第一个基于 Llama-3 的多模态大模型, Bunny-Llama-3-8B-V 正式上线
第一个基于 Llama-3 的多模态大模型, Bunny-Llama-3-8B-V 正式上线

CV君
发布于 2024-04-25 18:41:04
发布于 2024-04-25 18:41:04
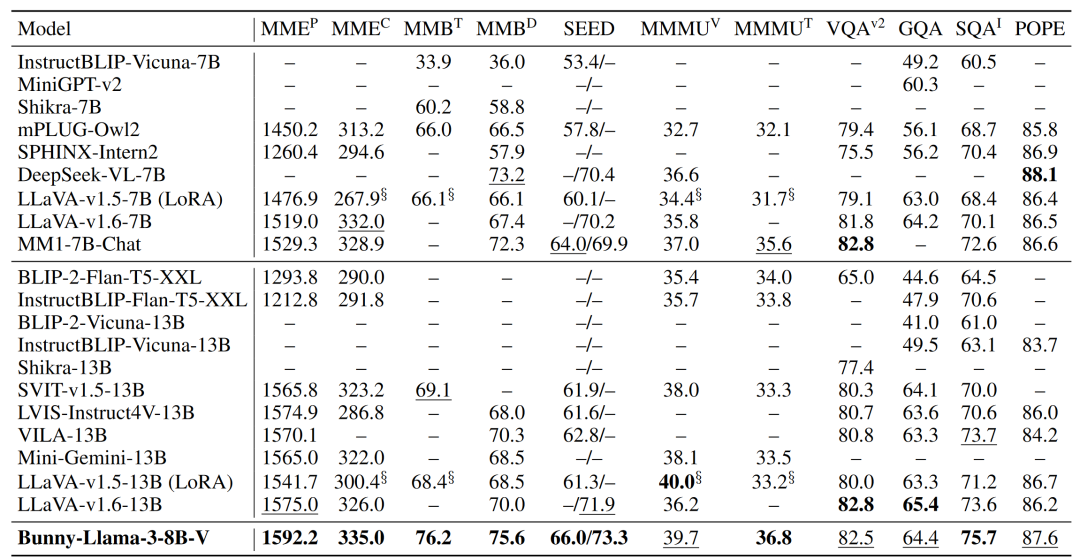
Bunny 团队推出第一个基于 Llama-3 的多模态大模型!Bunny-Llama-3-8B-V 正式上线,超越一众如 LLaVA-7B、LLaVA-13B、Mini-Gemini-13B 模型。在众多主流 Benchmark 上表现良好,具有更好的识别、数学和推理能力。
- 项目主页:https://github.com/BAAI-DCAI/Bunny
Bunny 模型采用了经典的 Encoder+Projector+LLM 架构,提供了一个可扩展的组合框架。支持多种 Vision Encoders,如 EVA CLIP、SigLIP 等,以及多种 LLM Backbone,包括 Phi-1.5、Phi-2、StableLM-2、Llama-3 等。灵活的架构设计便于用户基于Bunny开展大模型研究。
Bunny-Llama-3-8B-V可以精确理解图片并识别物体:

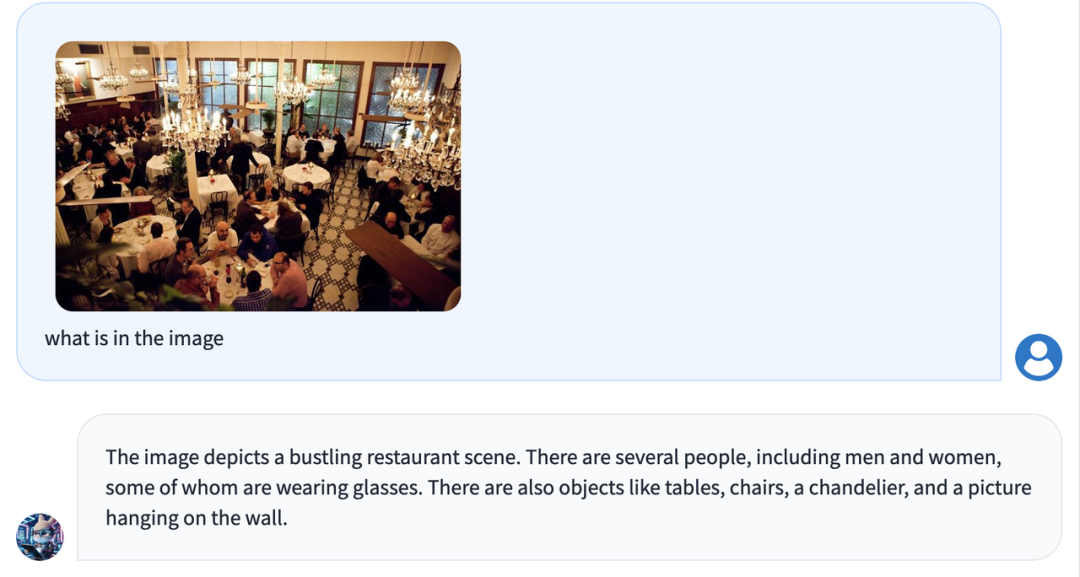
