极大提高可扩展性 – Apache Kafka 和 OpenTelemetry
极大提高可扩展性 – Apache Kafka 和 OpenTelemetry

译自 SigNoz 博客 Maximizing Scalability - Apache Kafka and OpenTelemetry 。
最近在 CNCF Slack 的 OTel Collector 频道中,一个用户提出了一个问题,这个问题点出了一个我认为以前没有被有效讨论过的重要话题。
为什么您可能需要在架构中运行多个 OpenTelemetry Collector
本文将讨论多 Collector 架构以及 Apache Kafka 在其中可以发挥的作用。
一个用户问:考虑使用像 Kafka 这样的中间传输服务,将应用中的遥测数据转发到 Otel Collector,这种做法合理吗?如果合理,有没有相关的参考实现或文章可以参考?

总体来说,使用队列而不是 Collector 分层更合理,不是吗?(非常感谢 Martin 始终给出帮助性的回答。)
Collector 的作用
简单回顾一下,OpenTelemetry Collector 是 OpenTelemetry 可观测性部署中一个非必需但强烈推荐的组件。Collector 可以收集、压缩、管理和过滤 OpenTelemetry 检测发送的数据,然后再将数据发送到后端。如果发送数据到 SigNoz 后端,那么系统看起来像这样:
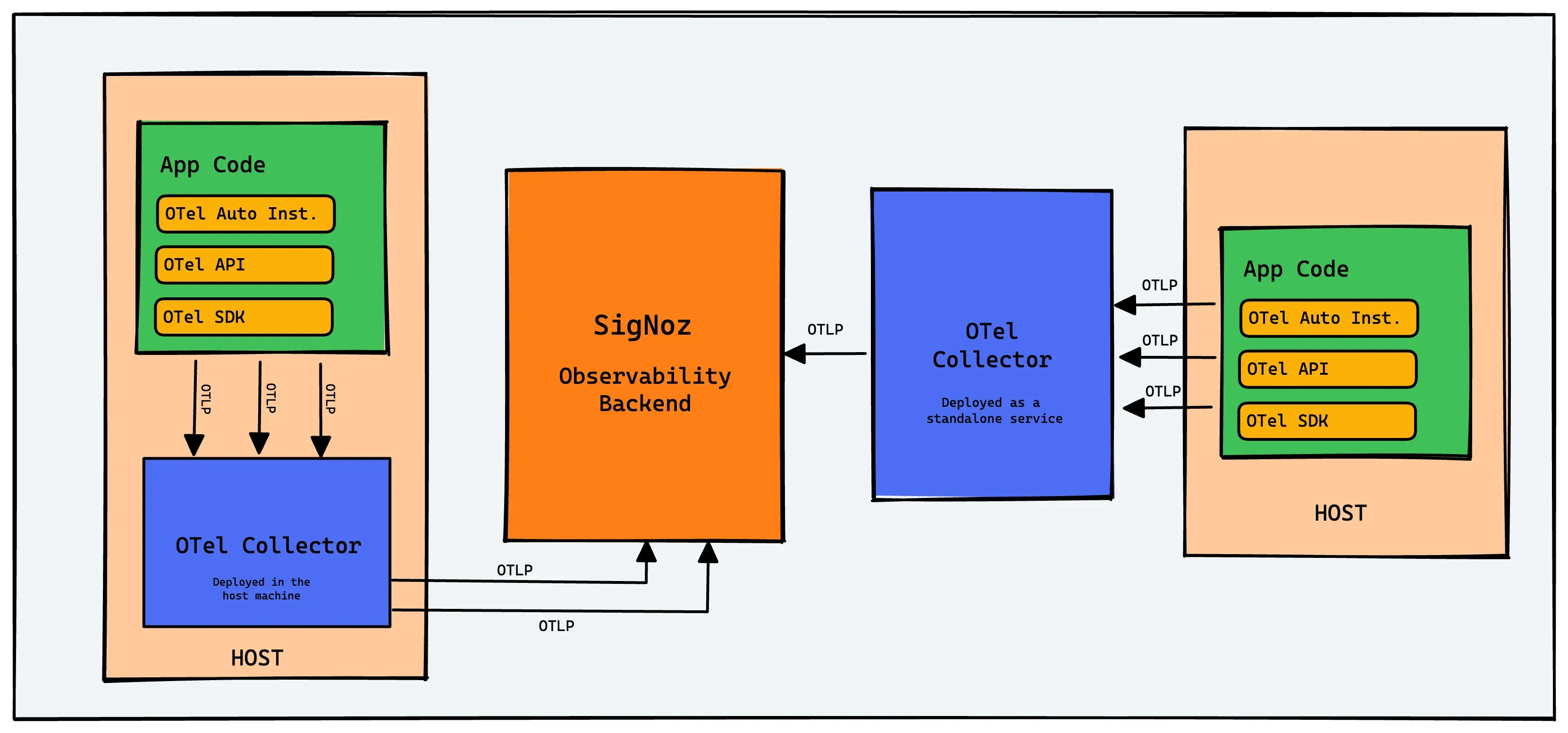
来自 OpenTelemetry 自动 instrumentation 、API 调用和其他使用 OpenTelemetry SDK 检测的代码发送的数据,都会发送到主机上运行的 Collector。
但是,在更高级的情况下,单个 Collector可能不足以满足需求。想象一个边缘服务,它处理高频率的请求,定期向相同网络上的一个较远的 Collector 发送请求。结果是每次请求无法访问 Collector 时,应用就会抛出错误。
