教程:使用 Chroma 和 OpenAI 构建自定义问答机器人
教程:使用 Chroma 和 OpenAI 构建自定义问答机器人

教程:使用 Chroma 和 OpenAI 构建自定义问答机器人
翻译自 Tutorial: Use Chroma and OpenAI to Build a Custom Q&A Bot 。
在上一个教程中,我们探讨了 Chroma 作为一个向量数据库来存储和检索嵌入。现在,让我们将用例扩展到基于 OpenAI 和检索增强生成(RAG)技术构建问答应用程序。
在最初为学院奖构建问答机器人时,我们实现了基于一个自定义函数的相似性搜索,该函数计算两个向量之间的余弦距离。我们将用一个查询替换掉该函数,以在Chroma中搜索存储的集合。
为了完整起见,我们将开始设置环境并准备数据集。这与本教程中提到的步骤相同。
步骤1 - 准备数据集
从 Kaggle 下载奥斯卡奖数据集,并将 CSV 文件移到名为 data 的子目录中。该数据集包含 1927 年至 2023 年奥斯卡金像奖的所有类别、提名和获奖者。我将 CSV 文件重命名为 oscars.csv 。
首先导入 Pandas 库并加载数据集:
import pandas as pd
df = pd.read_csv('./data/oscars.csv')
df.head()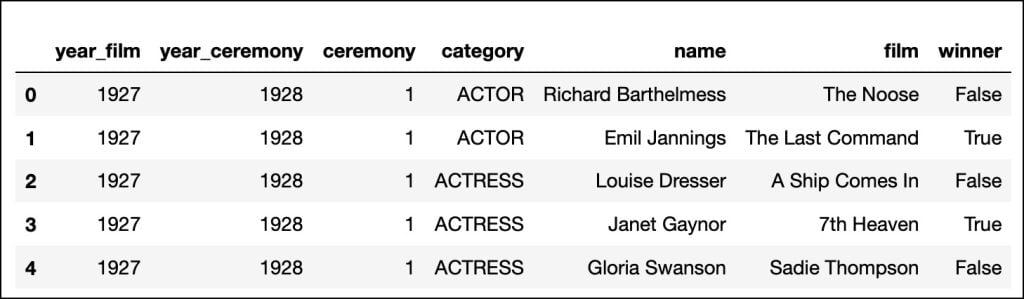
数据集结构良好,有列标题和代表每个类别详细信息的行,包括演员/技术人员的姓名、电影和提名是否获奖。
由于我们最感兴趣的是与 2023 年相关的奖项,因此让我们对其进行过滤,并创建一个新的 Pandas data frame 。同时,我们也将类别转换为小写,删除电影值为空的行。这有助于我们为 GPT 3.5 设计上下文提示。
df = df.loc[df['year_ceremony'] == 2023]
df = df.dropna(subset=['film'])
df['category'] = df['category'].str.lower()
df.head()
对过滤和清理过的数据集,让我们在 dataframe 中添加一个包含整个提名句子的新列。当这个完整的句子发送到 GPT 3.5 时,它可以在上下文中找到事实。
df['text'] = df['name'] + ' got nominated under the category, ' + df['category'] + ', for the film ' + df['film'] + ' to win the award'
df.loc[df['winner'] == False, 'text'] = df['name'] + ' got nominated under the category, ' + df['category'] + ', for the film ' + df['film'] + ' but did not win'
df.head()['text']请注意,我们如何连接这些值以生成一个完整的句子。例如,在 dataframe 的前两行中, “text” 列具有以下值:
Austin Butler got nominated under the category, actor in a leading role, for the film Elvis but did not win Colin Farrell got nominated under the category, actor in a leading role, for the film The Banshees of Inisherin but did not win
步骤2 - 为数据集生成并存储单词嵌入
既然我们已经从数据集构建了文本,那么就将其转换为单词嵌入并存储在 Chroma 中。
这是一个关键步骤,因为嵌入模型生成的标记将帮助我们执行语义搜索,以检索数据集中具有相似含义的句子。
import openai
import chromadb
from chromadb.utils import embedding_functions
def text_embedding(text) -> None:
response = openai.Embedding.create(model="text-embedding-ada-002", input=text)
return response["data"][0]["embedding"]
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ["OPENAI_API_KEY"],
model_name="text-embedding-ada-002"
)在上面的步骤中,我们通过传递 OpenAI API 密钥和嵌入模型来指示 Chroma 使用 OpenAI 嵌入。
我们可以使用 text_embedding 函数将查询的短语或句子转换为 Chroma 使用的相同嵌入格式。
现在我们可以基于 OpenAI 嵌入模型创建 ChromaDB 集合。
client = chromadb.Client()
collection = client.get_or_create_collection("oscars-2023",embedding_function=openai_ef) 请注意,我们通过传递函数将集合与 OpenAI 相关联。这将成为吸收数据时生成嵌入的默认机制。
让我们将 Pandas dataframe 中的文本列转换为可以传递给 Chroma 的 Python 列表。由于 Chroma 中存储的每个文档还需要字符串格式的 ID ,所以我们将 dataframe 的索引列转换为字符串列表。
docs = df["text"].tolist()
ids = [str(x) for x in df.index.tolist()]文档和 ID 完全填充后,我们就可以创建集合了。
collection.add(
documents=docs,
ids=ids
)步骤3 - 执行相似性搜索以增强提示
首先,为获取音乐类别所有提名的字符串生成单词嵌入。
vector = text_embedding("Nominations for music")现在我们可以将其作为搜索查询传递给 Chroma ,以检索所有相关文档。通过设置 n_results 参数,我们可以将输出限制为 15 个文档。
results = collection.query(
query_embeddings=vector,
n_results=15,
include=["documents"]
)结果字典包含所有文档的列表。
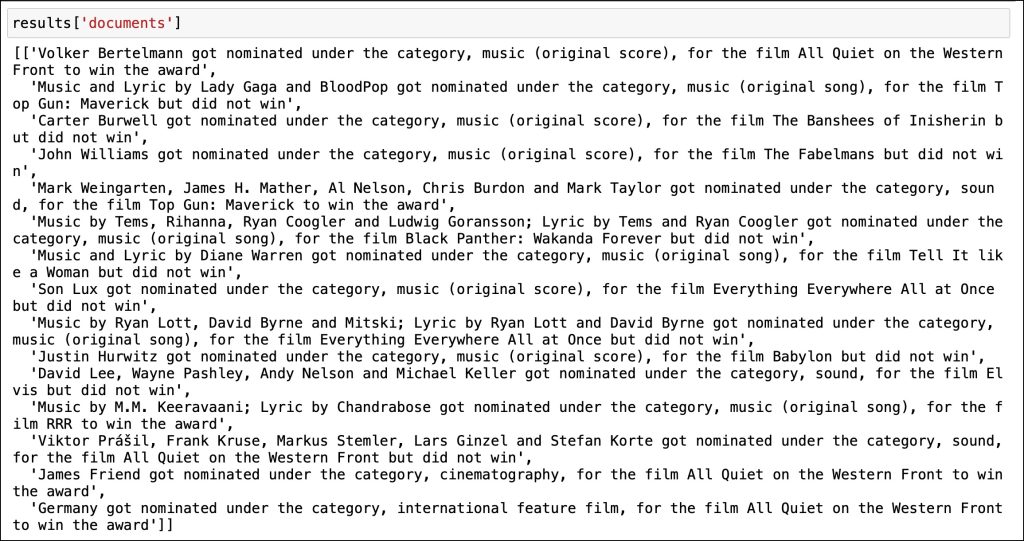
让我们将此列表转换为一个字符串,以为提示提供上下文。