在这个餐厅中,Bunny-Llama-3-8B-V 理解并很好地描述了图片:
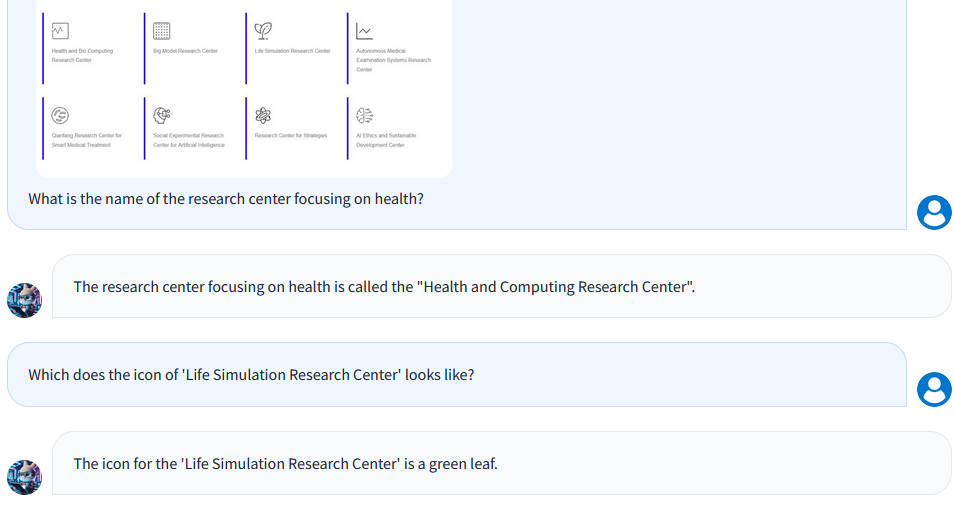
模型也有很强的OCR能力:
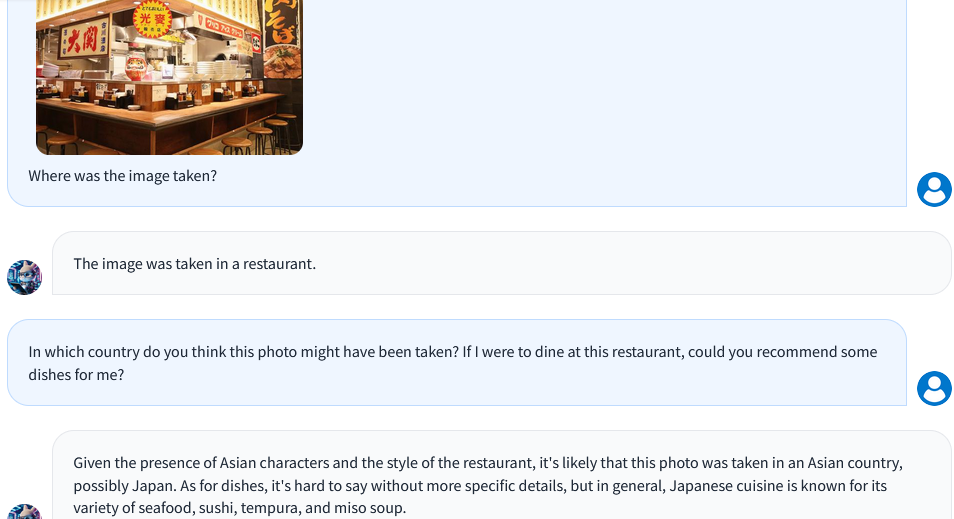
场景理解能力:
在 Bunny 数据集上训练好的 Bunny-Llama-3-8B-V 已经开放下载:
- GitHub: https://github.com/BAAI-DCAI/Bunny
- HuggingFace: https://huggingface.co/BAAI/Bunny-Llama-3-8B-V
- Modelscope: https://modelscope.cn/models/BAAI/Bunny-Llama-3-8B-V
- Wisemodel: https://wisemodel.cn/models/BAAI/Bunny-Llama-3-8B-V
预计会在未来发布性能更强悍的版本,STAY TUNED!
本文参与?腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-04-24,如有侵权请联系?cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读