同样,Collector 的全部优势在于,无论数据入口频率多高,它都应该能够缓存、批处理和压缩数据进行发送。
多 Collector 架构
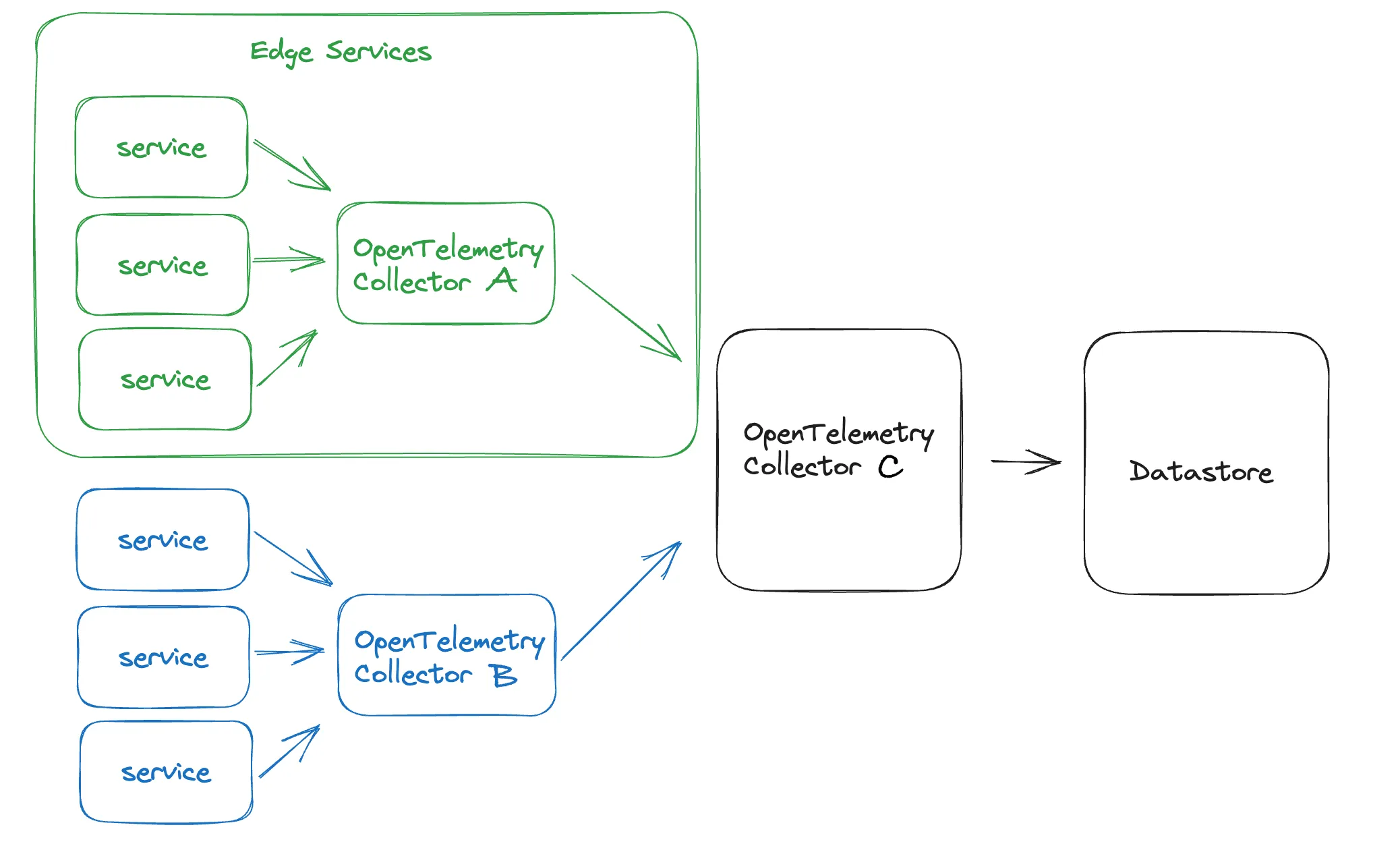
一个近源头的 Collector B 可以可靠地收集数据并批处理,然后发送给第二个中央 Collector C。C Collector 可以从多个其他“前线”Collector 收集数据,然后发送到后端。
这有多个优势:
- 可扩展性:在大规模分布式系统中,单个 OpenTelemetry Collector 可能无法处理所有服务和应用生成的大量遥测数据。
- 减少网络流量:在网络内每多过滤一步,就可以减少用于观测的网络带宽。
- 过滤和采样:通过多层方法,中间 Collector 可以在转发数据到中央 Collector 前执行过滤、转换或采样。这样靠近微服务的团队可以完成数据处理,他们更清楚哪些数据需要突出显示。另外,如果多个服务存在敏感隐私数据问题,可以在中央 Collector 设置过滤,以确保规则得以全面遵守。
在 OTLP 数据中使用 Kafka 队列
在上面的 Slack 讨论中,提出的解决方案是使用 Kafka 队列等。这可以非常可靠地接收事件,几乎不会引发错误。内部队列和 Collector 对 Collector 架构都是提高观测数据可靠性的方法。Kafka 队列最适合以下两种数据场景:
- 数据库宕机期间确保数据收集 - 即使是可靠的数据库也会失败,Kafka 可以在宕机期间接收和存储数据。当数据库恢复后,消费者就可以再次开始获取数据。
- 处理流量突发峰值 - 可观测数据会在使用量激增时大幅增长,如果进行深度跟踪,增长规模可能远超流量增长。如果不使用队列就扩展数据库来处理流量激增,那么在正常流量下数据库会过度配置。队列可以缓冲数据激增,让数据库在准备好时进行处理。
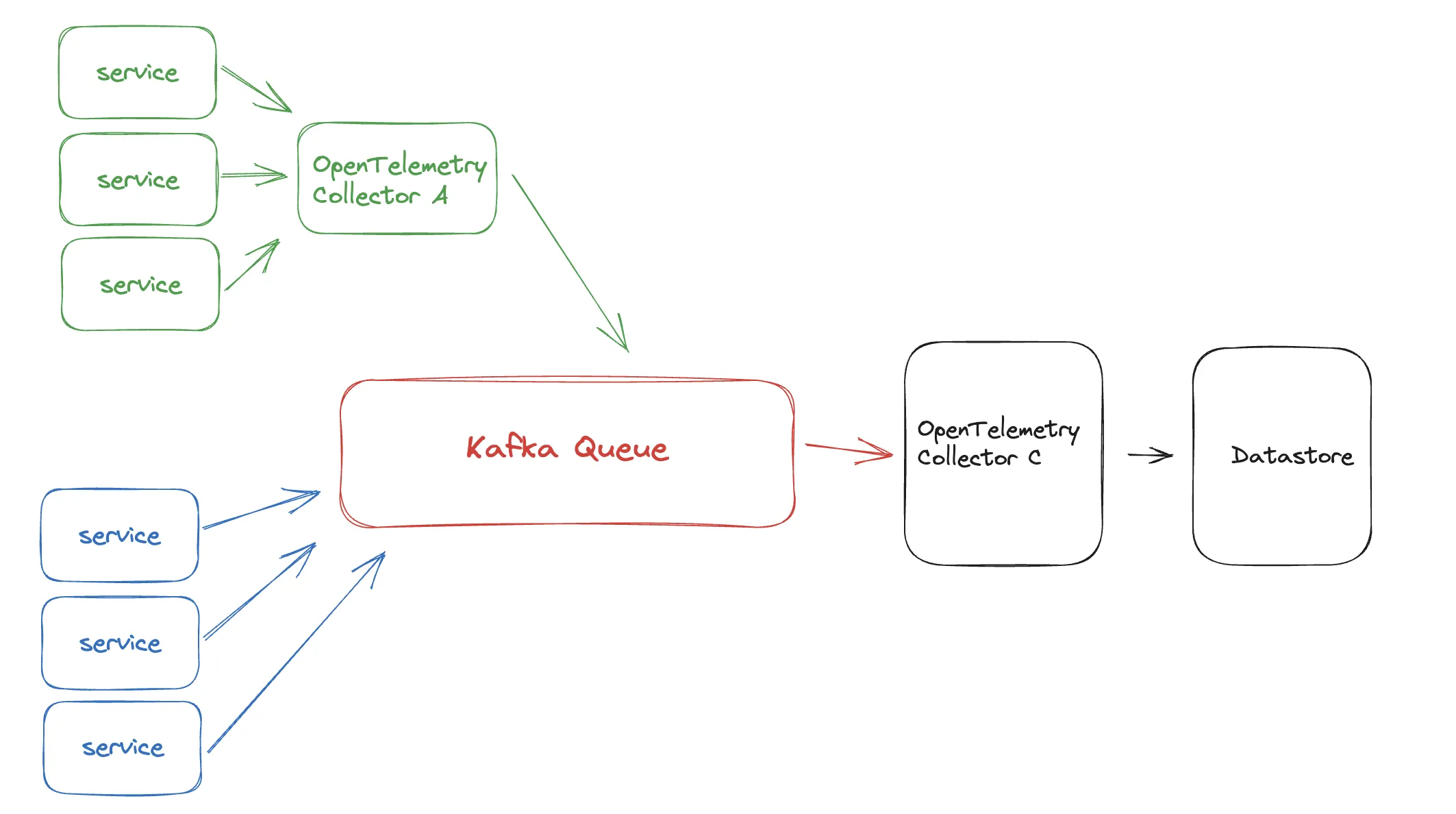
