大模型与AI底层技术揭秘(31)令狐冲化身酒剑仙
大模型与AI底层技术揭秘(31)令狐冲化身酒剑仙

上期我们说到令狐冲在思过崖了解到了剑宗与气宗的区别,武功很快就有了质的飞跃,消灭了大boss东方不败,跟任盈盈携手隐居在山清水秀的杭州,将饮酒与练剑作为日常娱乐项目,最终得道成仙。
有一天,令狐冲晚上酒后散步,在余杭郊外的十里坡遇到了一个年轻人,并教会了年轻人一点点剑法。

这位年轻人从令狐冲这里学会了“御剑术”以后,又自己领悟了万剑诀、剑神和酒神,最终与灵儿、月如和阿奴一起,走遍中国,来到苗疆,击败了拜月教主,让甘霖洒遍苗疆大地,天下重归和平……
小H正在梦里化身李逍遥,并有3个美女陪伴,被闹钟叫醒了,原来是最近游戏玩太多了。
不过,从小H脑洞大开的梦里面,大家也想到了,从GPU厂商的虚拟化方案中吸收营养,在容器平台上实现GPU虚拟化的一些思路。
在上期,我们提到,容器技术出现后,在操作系统对处理器进行时分复用的能力的基础上,增加了安全隔离机制,能够实现较为安全的计算资源复用。因此,使用以Docker和Kubernetes为代表的容器技术,让多个进程复用物理GPU,实现GPU的虚拟化,也成为了互联网云厂商的一个研究方向。
最初尝试使用容器技术实现GPU虚拟化的方案之一,是腾讯云的TKE。TKE是Tencent Kubernetes Engine的缩写,在腾讯云上为用户提供服务的同时,也对外提供开源版本TKEStack。业界也有灵雀云ACP这样的从TKEStack衍生出的第三方容器平台。
TKE的早期版本,借鉴了NVidia vGPU的实现思路,使用CUDA劫持技术实现了GPU虚拟化。
它的实现原理如下图:
首先,TKE会在容器工作节点上安装gpu-manager-daemonset,它是个k8s device plugin,实现的是GPU拓扑感知、设备和驱动映射。同时,它还可以将一个GPU调度给多个应用使用。
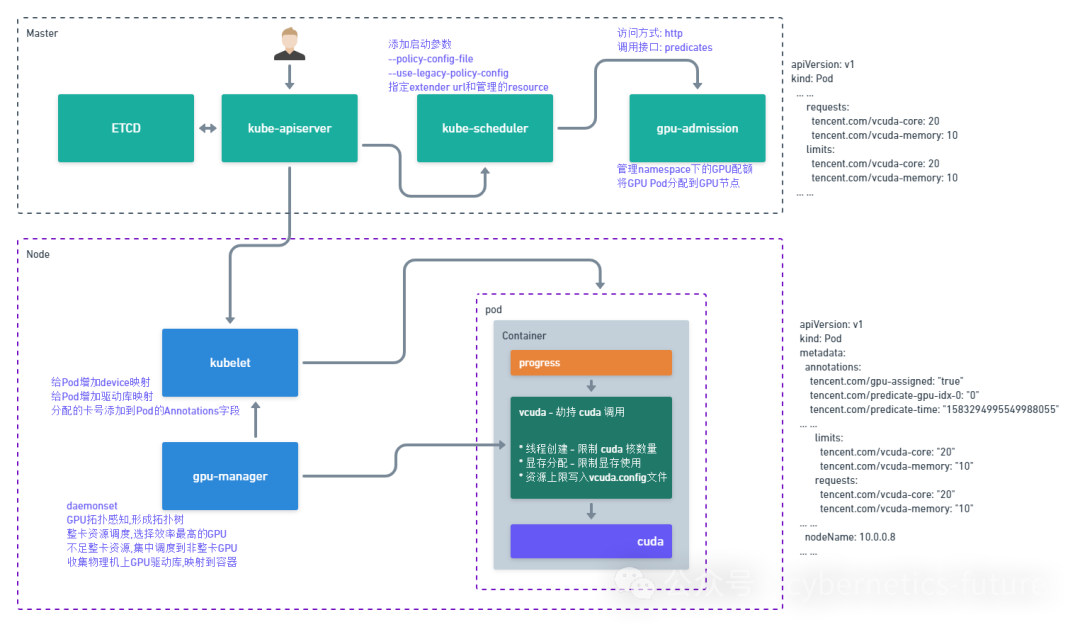
在Kubernetes的Master节点上,也增加一个组件,叫做gpu-admission,其作用是接管Kubernetes Scheduler的predicates功能,如果Pod请求了vcuda-core资源,gpu-admission就会去给它分配GPU的时间片配额。
在工作节点的操作系统上,使用vcuda替代cuda库,通过把libcuda.so等关键调用库被替换为软链接,实现了劫持容器内用户程序的cuda调用。vcuda会进行GPU资源的QoS,对Pod进程限制GPU计算和显存的使用,同时进行数据采集监控,最后调用真实的CUDA。
TKE GPU Manager+vcuda的方案的优势在于:
- 能感知到GPU拓扑,提供最优的调度策略,例如优先分配已开箱的GPU,保证大颗粒度请求能够尽量成功;
- 对用户应用无侵入式修改,完全透明;
- 调度颗粒度很细,可以到0.1 GPU的颗粒度(甚至比NVidia原厂的MIG方案更优)提升了GPU资源利用率
但是,TKE GPU Manager+vcuda的方案也有一些劣势和缺陷。
与虚拟机上运行vcuda类似,替换的vcuda库的版本是需要和原cuda版本兼容的。如果计算节点没有使用cuda库,而是使用OpenGL等库,这个方案就无法起到作用了。此外,由于这个方案修改了数据平面关键路径,每个调用都要被劫持重定向,会造成大约5%的性能损耗。
业界还有其他类似的方案,如百度的MPS等,但只要是使用cuda劫持技术,都会有类似的优缺点。
如何规避cuda劫持技术的缺点,实现更好的容器平台GPU虚拟化方案呢?
请看下期。