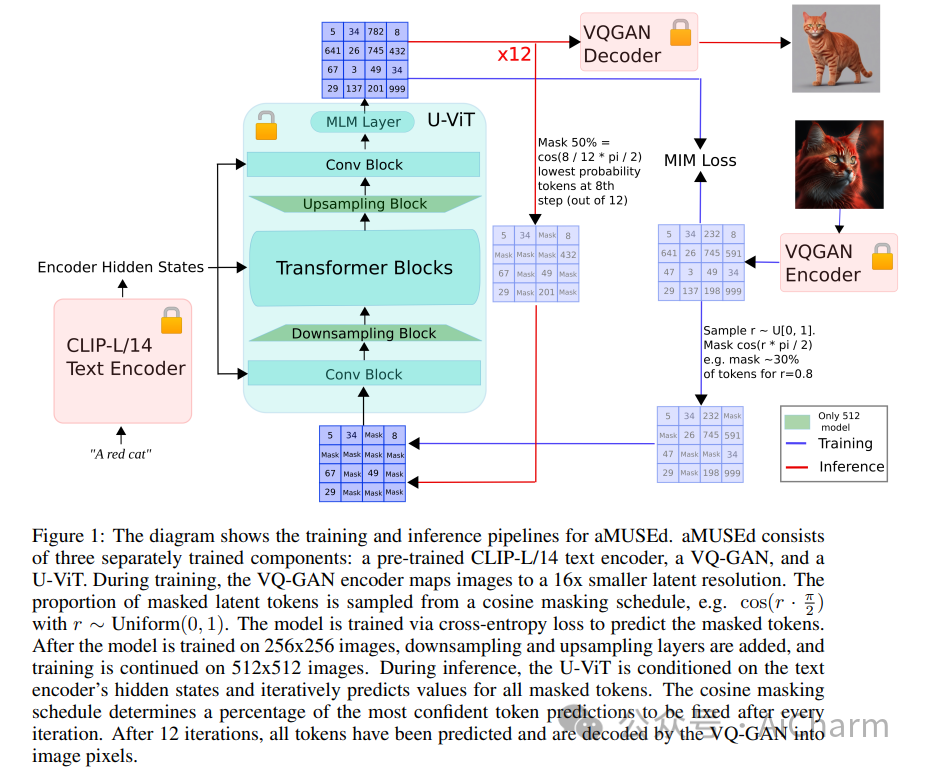
我们提出了 aMUSEd,一个开源的、轻量级的蒙版图像模型 (MIM),用于基于 MUSE 的文本到图像生成。aMUSEd 拥有 MUSE 10% 的参数,专注于快速图像生成。我们认为,与文本到图像生成的流行方法潜在扩散相比,MIM 尚未得到充分探索。与潜在扩散相比,MIM 需要更少的推理步骤并且更具可解释性。此外,MIM 可以进行微调,以仅使用单个图像来学习其他样式。我们希望通过展示 MIM 在大规模文本到图像生成方面的有效性并发布可重复的训练代码来鼓励对 MIM 的进一步探索。我们还发布了两个模型的检查点,它们直接生成 256x256 和 512x512 分辨率的图像。