res = "\n".join(str(item) for item in results['documents'][0])是时候根据上下文构建提示并将其发送到OpenAI了。
prompt = f'```{res}```Based on the data in ```, answer who won the award for the original song' messages = [
{"role": "system", "content": "You answer questions about 95th Oscar awards."},
{"role": "user", "content": prompt}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0
)
response_message = response["choices"][0]["message"]["content"]响应包括基于上下文和提示的组合得出的正确回答。

本教程演示了如何利用诸如 Chroma 之类的向量数据库来实现检索增强生成(RAG),以通过额外的上下文增强提示。
以下是完整的代码,供您探索:
import pandas as pd
import openai
import chromadb
from chromadb.utils import embedding_functions
import os
df=pd.read_csv('./data/oscars.csv')
df=df.loc[df['year_ceremony'] == 2023]
df=df.dropna(subset=['film'])
df['category'] = df['category'].str.lower()
df['text'] = df['name'] + ' got nominated under the category, ' + df['category'] + ', for the film ' + df['film'] + ' to win the award'
df.loc[df['winner'] == False, 'text'] = df['name'] + ' got nominated under the category, ' + df['category'] + ', for the film ' + df['film'] + ' but did not win'
def text_embedding(text) -> None:
response = openai.Embedding.create(model="text-embedding-ada-002", input=text)
return response["data"][0]["embedding"]
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ["OPENAI_API_KEY"],
model_name="text-embedding-ada-002"
)
client = chromadb.Client()
collection = client.get_or_create_collection("oscars-2023",embedding_function=openai_ef)
docs=df["text"].tolist()
ids= [str(x) for x in df.index.tolist()]
collection.add(
documents=docs,
ids=ids
)
vector=text_embedding("Nominations for music")
results=collection.query(
query_embeddings=vector,
n_results=15,
include=["documents"]
)
res = "\n".join(str(item) for item in results['documents'][0])
prompt=f'```{res}```who won the award for the original song'
messages = [
{"role": "system", "content": "You answer questions about 95th Oscar awards."},
{"role": "user", "content": prompt}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
temperature=0
)
response_message = response["choices"][0]["message"]["content"]
print(response_message)