在这个新版本中,Kafka 队列从边缘附近的 Collector 接收数据。服务也可以直接发布到 Kafka。Collector C 使用 OTel Kafka 接收器从队列读取数据。有关从 Kafka 接收数据选项的详情,请参考 OpenTelemetry Collector Contrib 仓库中的 Kafka 接收器。
中间 Collector YAML 配置
实施多 Collector 的过程应该很简单。如果从零开始,需要为服务 A、中间 Collector B 和中央 Collector C 进行以下配置:
服务 YAML 配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: intermediate-collector
labels:
app: intermediate-collector
spec:
replicas: 1
selector:
matchLabels:
app: intermediate-collector
template:
metadata:
labels:
app: intermediate-collector
spec:
containers:
- name: intermediate-collector
image: your-intermediate-collector-image:latest
ports:
- containerPort: 55678 #替换为适当的端口号中间 Collector YAML 配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: intermediate-collector
labels:
app: intermediate-collector
spec:
replicas: 1
selector:
matchLabels:
app: intermediate-collector
template:
metadata:
labels:
app: intermediate-collector
spec:
containers:
- name: intermediate-collector
image: your-intermediate-collector-image:latest
ports:
- containerPort: 55678 #替换为适当的端口号中央 Collector YAML 配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: central-collector
labels:
app: central-collector
spec:
replicas: 1
selector:
matchLabels:
app: central-collector
template:
metadata:
labels:
app: central-collector
spec:
containers:
- name: central-collector
image: your-central-collector-image:latest
ports:
- containerPort: 55678 #替换为适当的端口号中间 Collector 将使用 OTLP 把遥测数据发送给中央 Collector。
结论:Kafka 和 OpenTelemetry Collector 可良好协作
OpenTelemetry Collector 和 Apache Kafka 之间的选择并非仅此一途。它们各有独特优势,在某些架构中甚至可以相互补充。OpenTelemetry Collector 在数据收集、压缩和过滤方面表现强劲,这使它成为减少系统内延迟和提升数据质量的有力选择。
Apache Kafka 在高可靠性和数据缓冲方面发挥重要作用,如数据库宕机或流量激增期间。Kafka 的强大队列机制可充当有价值的中间件,确保不会丢失任何数据,避免数据库过度配置。
所讨论的多 Collector 架构提供了一种可扩展和高效的方式来处理大量遥测数据。通过使 Collector 更接近被监控服务,可以减少网络流量并实现更有效的数据过滤。此架构通过集成 Kafka 队列可以得到进一步增强,从而增加另一层可靠性和可扩展性。