ΜΣΈΣΩΣ‘¥ GhostNetV3 | ”≈Μ·±Ώ‘ΒΦΤΥψΘ§–‘Ρήœ‘÷χΧα…ΐΓΔ≥§‘Ϋ MobileNet !
ΜΣΈΣΩΣ‘¥ GhostNetV3 | ”≈Μ·±Ώ‘ΒΦΤΥψΘ§–‘Ρήœ‘÷χΧα…ΐΓΔ≥§‘Ϋ MobileNet !


Ϋτ¥’–Ά…ώΨ≠Άχ¬γΧΊ±πΈΣ±Ώ‘Β…η±Η…œΒΡ”Π”ΟΕχ…ηΦΤΘ§’β–©…η±ΗΨΏ”–ΗϋΩλΒΡΆΤάμΥΌΕ»ΒΪ–‘Ρή ÷–ΓΘ»ΜΕχΘ§ΡΩ«ΑΫτ¥’–ΆΡΘ–ΆΒΡ―ΒΝΖ≤Ώ¬‘ «¥”¥ΪΆ≥ΡΘ–ΆΫη”ΟΙΐά¥ΒΡΘ§’βΚω¬‘ΝΥΥϋΟ«‘ΎΡΘ–Ά»ίΝΩ…œΒΡ≤ν“λΘ§“ρ¥ΥΩ…ΡήΜαΉηΑ≠Ϋτ¥’–ΆΡΘ–ΆΒΡ–‘ΡήΓΘ ‘Ύ±ΨΈΡ÷–Θ§Ά®ΙΐœΒΆ≥―–ΨΩ≤ΜΆ§―ΒΝΖ“ΣΥΊΒΡ”ΑœλΘ§Ής’ΏΈΣΫτ¥’–ΆΡΘ–Ά“ΐ»κΝΥ“Μ÷÷«Ω¥σΒΡ―ΒΝΖ≤Ώ¬‘ΓΘΉς’ΏΖΔœ÷Θ§÷Ί–¬≤Έ ΐΜ·ΚΆ÷Σ Ε’τΝσΒΡ Β±…ηΦΤΕ‘―ΒΝΖΗΏ–‘ΡήΫτ¥’–ΆΡΘ–Ά÷ΝΙΊ÷Ί“ΣΘ§Εχ“Μ–©≥Θ”Ο”Ύ―ΒΝΖ¥ΪΆ≥ΡΘ–ΆΒΡ ΐΨί‘ω«ΩΖΫΖ®Θ§»γMixupΚΆCutMixΘ§ΜαΒΦ÷¬–‘Ρήœ¬ΫΒΓΘ Ής’Ώ‘ΎImageNet-1K ΐΨίΦ·…œΒΡ Β―ι±μΟςΘ§Ής’Ώ’κΕ‘Ϋτ¥’–ΆΡΘ–ΆΒΡΉ®“Β―ΒΝΖ≤Ώ¬‘ ”Ο”ΎΗς÷÷ΦήΙΙΘ§Αϋά®GhostNetV2ΓΔMobileNetV2ΚΆShuffleNetV2ΓΘΨΏΧεά¥ΥΒΘ§≈δ±ΗΉς’ΏΒΡ≤Ώ¬‘Θ§GhostNetV3
‘Ύ“ΤΕ·…η±Η…œΫω”Ο269MFLOPsΚΆ14.46msΒΡ―”≥ΌΘ§ΨΆ¥οΒΫΝΥ79.1%ΒΡtop-1ΉΦ»Ζ¬ Θ§¥σΖυ≥§ΙΐΝΥΤδΆ®≥Θ―ΒΝΖΒΡΕ‘”ΠΡΘ–ΆΓΘ¥ΥΆβΘ§Ής’ΏΒΡΙέ≤λΜΙΩ…“‘ά©’ΙΒΫΡΩ±ξΦλ≤β≥ΓΨΑΓΘ ΙΊΉΔΙΪ÷ΎΚ≈Θ§ΥΫ–≈ΓΗΜώ»Γ¥ζ¬κΓΙΜώ»Γ PyTorch¥ζ¬κΚΆ‘Λ―ΒΝΖ»®÷ΊΓΘ
1Introduction
ΈΣΝΥ¬ζΉψ±Ώ‘Β…η±ΗΘ®»γ ÷ΜζΘ©”–œόΒΡΡΎ¥φΚΆΦΤΥψΉ ‘¥Θ§“―Ψ≠ΩΣΖΔΝΥΗς÷÷ΗΏ–ßΦήΙΙΓΘάΐ»γΘ§MobileNetV1 Ι”Ο…νΕ»Ω…Ζ÷άκΨμΜΐά¥ΫΒΒΆΦΤΥψ≥…±ΨΓΘMobileNetV2 “ΐ»κΝΥ≤–≤νΝ§Ϋ”Θ§ΕχMobileNetV3 Ά®Ιΐ…ώΨ≠ΦήΙΙΥ―ΥςΘ®NASΘ©Ϋχ“Μ≤Ϋ”≈Μ·ΝΥΦήΙΙ≈δ÷ΟΘ§œ‘÷χΧαΗΏΝΥΡΘ–ΆΒΡ–‘ΡήΓΘΝμ“ΜΗωΒδ–ΆΦήΙΙ «GhostNetΘ§Υϋάϊ”ΟΧΊ’ς÷–ΒΡ»Ώ”ύ≤ΔΆ®Ιΐ Ι”ΟΒΆ≥…±Ψ≤ΌΉςΗ¥÷ΤΧΊ’ςΒΡΆ®ΒάΓΘΉνΫϋΘ§GhostNetV2 Ϋχ“Μ≤Ϋ»ΎΚœΝΥ“ΜΗω”≤Φΰ”―ΚΟΒΡΉΔ“βΝΠΡΘΩιά¥≤ΕΉΫ≥ΛΨύάκœώΥΊ÷°ΦδΒΡ“άάΒΙΊœΒΘ§≤Δ‘Ύ–‘Ρή…œœ‘÷χ≥§‘ΫΝΥGhostNetΓΘ
≥ΐΝΥΨΪ–Ρ…ηΦΤΒΡΡΘ–ΆΦήΙΙ÷°ΆβΘ§ Β±ΒΡ―ΒΝΖ≤Ώ¬‘“≤Ε‘»ΓΒΟœ‘÷χ–‘Ρή÷ΝΙΊ÷Ί“ΣΓΘάΐ»γΘ§WightmanΒ»»ΥΆ®Ιΐ’ϊΚœœ»ΫχΒΡ”≈Μ·ΚΆ ΐΨί‘ω«ΩΖΫΖ®Θ§ΫΪResNet-50‘ΎImageNet-1K…œΒΡtop-1ΉΦ»Ζ¬ ¥”76.1%Χα…ΐΒΫ80.4%ΓΘ»ΜΕχΘ§ΨΓΙή“―Ψ≠ΗΕ≥ωΝΥœύΒ±ΕύΒΡ≈§ΝΠά¥ΧΫΥςΗϋœ»ΫχΒΡ―ΒΝΖ≤Ώ¬‘“‘”Ο”Ύ¥ΪΆ≥ΡΘ–ΆΘ®άΐ»γΘ§ResNetΚΆVisionTransformerΘ©Θ§ΒΪΚή…Ό”–―–ΨΩΙΊΉΔΫτ¥’–ΆΡΘ–ΆΓΘ”…”Ύ≤ΜΆ§»ίΝΩΒΡΡΘ–ΆΩ…ΡήΨΏ”–≤ΜΆ§ΒΡ―ßœΑΤΪΚΟΘ§÷±Ϋ”ΫΪΈΣ¥ΪΆ≥ΡΘ–Ά…ηΦΤΒΡ≤Ώ¬‘”Π”Ο”ΎΫτ¥’–ΆΡΘ–ΆΒΡ―ΒΝΖ «≤Μ«ΓΒ±ΒΡΓΘ
ΈΣΝΥΟ÷Κœ’β“Μ≤νΨύΘ§Ής’ΏœΒΆ≥ΒΊ―–ΨΩΝΥΕύ÷÷”Ο”ΎΫτ¥’–ΆΡΘ–ΆΒΡ―ΒΝΖ≤Ώ¬‘ΓΘΨΏΧεά¥ΥΒΘ§Ής’ΏΒΡ÷ς“ΣΙΊΉΔΒψΖ≈‘ΎΝΥ»γ«ΑΉςΥυΧ÷¬έΒΡΙΊΦϋ―ΒΝΖ…η÷Ο…œΘ§Αϋά®÷Ί≤ΈΜ·ΓΔ÷Σ Ε’τΝσΘ®KDΘ©ΓΔ―ßœΑΦΤΜ°ΚΆ ΐΨί‘ω«ΩΓΘ
÷Ί≤ΈΜ·ΓΘ ”…”Ύ…νΕ»ΨμΜΐΚΆ1ΓΝ1ΨμΜΐ‘ΎΫτ¥’–ΆΡΘ–ΆΦήΙΙ÷–ΒΡΡΎ¥φΚΆΦΤΥψœϊΚΡΩ…“‘Κω¬‘≤ΜΦΤΘ§“ρ¥ΥΥϋΟ« «≥ΘΦϊΒΡΉι≥…≤ΩΖ÷ΓΘ ήΒΫ‘Ύ―ΒΝΖ¥ΪΆ≥ΡΘ–Ά÷–ΒΡ≥…ΙΠΨ≠―ιΒΡΤτΖΔΘ§Ής’Ώ≤…”Ο÷Ί≤ΈΜ·ΖΫΖ®ά¥ΧαΗΏ’βΝΫΗωΫτ¥’ΡΘΩιΒΡ–‘ΡήΓΘ‘Ύ―ΒΝΖΫτ¥’–ΆΡΘ–Ά ±Θ§Ής’Ώ‘Ύ…νΕ»ΨμΜΐ÷–“ΐ»κΝΥœΏ–‘≤Δ––Ζ÷÷ßΓΘ
ΨμΜΐΚΆ1ΓΝ1ΨμΜΐΓΘ’β–©ΕνΆβΒΡΤΫ––Ζ÷÷ß‘Ύ―ΒΝΖΚσΩ…“‘÷Ί–¬≤Έ ΐΜ·Θ§≤ΜΜα‘ΎΆΤάμ ±≤ζ…ζΕνΆβ≥…±ΨΓΘΈΣΝΥ»®ΚβΉήΧε―ΒΝΖ≥…±Ψ”κ–‘ΡήΧα…ΐ÷°ΦδΒΡΙΊœΒΘ§Ής’Ώ±»ΫœΝΥ‘ωΦ”≤ΜΆ§ ΐΝΩΖ÷÷ßΒΡ”ΑœλΓΘ¥ΥΆβΘ§Ής’ΏΖΔœ÷1ΓΝ1…νΕ»ΨμΜΐΖ÷÷ßΕ‘3ΓΝ3…νΕ»ΨμΜΐΒΡ÷Ί–¬≤Έ ΐΜ·”–œ‘÷χΒΡ’ΐΟφ”ΑœλΓΘ
÷Σ Ε’τΝσΓΘ ”…”ΎΫτ¥’–ΆΡΘ–ΆΒΡΡΘ–Ά»ίΝΩ”–œόΘ§ΥϋΟ«ΚήΡ―¥οΒΫ”κ¥ΪΆ≥ΡΘ–Άœύφ«ΟάΒΡ–‘ΡήΓΘ“ρ¥ΥΘ§≤…”ΟΫœ¥σΡΘ–ΆΉςΈΣΫΧ Πά¥÷ΗΒΦΫτ¥’–ΆΡΘ–Ά―ßœΑΒΡKDΖΫΖ®Θ§ «ΧαΗΏ–‘ΡήΒΡ Β±ΆΨΨΕΓΘΉς’Ώ Β÷Λ―–ΨΩΝΥ‘Ύ Ι”ΟKD―ΒΝΖΫτ¥’–ΆΡΘ–Ά ±Θ§ΦΗΗωΒδ–Ά“ρΥΊΒΡ”ΑœλΘ§±»»γΫΧ ΠΡΘ–ΆΒΡ―Γ‘ώΚΆ≥§≤Έ ΐΒΡ…η÷ΟΓΘΫαΙϊ±μΟςΘ§Κœ ΒΡΫΧ ΠΡΘ–ΆΩ…“‘œ‘÷χΧα…ΐΫτ¥’–ΆΡΘ–ΆΒΡ–‘ΡήΓΘ
―ßœΑΦΤΜ°”κ ΐΨί‘ω«ΩΓΘ Ής’Ώ±»ΫœΝΥΫτ¥’–ΆΡΘ–ΆΦΗ÷÷―ΒΝΖ…η÷ΟΘ§Αϋά®―ßœΑ¬ ΓΔ»®÷ΊΥΞΦθΓΔ÷Η ΐ“ΤΕ·ΤΫΨυΘ®EMAΘ©“‘ΦΑ ΐΨί‘ω«ΩΓΘ”–»ΛΒΡ «Θ§≤Δ≤Μ «Υυ”–ΈΣ¥ΪΆ≥ΡΘ–Ά…ηΦΤΒΡΦΦ«…ΕΦ ”Ο”ΎΫτ¥’–ΆΡΘ–ΆΓΘάΐ»γΘ§“Μ–©ΙψΖΚ Ι”ΟΒΡ ΐΨί‘ω«ΩΖΫΖ®Θ§»γ_Mixup_ΚΆ_CutMix_Θ§ ΒΦ …œΜαΫΒΒΆΫτ¥’–ΆΡΘ–ΆΒΡ–‘ΡήΓΘΉς’ΏΫΪ‘ΎΒΎ5ΫΎœξœΗΧ÷¬έΥϋΟ«ΒΡ”ΑœλΓΘ
Μυ”ΎΉς’ΏΒΡ―–ΨΩΘ§Ής’ΏΈΣΫτ¥’–ΆΡΘ–ΆΩΣΖΔΝΥ“ΜΗωΉ®Ο≈ΒΡ―ΒΝΖΖΫΖ®ΓΘ‘ΎImageNet-1K ΐΨίΦ·…œΒΡ Β―ι―ι÷ΛΝΥΉς’ΏΧα≥ωΖΫΖ®ΒΡ”≈‘Ϋ–‘ΓΘΨΏΧεά¥ΥΒΘ§≤…”ΟΉς’ΏΖΫΖ®―ΒΝΖΒΡGhostNetV2ΡΘ–Ά‘Ύtop-1ΉΦ»Ζ–‘ΚΆ―”≥ΌΖΫΟφœ‘÷χ”≈”Ύ≤…”Οœ»«Α≤Ώ¬‘―ΒΝΖΒΡΡΘ–ΆΘ®ΆΦ1Θ©ΓΘ‘ΎΤδΥϋΗΏ–ßΦήΙΙΘ§»γMobileNetV2ΚΆShuffleNetV2…œΒΡ Β―ιΫχ“Μ≤Ϋ÷Λ ΒΝΥΥυΧαΖΫΖ®ΒΡΖΚΜ·ΡήΝΠΓΘ
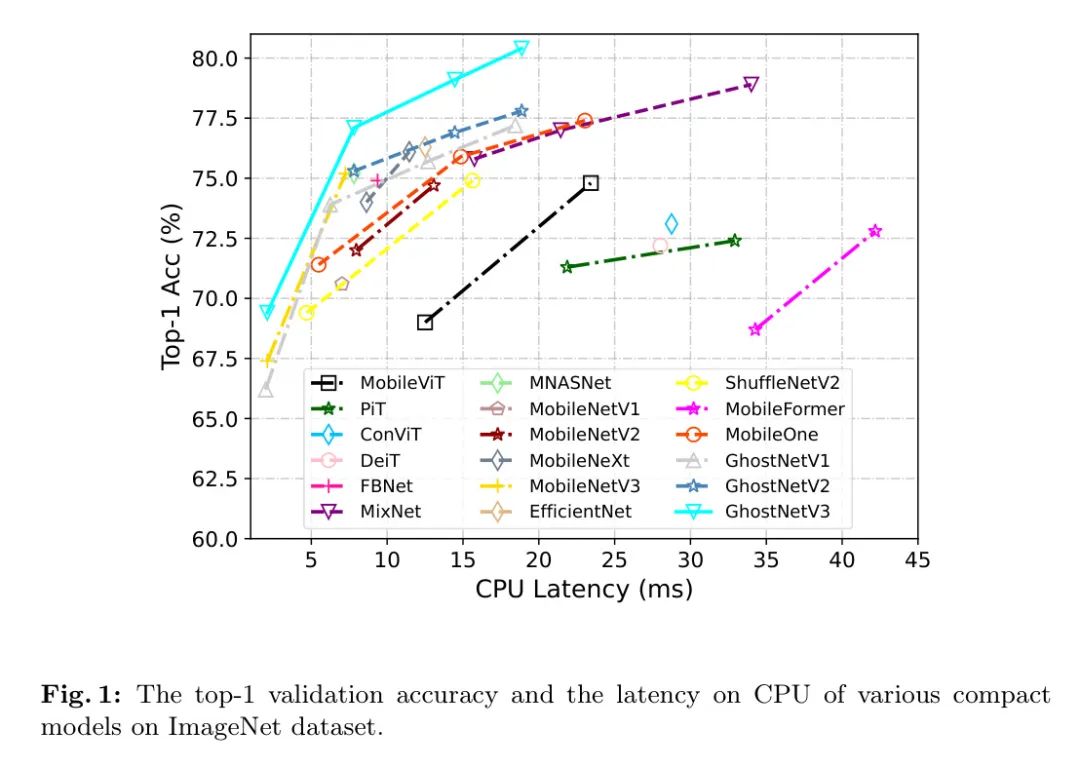
±ΨΈΡΒΡΤδ”ύ≤ΩΖ÷Ήι÷·»γœ¬ΓΘΒΎ2ΫΎΜΊΙΥΝΥœύΙΊΙΛΉςΓΘΒΎ3ΫΎΫι…ήΝΥGhostNetV2ΒΡΦήΙΙΓΘΒΎ4ΫΎœξœΗΧ÷¬έΝΥ―ΒΝΖ≤Ώ¬‘ΓΘΫ”Ή≈ΒΎ5ΫΎ’Ι ΨΝΥΖαΗΜΒΡ Β―ιΫαΙϊΓΘΒΎ6ΫΎΕ‘±ΨΈΡΫχ––ΝΥΉήΫαΓΘ
2Relatedworks
Compactmodels
…ηΦΤ“ΜΗωΆ§ ±ΨΏ”–ΒΆΆΤάμ―”≥ΌΚΆΗΏ–‘ΡήΒΡΫτ¥’ΡΘ–ΆΫαΙΙ «ΨΏ”–Χτ’Ϋ–‘ΒΡΓΘSqueezeNet Χα≥ωΝΥ»ΐ÷÷…ηΦΤΫτ¥’ΡΘ–ΆΒΡΖΫΖ®Θ§Φ¥”Ο1
1¬Υ≤®ΤςΧφΜΜ3
3¬Υ≤®ΤςΘ§Φθ…Ό δ»κΒΫ3
3¬Υ≤®ΤςΒΡΆ®Βά ΐΝΩΘ§≤Δ‘ΎΆχ¬γ÷–Άμ–© ±ΚρΫχ––œ¬≤…―υ“‘±Θ≥÷¥σΒΡΧΊ’ςΆΦΓΘ’β–©‘≠‘ρ «Ϋ®…η–‘ΒΡΘ§”»Τδ «1
1ΨμΜΐΒΡ Ι”ΟΓΘMobileNetV1 ”Ο1
1KernelΚΆ…νΕ»Ω…Ζ÷άκΨμΜΐΧφΜΜΝΥΦΗΚθΥυ”–¬Υ≤®ΤςΘ§ΦΪ¥σΒΊΫΒΒΆΝΥΦΤΥψ≥…±ΨΓΘ
MobileNetV2 Ϋχ“Μ≤ΫΫΪ≤–≤νΝ§Ϋ”“ΐ»κΒΫΫτ¥’ΡΘ–Ά÷–Θ§≤ΔΙΙΫ®ΝΥΒΙ÷Ο≤–≤νΫαΙΙΘ§Τδ÷–ΩιΒΡ÷–Φδ≤ψΒΡΆ®Βά ΐ±»Τδ δ»κΚΆ δ≥ωΕύΓΘΈΣΝΥ±Θ≥÷±μ ΨΡήΝΠΘ§“Τ≥ΐΝΥ“Μ≤ΩΖ÷Ζ«œΏ–‘Κ· ΐΓΘMobileNeXt ÷Ί–¬ΥΦΩΦΝΥΒΙ÷ΟΤΩΨ±ΒΡ±Ί“Σ–‘Θ§≤Δ…υ≥ΤΨ≠ΒδΒΡΤΩΨ±ΫαΙΙ“≤Ρή Βœ÷ΗΏ–‘ΡήΓΘΩΦ¬«ΒΫ1
1ΨμΜΐ’ΦΨίΝΥœύΒ±“Μ≤ΩΖ÷ΦΤΥψ≥…±ΨΘ§ShuffleNet ”ΟΉιΨμΜΐΧφΜΜΝΥΥϋΓΘΆ®ΒάΜλœ¥≤ΌΉς”–÷ζ”Ύ–≈œΔ‘ΎΉιΦδΝςΕ·ΓΘΆ®Ιΐ―–ΨΩ”Αœλ ΒΦ ‘Υ––ΥΌΕ»ΒΡ“ρΥΊΘ§ShuffleNetV2 Χα≥ωΝΥ“ΜΗω–¬–Ά”≤Φΰ”―ΚΟΩιΓΘ
MnasNet ΚΆMobileNetV3Υ―ΥςΦήΙΙ≤Έ ΐΘ§±»»γΡΘ–ΆΩμΕ»ΓΔΡΘ–Ά…νΕ»ΓΔΨμΜΐ¬Υ≤®ΤςΒΡ¥σ–ΓΒ»ΓΘΆ®Ιΐάϊ”ΟΧΊ’ςΒΡ»Ώ”ύΘ§GhostNet ”ΟΒΆ≥…±Ψ≤ΌΉςΧφΜΜΝΥ1
1ΨμΜΐ÷–ΒΡ“ΜΑκΆ®ΒάΓΘGhostNetV2Χα≥ωΝΥ“Μ÷÷Μυ”Ύ»ΪΝ§Ϋ”≤ψΒΡΥυΈΫDFCΉΔ“βΝΠΜζ÷ΤΘ§Υϋ≤ΜΫωΡή‘Ύ≥ΘΦϊ”≤Φΰ…œΩλΥΌ÷¥––Θ§ΜΙΡή≤ΕΉΫ‘ΕΨύάκœώΥΊ÷°ΦδΒΡ“άάΒΙΊœΒΓΘΒΫΡΩ«ΑΈΣ÷ΙΘ§GhostNetsœΒΝ–»‘»Μ «ΨΪΕ»ΚΆΥΌΕ»÷°Φδ’έ÷‘ΉνΦ―ΒΡSOTAΫτ¥’–ΆΡΘ–ΆΓΘ
Ή‘¥”ViTΘ®DeiTΘ©[8]‘ΎΦΤΥψΜζ ”Ψθ»ΈΈώ…œ»ΓΒΟΨό¥σ≥…ΙΠ“‘ά¥Θ§―–ΨΩ––»Υ“Μ÷±÷¬ΝΠ”ΎΈΣ“ΤΕ·…η±Η…ηΦΤΫτ¥’–ΆTransformerΦήΙΙΓΘMobileFormerΧα≥ωΝΥ“Μ÷÷Ϋτ¥’ΒΡΩγΉΔ“βΝΠΜζ÷ΤΘ§“‘Ϋ®ΡΘMobileNetΚΆTransformer÷°ΦδΒΡΥΪœρ«≈ΝΚΓΘMobileViTΦ≥»ΓΝΥΫτ¥’–ΆCNNΒΡ≥…ΙΠΨ≠―ιΘ§≤Δ”ΟTransformerΫχ––»ΪΨ÷¥Πάμά¥Χφ¥ζΨμΜΐ÷–ΒΡΨ÷≤Ω¥ΠάμΓΘ»ΜΕχΘ§Μυ”ΎTransformerΒΡΫτ¥’ΡΘ–Ά‘Ύ“ΤΕ·…η±Η…œ”…”ΎΗ¥‘”ΒΡΉΔ“βΝΠ≤ΌΉςΕχ‘β ήΗΏΆΤάμ―”≥ΌΓΘ
Bagoftricksfortraining
CNNs”–“Μ–©ΙΛΉςΉ®ΉΔ”ΎΗΡΫχ―ΒΝΖ≤Ώ¬‘“‘ΧαΗΏΗς÷÷ΡΘ–ΆΒΡ–‘ΡήΓΘΥϊΒ»»ΥΧ÷¬έΝΥ‘Ύ”≤Φΰ…œΫχ––ΗΏ–ß―ΒΝΖΒΡ“Μ–©”–”ΟΦΦ«…Θ§≤ΔΈΣResNetΧα≥ωΝΥ“Μ÷÷–¬ΒΡΡΘ–ΆΦήΙΙΒς’ϊΖΫΖ®ΓΘWrightmanΒ»»Υ÷Ί–¬ΤάΙάΝΥ‘Ύ Ι”Ο–¬–Ά”≈Μ·ΚΆ ΐΨί‘ω«ΩΖΫΖ®―ΒΝΖ ±Θ§Τ’Ά®ResNet-50ΒΡ–‘ΡήΓΘΥϊΟ«‘ΎtimmΩΣ‘¥Ωβ÷–Ζ÷œμΝΥΨΏ”–ΨΚ’υΝΠΒΡ―ΒΝΖ…η÷ΟΚΆ‘Λ―ΒΝΖΡΘ–ΆΓΘ≤…”ΟΥϊΟ«ΒΡ―ΒΝΖΖΫΑΗΘ§“ΜΗωΤ’Ά®ΒΡResNet-50ΡΘ–Ά¥οΒΫΝΥ80.4%ΒΡtop-1ΉΦ»Ζ¬ ΓΘChenΒ»»Υ―–ΨΩΝΥ―ΒΝΖΉ‘ΦύΕΫViTΒΡΦΗΗωΜυ±ΨΉι≥…≤ΩΖ÷ΒΡ”ΑœλΓΘ»ΜΕχΘ§Υυ”–’β–©≥Δ ‘ΕΦ «ΈΣ¥σ–ΆΡΘ–ΆΜρΉ‘ΦύΕΫΡΘ–Ά…ηΦΤΒΡΓΘ”…”ΎΡΘ–Ά»ίΝΩΒΡ≤ΜΆ§Θ§÷±Ϋ”ΫΪΥϋΟ«ΉΣ“ΤΒΫΫτ¥’ΡΘ–Ά «≤Μ«ΓΒ±ΒΡΓΘ
3Preliminary
GhostNetsΘ®GhostNetV1ΚΆGhostNetV2Θ© «’κΕ‘“ΤΕ·…η±Η…œΗΏ–ßΆΤάμ…ηΦΤΒΡΉνœ»ΫχΒΡΫτ¥’–ΆΡΘ–ΆΓΘΤδΙΊΦϋΦήΙΙ «GhostΡΘΩιΘ§ΥϋΩ…“‘Ά®ΙΐΝ°ΦέΒΡ≤ΌΉς…ζ≥…ΗϋΕύΒΡΧΊ’ςΆΦΘ§¥”ΕχΧφ¥ζ‘≠ ΦΨμΜΐΓΘ
‘ΎΤ’Ά®ΒΡΨμΜΐ÷–Θ§ δ≥ωΧΊ’ς
«Ά®Ιΐ
ΒΟΒΫΒΡΘ§Τδ÷–
«ΨμΜΐΚΥΘ§
« δ»κΧΊ’ςΓΘ
ΚΆ
Ζ÷±π±μ Ψ δ»κΚΆ δ≥ωΒΡΆ®ΒάΈ§Ε»ΓΘ
«ΚΥΒΡ¥σ–ΓΘ§
±μ ΨΨμΜΐ≤ΌΉςΓΘGhostΡΘΩιΆ®ΙΐΝΫΗω≤Ϋ÷ηΦθ…ΌΝΥΤ’Ά®ΨμΜΐΒΡ≤Έ ΐ ΐΝΩΚΆΦΤΥψ≥…±ΨΓΘΥϋ Ήœ»…ζ≥…_intrinsic_ΧΊ’ς
Θ§ΤδΆ®ΒάΈ§Ε»–Γ”Ύ‘≠ ΦΧΊ’ς
ΓΘ»ΜΚσΘ§‘Ύ_intrinsic_ΧΊ’ς
…œ”Π”ΟΝ°ΦέΒΡ≤ΌΉςΘ®άΐ»γΘ§…νΕ»ΨμΜΐΘ©ά¥…ζ≥…_ghost_ΧΊ’ς
ΓΘΉν÷’ δ≥ω «Ά®Ιΐ―ΊΆ®ΒάΈ§Ε»Ν§Ϋ”_intrinsic_ΚΆ_ghost_ΧΊ’ςΒΟΒΫΒΡΘ§ΤδΙΪ ΫΩ…“‘±μ ΨΈΣΘΚ
‘ΎΙΪ Ϋ÷–Θ§
ΚΆ
Ζ÷±π±μ Ψ≥θΦΕΨμΜΐΚΆΝ°Φέ≤ΌΉς÷–ΒΡ≤Έ ΐΓΘ"Cat" ±μ ΨΝ§Ϋ”≤ΌΉςΓΘ’ϊΗωGhostNetΡΘ–Ά «Ά®ΙΐΕ―ΒΰΕύΗωGhostΡΘΩιΙΙΫ®Εχ≥…ΒΡΓΘ
GhostNetV2Ά®Ιΐ…ηΦΤ“ΜΗωΗΏ–ßΒΡΉΔ“βΝΠΡΘΩιΘ§Φ¥DFCΉΔ“βΝΠΡΘΩιΘ§ά¥‘ω«ΩΫτ¥’–ΆΡΘ–ΆΓΘΩΦ¬«ΒΫœώGhostNet’β―υΒΡΫτ¥’ΡΘ–ΆΆ®≥Θ Ι”Ο–ΓΚΥΨμΜΐΘ§άΐ»γ1
1ΚΆ3
3Θ§ΥϋΟ«¥” δ»κΧΊ’ς÷–Χα»Γ»ΪΨ÷–≈œΔΒΡΡήΝΠΫœ»θΓΘGhostNetV2≤…”Ο“ΜΗωΦρΒΞΒΡ»ΪΝ§Ϋ”≤ψά¥≤ΕΉΫ‘Ε≥ΧΩ’Φδ–≈œΔ≤Δ…ζ≥…ΉΔ“βΝΠΆΦΓΘΈΣΝΥΦΤΥψ–߬ Θ§ΥϋΫΪ»ΪΨ÷–≈œΔΖ÷ΫβΈΣΥ°ΤΫΚΆ¥Ι÷±ΖΫœρΘ§≤ΔΖ÷±π―Ί’βΝΫΗωΖΫœρΨέΚœœώΥΊΓΘ»γΆΦ1(a)Υυ ΨΘ§Ά®ΙΐΫΪDFCΉΔ“βΝΠΡΘΩι”κGhostΡΘΩιΫαΚœ Ι”ΟΘ§GhostNetV2ΡήΙΜ”––ßΒΊΧα»Γ»ΪΨ÷ΚΆΨ÷≤Ω–≈œΔΘ§Ά§ ±‘ΎΉΦ»Ζ–‘ΚΆΦΤΥψΗ¥‘”Ε»÷°Φδ Βœ÷ΝΥΗϋΚΟΒΡΤΫΚβΓΘ
4Trainingstrategies
Ής’ΏΒΡΡΩ±ξ «ΧΫΥς―ΒΝΖ≤Ώ¬‘Θ§‘Ύ≤ΜΗΡ±δΆΤάμΆχ¬γΦήΙΙΒΡ«ιΩωœ¬Θ§“‘±Θ≥÷Ϋτ¥’ΡΘ–ΆΒΡ–Γ≥Ώ¥γΚΆΩλΥΌΥΌΕ»ΓΘΉς’Ώ Β÷Λ―–ΨΩΝΥ―ΒΝΖ…ώΨ≠Άχ¬γΒΡΙΊΦϋ“ρΥΊΘ§Αϋά®―ßœΑΦΤΜ°ΓΔ ΐΨί‘ω«ΩΓΔ÷Ί≤ΈΜ·ΚΆ÷Σ Ε’τΝσΓΘ
Re-parameterization
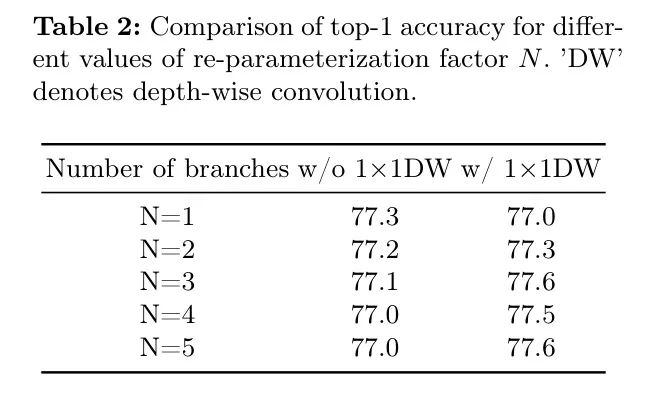
÷Ί≤ΈΜ·‘Ύ¥ΪΆ≥ΨμΜΐΡΘ–Ά÷–“―Ψ≠÷ΛΟςΝΥΤδ”––ß–‘ΓΘ ήΤδ≥…ΙΠΒΡΤτΖΔΘ§Ής’ΏΆ®ΙΐΧμΦ”≈δ±ΗBatchNorm≤ψΒΡ÷ΊΗ¥Ζ÷÷ßΘ§ΫΪ÷Ί≤ΈΜ·“ΐ»κΫτ¥’–ΆΡΘ–Ά÷–ΓΘΉς’Ώ‘ΎΆΦ1(b)÷–’Ι ΨΝΥ÷Ί≤ΈΜ·GhostNetV2ΒΡ…ηΦΤΓΘ÷ΒΒΟΉΔ“βΒΡ «Θ§Ής’Ώ“ΐ»κΝΥ“ΜΗω1
1…νΕ»ΨμΜΐΖ÷÷ßΒΫ÷Ί≤ΈΜ·ΒΡ3
3…νΕ»ΨμΜΐ÷–ΓΘ Β―ιΫαΙϊ»Ζ»œΝΥΥϋ‘ΎΫτ¥’–ΆΡΘ–Ά–‘Ρή…œΒΡΜΐΦΪ–ßΙϊΓΘ¥ΥΆβΘ§ Β―ιΜΙ≥ΙΒΉΧΫΥςΝΥ÷ΊΗ¥Ζ÷÷ßΒΡΉν”≈ ΐΝΩΓΘ
‘ΎΆΤάμ ±Θ§Ω…“‘Ά®ΙΐΡφ÷Ί≤ΈΜ·Ιΐ≥Χ“Τ≥ΐ÷ΊΗ¥ΒΡΖ÷÷ßΓΘ”…”Ύ‘ΎΆΤάμ ±ΨμΜΐΚΆ≈ζΝΩΙι“ΜΜ·≤ΌΉςΕΦ «œΏ–‘ΒΡΘ§ΥϋΟ«Ω…“‘±Μ’έΒΰ≥…“ΜΗωΒΞ“ΜΒΡΨμΜΐ≤ψΘ§Τδ»®÷ΊΨΊ’σ±μ ΨΈΣ
Θ§ΤΪ÷Ο±μ ΨΈΣ
ΓΘ÷°ΚσΘ§Υυ”–Ζ÷÷ß÷–’έΒΰΒΡ»®÷ΊΚΆΤΪ÷ΟΩ…“‘±Μ÷Ί≤ΈΜ·ΈΣ
ΚΆΤΪ÷Ο
Θ§Τδ÷–
«÷ΊΗ¥Ζ÷÷ßΒΡΥς“ΐΓΘ
KnowledgedistillationKD
Ε‘”Ύ“ΜΗω―υ±Ψ
ΦΑΤδ±ξ«©
Θ§Ζ÷±π”Ο
ΚΆ
±μ Ψ―ß…ζΡΘ–ΆΚΆΫΧ ΠΡΘ–Ά‘Λ≤βΒΡœύ”Π¬ΏΦ≠÷ΒΘ§KDΒΡΉήΥπ ßΚ· ΐΩ…“‘±μ ωΈΣΘΚ
Τδ÷–
ΚΆ
Ζ÷±π±μ ΨΫΜ≤φλΊΥπ ßΚΆKDΥπ ßΓΘ
«“ΜΗωΤΫΚβ≥§≤Έ ΐΓΘ
Ά®≥ΘΘ§Kullback-Leibler…ΔΕ»Κ· ΐ±Μ≤…Ρ…ΉςΈΣ÷Σ Ε’τΝσΥπ ßΘ®KDlossΘ©Θ§ΤδΩ…“‘±μ ΨΈΣΘΚ
’βάοΒΡΥπ ßΚ· ΐ
Τδ÷–
«“ΜΗω≥ΤΈΣΈ¬Ε»ΒΡ±ξ«©ΤΫΜ§≥§≤Έ ΐΓΘ‘ΎΉς’ΏΒΡ Β―ι÷–Θ§Ής’Ώ―–ΨΩΝΥ≥§≤Έ ΐ
ΚΆ
≤ΜΆ§…η÷ΟΕ‘Ϋτ¥’–ΆΡΘ–Ά–‘ΡήΒΡ”ΑœλΓΘ
Learningschedule
―ßœΑ¬ «…ώΨ≠Άχ¬γ”≈Μ·÷–ΒΡ“ΜΗωΙΊΦϋ≤Έ ΐΓΘΆ®≥Θ Ι”ΟΒΡΝΫ÷÷―ßœΑ¬ Βς’ϊ≤Ώ¬‘”–ΘΚ_≤ΫΫχ_ΚΆ_”ύœ“_ΓΘ_≤ΫΫχ_≤Ώ¬‘œΏ–‘ΒΊΫΒΒΆ―ßœΑ¬ Θ§Εχ_”ύœ“_≤Ώ¬‘‘ΎΩΣ Φ ±ΜΚ¬ΐΫΒΒΆ―ßœΑ¬ Θ§‘Ύ÷–ΦδΫΉΕΈΦΗΚθ≥ œΏ–‘Θ§‘ΎΉνΚσ”÷Φθ¬ΐΫΒΒΆΥΌΕ»ΓΘ’βœνΙΛΉςΙψΖΚ―–ΨΩΝΥ―ßœΑ¬ “‘ΦΑ―ßœΑ¬ Βς’ϊ≤Ώ¬‘Ε‘Ϋτ¥’–ΆΡΘ–ΆΒΡ”ΑœλΓΘ
÷Η ΐ“ΤΕ·ΤΫΨυΘ®EMAΘ©ΉνΫϋ“―≥…ΈΣΧαΗΏΡΘ–Ά―ι÷ΛΉΦ»Ζ–‘ΚΆ‘ω«ΩΡΘ–Ά¬≥Ατ–‘ΒΡ”––ßΖΫΖ®ΓΘΨΏΧεά¥ΥΒΘ§‘Ύ―ΒΝΖΤΎΦδΘ§Υϋ÷πΫΞΕ‘ΡΘ–ΆΒΡ≤Έ ΐΫχ––ΤΫΨυΓΘΦΌ…ηΡΘ–Ά‘ΎΒΎ
≤ΫΒΡ≤Έ ΐΈΣ
Θ§ΡΘ–ΆΒΡEMAΦΤΥψΖΫ Ϋ»γœ¬ΘΚ
Τδ÷–Θ§
¥ζ±μ‘Ύ≤Ϋ÷η
±EMAΡΘ–ΆΒΡ≤Έ ΐΘ§Εχ
«“ΜΗω≥§≤Έ ΐΓΘΉς’ΏΫΪ‘ΎΒΎ5.3ΫΎ―–ΨΩEMAΒΡ”ΑœλΓΘ
Dataaugmentation
Ης÷÷ ΐΨί‘ω«ΩΖΫΖ®“―±ΜΧα≥ω“‘Χα…ΐ¥ΪΆ≥ΡΘ–ΆΒΡ–‘ΡήΓΘΤδ÷–Θ§_AutoAug_ΖΫΑΗ≤…”ΟΝΥ25÷÷Ή”≤Ώ¬‘ΉιΚœΘ§ΟΩ÷÷ΉιΚœΑϋΚ§ΝΫ÷÷ΉΣΜΜΓΘΕ‘”ΎΟΩΗω δ»κΆΦœώΘ§ΥφΜζ―Γ‘ώ“ΜΗωΉ”≤Ώ¬‘ΉιΚœΘ§≤Δ»ΖΕ® «Ζώ”Π”ΟΉ”≤Ώ¬‘÷–ΒΡΟΩ÷÷ΉΣΜΜΘ§’β“ΜΨω≤Ώ”…“ΜΕ®ΒΡΗ≈¬ ΨωΕ®ΓΘ_RandomAug_ΖΫΖ®Χα≥ωΝΥ“Μ÷÷ΥφΜζ‘ω«ΩΖΫΖ®Θ§Τδ÷–Υυ”–Ή”≤Ώ¬‘ΕΦ“‘œύΆ§ΒΡΗ≈¬ ±Μ―Γ‘ώΓΘœώ_Mixup_ΚΆ_CutMix_’β―υΒΡΆΦœώ±πΟϊΖΫΖ®»ΎΚœΝΥΝΫΖυΆΦœώ“‘…ζ≥…–¬ΆΦœώΓΘΨΏΧεά¥ΥΒΘ§_Mixup_‘Ύ≥…Ε‘ΒΡ ΨάΐΦΑΤδ±ξ«©ΒΡΆΙΉιΚœ…œ―ΒΝΖ…ώΨ≠Άχ¬γΘ§Εχ_CutMix_‘ρΥφΜζ¥”“ΜΖυΆΦœώ÷–“Τ≥ΐ“ΜΗω«χ”ρ≤Δ”ΟΝμ“ΜΖυΆΦœώ÷–ΒΡPatchΧφΜΜœύ”Π«χ”ρΓΘ_RandomErasing_‘ΎΆΦœώ÷–ΥφΜζ―Γ‘ώ“ΜΗωΨΊ–Έ«χ”ρ≤Δ”ΟΥφΜζ÷ΒΧφΜΜΤδœώΥΊΓΘ
‘Ύ±ΨΈΡ÷–Θ§Ής’ΏΤάΙάΝΥ…œ ω ΐΨί‘ω«ΩΖΫΖ®ΒΡΕύ÷÷ΉιΚœΘ§≤ΔΖΔœ÷“Μ–©≥Θ”Ο”Ύ―ΒΝΖ¥ΪΆ≥ΡΘ–ΆΒΡ ΐΨί‘ω«ΩΖΫΖ®Θ§άΐ»γMixupΚΆCutMixΘ§≤Δ≤Μ Κœ”Ο”Ύ―ΒΝΖΫτ¥’–ΆΡΘ–ΆΓΘ
5Experimentalresults
‘ΎΉς’ΏΒΡΜυ±Ψ―ΒΝΖ≤Ώ¬‘÷–Θ§Ής’Ώ Ι”Ο2048ΒΡ–Γ≈ζΝΩ¥σ–ΓΘ§≤Δ≤…”ΟLAMB Ε‘ΡΘ–ΆΫχ––600Ηω÷ήΤΎΒΡ”≈Μ·ΓΘ≥θ Φ―ßœΑ¬ …ηΈΣ0.005Θ§≤…”Ο”ύœ“―ßœΑ¬ Βς’ϊ≤Ώ¬‘ΓΘ»®÷ΊΥΞΦθΚΆΕ·ΝΩΖ÷±π…η÷ΟΈΣ0.05ΚΆ0.9ΓΘΉς’ΏΕ‘÷Η ΐ“ΤΕ·ΤΫΨυΘ®EMAΘ© Ι”Ο0.999ΒΡΥΞΦθ“ρΉ”Θ§Τδ÷–”Π”ΟΝΥΥφΜζ‘ω«ΩΚΆΥφΜζ≤Ν≥ΐΫχ–– ΐΨί‘ω«ΩΓΘ‘Ύ±ΨΫΎ÷–Θ§Ής’ΏΫΪΧΫΧ÷’β–©―ΒΝΖ≤Ώ¬‘Θ§≤ΔΈΣ―ΒΝΖΫτ¥’–ΆΡΘ–ΆΫ“ Ψ“Μ–©ΦϊΫβΓΘΥυ”– Β―ιΕΦ «‘ΎImageNet ΐΨίΦ· …œ Ι”Ο8ΗωNVIDIATeslaV100GPUΫχ––ΒΡΓΘ
Re-parameterization
ΈΣΝΥΗϋΚΟΒΊάμΫβΫΪ÷Ί≤ΈΜ·Φ·≥…ΒΫΫτ¥’–ΆΡΘ–ΆΒΡ―ΒΝΖ÷–ΒΡ”≈ ΤΘ§Ής’ΏΫχ––ΝΥ“Μœνœϊ»Ύ―–ΨΩΘ§“‘ΤάΙά÷Ί≤ΈΜ·Ε‘≤ΜΆ§¥σ–ΓGhostNetV2ΒΡ”ΑœλΓΘΫαΙϊ’Ι Ψ‘Ύ±μ1÷–ΓΘ‘ΎΤδΥϊ―ΒΝΖ…η÷Ο±Θ≥÷≤Μ±δΒΡ«ιΩωœ¬≤…”Ο÷Ί≤ΈΜ·Θ§”κ÷±Ϋ”―ΒΝΖ‘≠ ