【动手学深度学习】深入浅出深度学习之PyTorch基础
【动手学深度学习】深入浅出深度学习之PyTorch基础

- 正确理解深度学习所需的数学知识;
- 学习一些关于数据的实用技能,包括存储、操作和预处理数据;
- 能够完成各种数据操作,存储和操作数据;
- PyTorch基础,完成《动?学深度学习》预备知识2.1-2.5节的课后练习。
?二、实验准备
- 根据GPU安装pytorch版本实现GPU运行实验代码;
- 配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
?三、实验内容
资源获取:关注公众号【科创视野】回复? 深度学习
启动jupyter notebook,使用新增的pytorch环境新建ipynb文件,为了检查环境配置是否合理,输入import torch以及torch.cuda.is_available() ,若返回TRUE则说明实验环境配置正确,若返回False但可以正确导入torch则说明pytorch配置成功,但实验运行是在CPU进行的,结果如下:
import torch
torch.cuda.is_available() 输出结果:
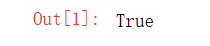
?1?数据操作
(1)使用jupyter notebook新增的pytorch环境新建ipynb文件,完成基本数据操作的实验代码与练习结果如下:
?1.1 入门
import torch
x = torch.arange(12)
x输出结果:
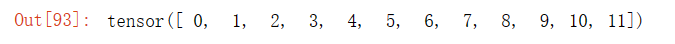
x.shape输出结果:
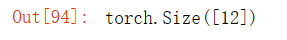
x.numel()输出结果:

X = x.reshape(3, 4)
X输出结果:

torch.zeros((2, 3, 4))输出结果:

torch.ones((2, 3, 4))输出结果:

torch.randn(3, 4)输出结果:

torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])输出结果:

?1.2?运算符
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算输出结果:

torch.exp(x)输出结果:
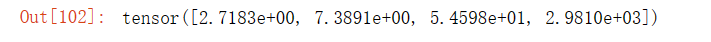
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)输出结果:

X == Y输出结果:

X.sum()输出结果:

?1.3 广播机制
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a, b输出结果:

a + b输出结果:

?1.4 索引和切片
X[-1], X[1:3]输出结果:

X[1, 2] = 9
X输出结果:

X[0:2, :] = 12
X输出结果:

?1.5?节省内存
before = id(Y)
Y = Y + X
id(Y) == before输出结果:
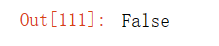
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))输出结果:
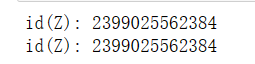
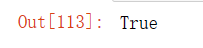
before = id(X)
X += Y
id(X) == before输出结果:
?1.6?转换为其他Python对象
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)输出结果:
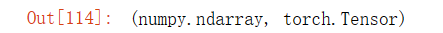
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)输出结果:
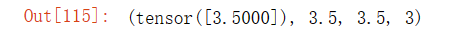
?1.7?小结
深度学习存储和操作数据的主要接口是张量((n)维数组)。它提供了各种功能,包括基本数学运算、广播、索引、切片、内存节省和转换其他Python对象。
?1.8 练习
1.运行本节中的代码。将本节中的条件语句X == Y更改为X < Y或X > Y,然后看看你可以得到什么样的张量。
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])X<Y输出结果:
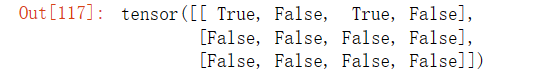
X>Y输出结果:

2.用其他形状(例如三维张量)替换广播机制中按元素操作的两个张量。结果是否与预期相同?
a = torch.arange(3).reshape((3, 1))
b = torch.arange(3).reshape((1, 3))
a, b输出结果:

a+b输出结果:

?2. 数据预处理
(1)完成数据预处理的实验代码及练习内容如下:
?2.1 读取数据集
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每行表示一个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
# 如果没有安装pandas,只需取消对以下行的注释来安装pandas
# !pip install pandas
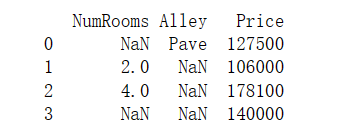
import pandas as pd
data = pd.read_csv(data_file)
print(data)输出结果:
?2.2 处理缺失值
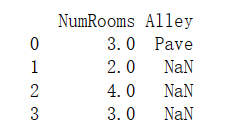
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)输出结果:
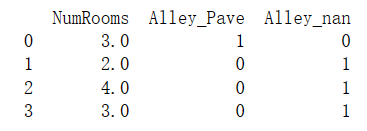
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)输出结果:
?2.3 转换为张量格式
import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
X, y输出结果:

?2.4 小结
1.pandas软件包是Python中常用的数据分析工具中,pandas可以与张量兼容。 2.用pandas处理缺失的数据时,我们可根据情况选择用插值法和删除法。
?2.5?练习
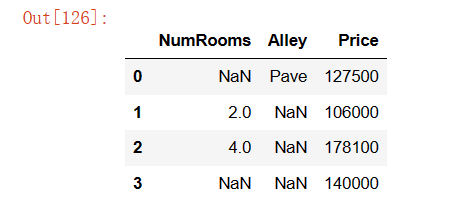
1.创建包含更多行和列的原始数据集。
data1 = pd.read_csv(data_file)
data1输出结果:
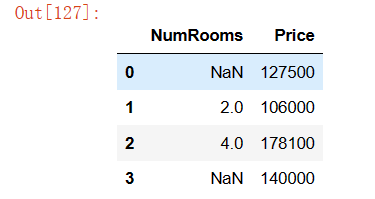
2.删除缺失值最多的列。
nan_numer = data1.isnull().sum(axis=0)
nan_max_id = nan_numer.idxmax()
data1 = data1.drop([nan_max_id], axis=1)
data1输出结果:
3.将预处理后的数据集转换为张量格式。
data2 = torch.tensor(data1.values)
data2输出结果:

?3 线性代数
?3.1?标量
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
x + y, x * y, x / y, x**y输出结果:
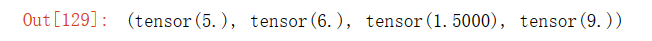
?3.2?向量
x = torch.arange(4)
x输出结果:
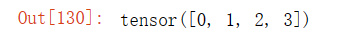
x[3]输出结果:

len(x)输出结果:
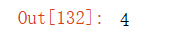
x.shape输出结果:
?3.3 矩阵
A = torch.arange(20).reshape(5, 4)
A输出结果:

A.T输出结果:

B = torch.tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B输出结果:

B == B.T输出结果:

?3.4 张量
X = torch.arange(24).reshape(2, 3, 4)
X输出结果:

?3.5 张量算法的基本性质
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B输出结果:
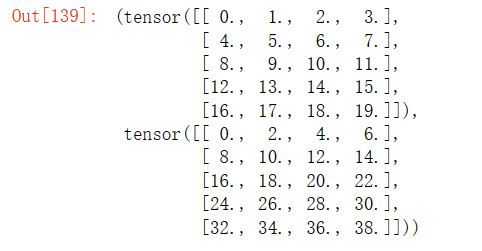
A * B输出结果:

a = 2
X = torch.arange(24).reshape(2, 3, 4)
a + X, (a * X).shape输出结果:

?3.6 降维
x = torch.arange(4, dtype=torch.float32)
x, x.sum()输出结果:
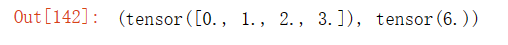
A.shape, A.sum()输出结果:
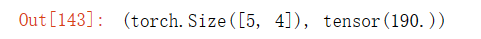
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape输出结果:
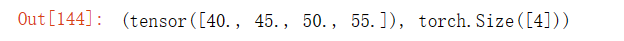
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape输出结果:
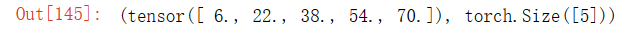
A.sum(axis=[0, 1]) # 结果和A.sum()相同输出结果:
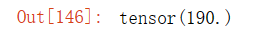
A.mean(), A.sum() / A.numel()输出结果:
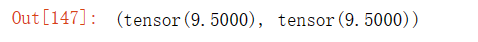
A.mean(axis=0), A.sum(axis=0) / A.shape[0]输出结果:
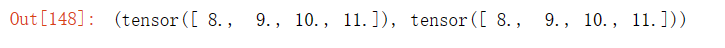
# 2.3.6.1. 非降维求和
sum_A = A.sum(axis=1, keepdims=True)
sum_A输出结果:

A / sum_A输出结果:

A.cumsum(axis=0)输出结果:

?3.7 点积
y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y)输出结果:

torch.sum(x * y)输出结果:
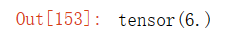
?3.8 矩阵-向量积m
A.shape, x.shape, torch.mv(A, x)输出结果:

?3.9 矩阵-矩阵乘法
B = torch.ones(4, 3)
torch.mm(A, B)输出结果:

?3.10 范数
u = torch.tensor([3.0, -4.0])
torch.norm(u)输出结果:

torch.abs(u).sum()输出结果:
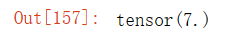
torch.norm(torch.ones((4, 9)))输出结果:

?3.11 练习
1.证明一个矩阵
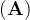
的转置的转置是
,即
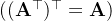
。

2.给出两个矩阵
和
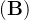
,证明“它们转置的和”等于“它们和的转置”,即
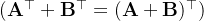
。
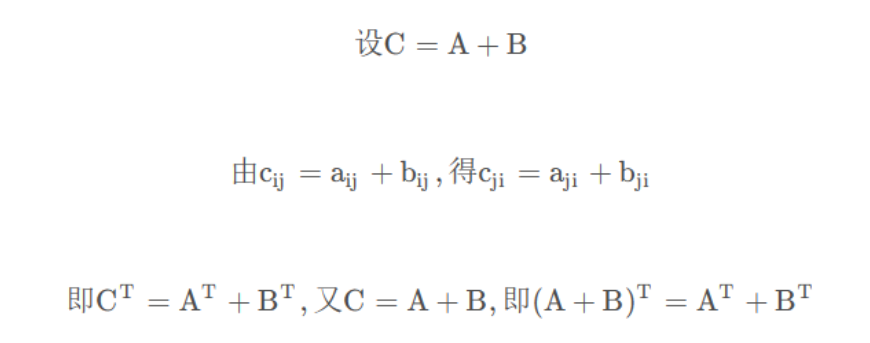
3.给定任意方阵
,
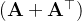
总是对称的吗?为什么?
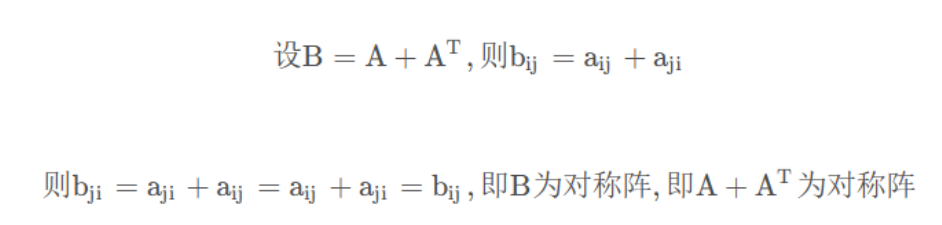
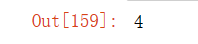
4.本节中定义了形状((2,3,4))的张量X。len(X)的输出结果是什么?
X = torch.arange(24).reshape(2, 3, 4)
len(x)输出结果:
5.对于任意形状的张量X,len(X)是否总是对应于X特定轴的长度?这个轴是什么?
对应axis=0这个轴
6.运行A/A.sum(axis=1),看看会发生什么。请分析一下原因?
# 运行运行A/A.sum(axis=1)是会报错的,是广播机制的原因,但是我们可以顺利运行A/A.sum(axis=1, keepdim=True),
# 我们可以来做个实验,实验中我们可以看到沿着不同的轴进行计算会有不同结果且写的方法不同,在axis≠0时一般需要加上keepdim=True
import torch
A = torch.ones((3, 4))
B = A/A.sum(axis=1, keepdim=True)
C = A/A.sum(axis=0)
B, C输出结果:

7.考虑一个具有形状((2,3,4))的张量,在轴0、1、2上的求和输出是什么形状?
# 形状分别为[3, 4],[2, 4],[2, 3]
import torch
A = torch.ones((2, 3, 4))
B = A.sum(axis=0)
C = A.sum(axis=1)
D = A.sum(axis=2)
B.size(), C.size(), D.size()输出结果:
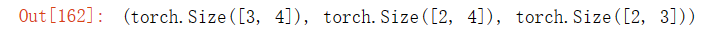
8.为linalg.norm函数提供3个或更多轴的张量,并观察其输出。对于任意形状的张量这个函数计算得到什么?
import torch
A = torch.ones((3,4))
torch.linalg.norm(A)输出结果:
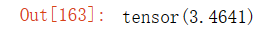
?4 微积分
?4.1 导数和微分
# matplotlib inline
import numpy as np
from matplotlib_inline import backend_inline
from d2l import torch as d2l
def f(x):
return 3 * x ** 2 - 4 * x
def numerical_lim(f, x, h):
return (f(x + h) - f(x)) / h
h = 0.1
for i in range(5):
print(f'h={h:.5f}, numerical limit={numerical_lim(f, 1, h):.5f}')
h *= 0.1输出结果:

?4.2 练习
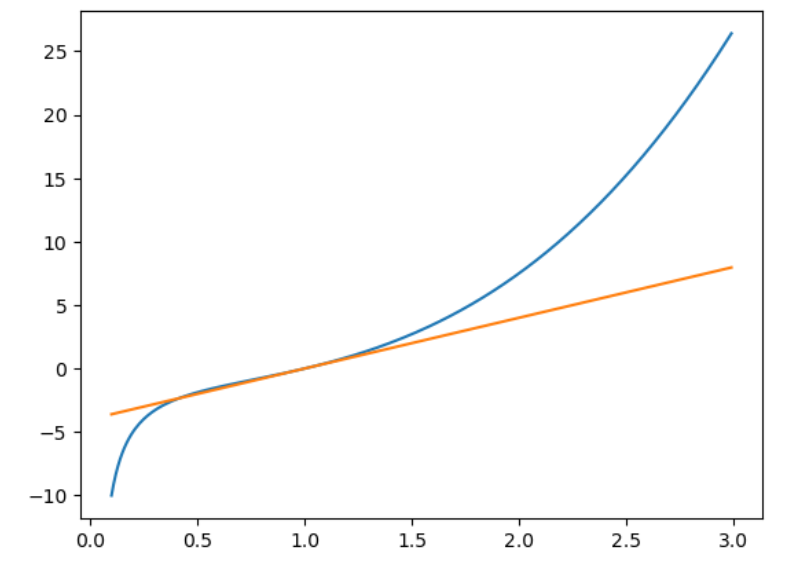
1.绘制函数(y = f(x) = x^3 - \frac{1}{x})和其在(x = 1)处切线的图像。
import numpy as np
from matplotlib import pyplot as plt
def get_function(x):
return x**3 - 1/x
def get_tangent(function, x, point):
h = 1e-4
grad = (function(point+h) - function(point)) / h
return grad*(x-point) + function(point)
x = np.arange(0.1,3.0,0.01)
y = get_function(x)
y_tangent = get_tangent(get_function, x=x, point=1)
plt.plot(x,y)
plt.plot(x,y_tangent)
plt.show()输出结果:
2.求函数
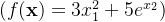
的梯度。
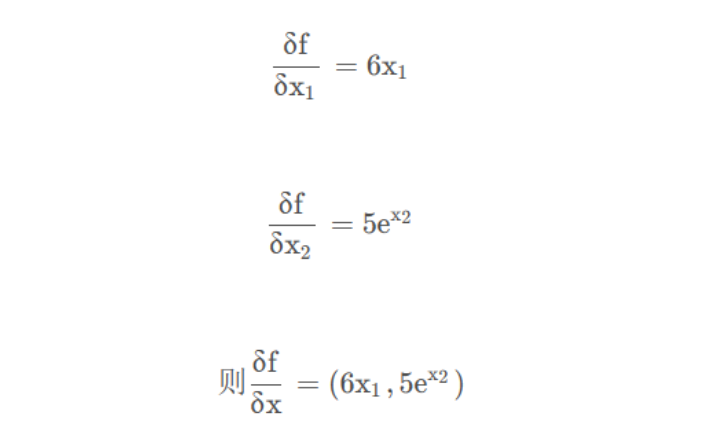
3.函数
的梯度是什么?
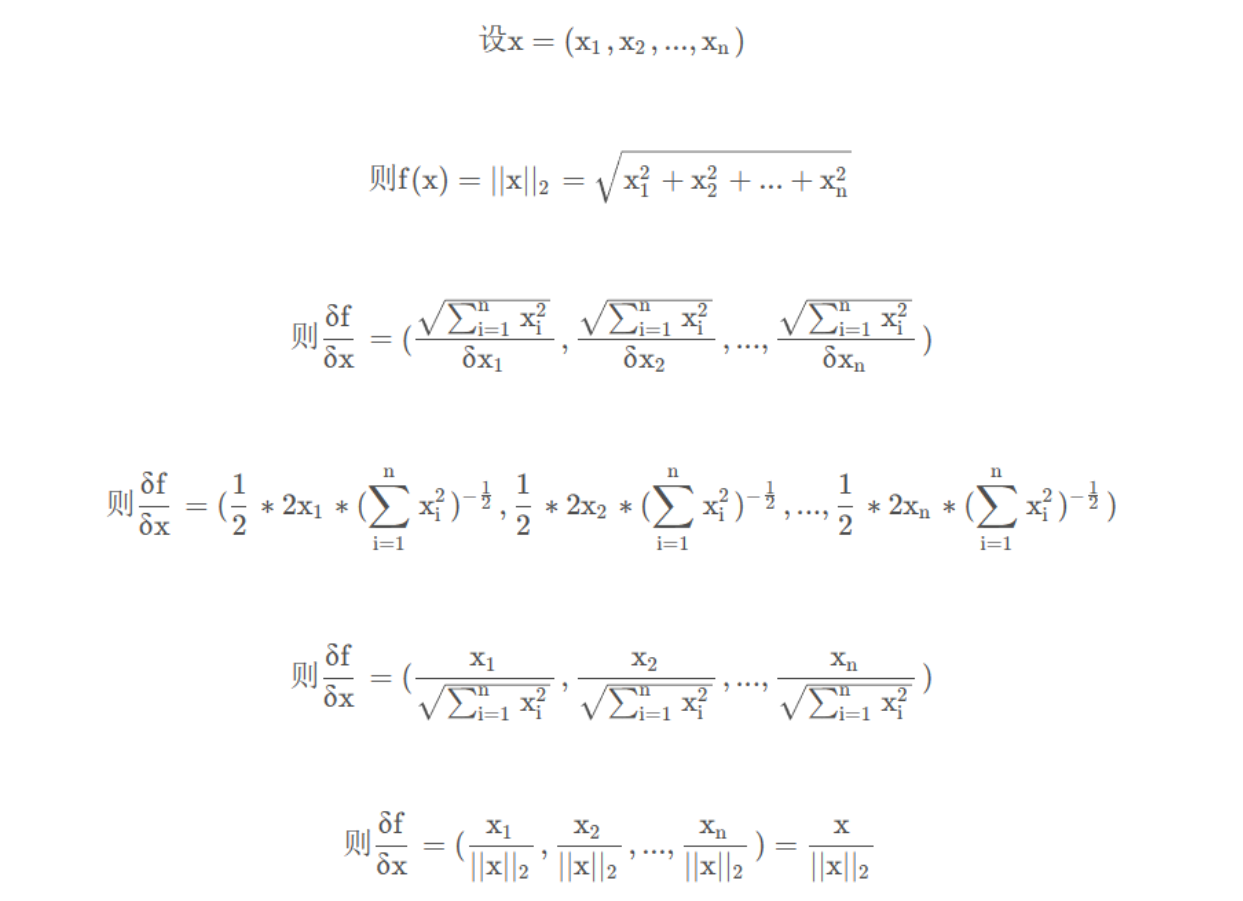
4.尝试写出函数
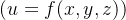
,其中(x = x(a, b)),(y = y(a, b)),(z = z(a, b))的链式法则。
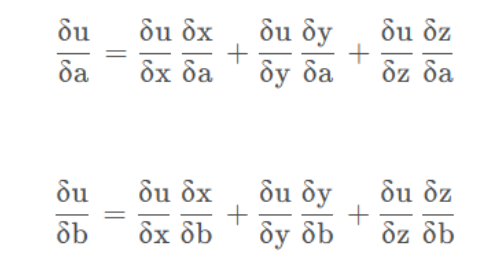
?5?自动微分
?5.1?一个简单的例子
import torch
x = torch.arange(4.0)
x输出结果:
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None
y = 2 * torch.dot(x, x)
y输出结果:

y.backward()
x.grad输出结果:
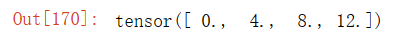
x.grad == 4 * x输出结果:
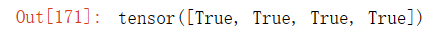
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()
x.grad输出结果:
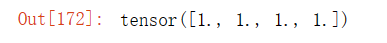
?5.2 非标量变量的反向传播
# 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
# 本例只想求偏导数的和,所以传递一个1的梯度是合适的
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad输出结果:
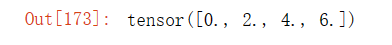
?5.3 分离计算
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u输出结果:

x.grad.zero_()
y.sum().backward()
x.grad == 2 * x输出结果:
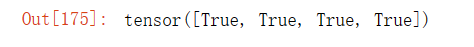
?5.4?Python控制流的梯度计算
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
a.grad == d / a输出结果:
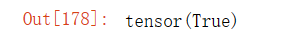
?5.5 小结
深度学习框架可以自动计算导数:我们首先将梯度附加到想要对其计算偏导数的变量上,然后记录目标值的计算,执行它的反向传播函数,并访问得到的梯度。
?5.6 练习
1.为什么计算二阶导数比一阶导数的开销要更大?
# 二阶导数是一阶导数的导数,计算二阶导数需要用到一阶导数,所以开销会比一阶导数更大2.在运行反向传播函数之后,立即再次运行它,看看会发生什么。
# 会报错,因为进行一次backward之后,计算图中的中间变量在计算完后就会被释放,之后无法进行二次backward了,
# 如果想进行第二次backward,可以将retain_graph置为True,实验如下
①retain_graph默认为False
import torch
x = torch.randn((2, 3), requires_grad=True)
y = torch.square(x) - 1
loss = y.mean()
loss.backward()
loss.backward()输出结果:

# retain_graph置为True
import torch
x = torch.randn((2, 3), requires_grad=True)
y = torch.square(x) - 1
loss = y.mean()
print(x)
loss.backward(retain_graph=True)
print(x.grad)
loss.backward()
print(x.grad)输出结果:

3.在控制流的例子中,我们计算d关于a的导数,如果将变量a更改为随机向量或矩阵,会发生什么?
# 将变量a更改为随机向量或矩阵,会报错,原因可能是在执行 loss.backward() 时没带参数,
# 即可能默认是与 loss.backward(torch.Tensor(1.0)) 相同的,可以尝试如下的实验实验如下
import torch
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn((3), requires_grad=True)
d = f(a)
d.backward()输出结果:
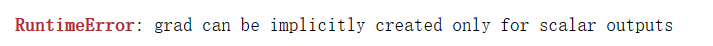
import torch
a = torch.randn((3), requires_grad=True)
d = a**2
print(a)
d.backward(torch.ones_like(d))
print(a.grad)
a = torch.randn((3), requires_grad=True)
d = f(a)
print(a)
d.backward(torch.ones_like(d))
print(a.grad)
torch.tensor([ 0.7534, -1.3026, -1.2577], requires_grad=True)
torch.tensor([51200., 51200., 51200.])
a = torch.randn((2, 3), requires_grad=True)
d = f(a)
print(a)
d.backward(torch.ones_like(d))
print(a.grad)
torch.tensor([[-2.0677, -1.0871, 0.1289],
[ 0.4897, -0.4152, 0.2643]], requires_grad=True)
torch.tensor([[51200., 51200., 51200.],
[51200., 51200., 51200.]])输出结果:
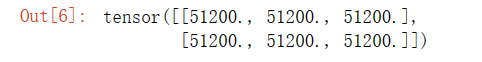
4.重新设计一个求控制流梯度的例子,运行并分析结果。
import torch
def f(x, order):
if order == 1:
y = torch.sqrt(x)
elif order == 2:
y = torch.square(x)
else:
return x
return y
x = torch.randn(size=(), requires_grad=True)
print(x)
y = f(x, order=1)
y.backward()
print(x.grad)
x.grad.zero_() # 清除梯度
y = f(x, order=2)
y.backward()
print(x.grad)输出结果:

torch.tensor(-1.2684, requires_grad=True)
torch.tensor(-2.5369)输出结果:
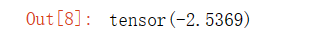
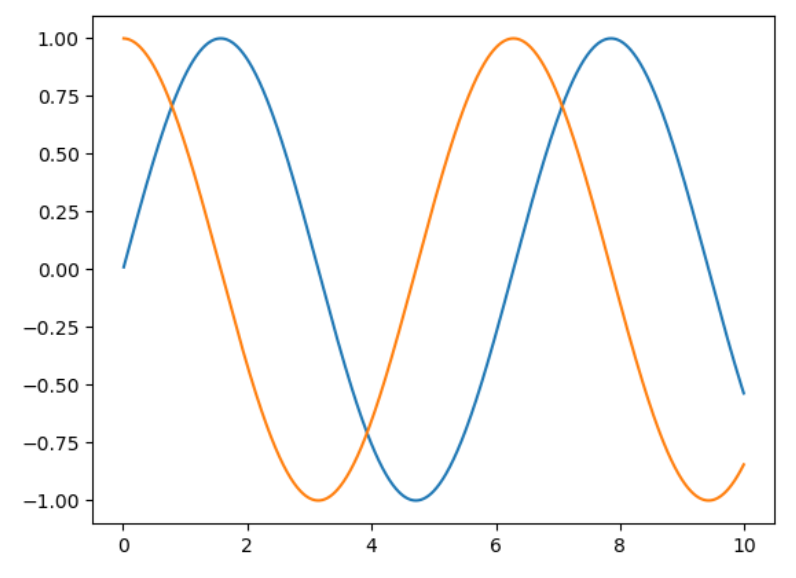
5.使
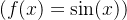
,绘制
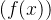
和
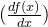
的图像,其中后者不使用
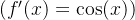
。
import numpy as np
from matplotlib import pyplot as plt
def get_function(x):
return np.sin(x)
def get_derivative(function, x):
h = 1e-4
return (function(x+h) - function(x)) / h
x = np.arange(0.01,10.0,0.01)
y = get_function(x)
y_derivative = get_derivative(get_function, x)
plt.plot(x,y)
plt.plot(x,y_derivative)
plt.show()输出结果:
?四、实验心得
通过这次实验,我对深度学习的数据处理知识有了更深入的了解。尽管在安装PyTorch的过程中遇到了一些问题(由于conda默认安装了CPU版本的PyTorch),但在删除numpy库后成功地安装了GPU版本的PyTorch。并且我对以下内容有了更深刻的理解:
1.张量(n维数组)是深度学习存储和操作数据的主要接口。它提供了广泛的功能,包括基本数学运算、广播、索引、切片,还可以实现内存节省和转换其他Python对象。 2.pandas是Python中常用的数据分析工具之一,它与张量兼容,为数据处理提供了便利。 3.在处理缺失数据时,pandas提供了多种方法,根据情况可以选择插值法或删除法进行处理。 4.标量、向量、矩阵和张量是线性代数中的基本数学对象。 5.向量是标量的推广,矩阵是向量的推广。 6.标量、向量、矩阵和张量分别具有零、一、二和任意数量的轴。 7.通过使用sum和mean等操作,可以沿指定的轴降低张量的维度。 8.两个矩阵的按元素乘法被称为Hadamard积,与矩阵乘法不同。 9.在深度学习中,常常使用范数,如L1范数、L2范数和Frobenius范数。 10.微分和积分是微积分的两个分支,其中微分在深度学习的优化问题中得到了广泛应用。 11.导数可以被理解为函数相对于其变量的瞬时变化率,同时是函数曲线的切线斜率。 12.梯度是一个向量,其分量是多变量函数相对于所有变量的偏导数。 13.链式法则可以用于求解复合函数的导数。 14.深度学习框架能够自动计算导数:首先将梯度附加到需要计算偏导数的变量上,然后记录目标值的计算过程,执行反向传播函数,并获得相应的梯度。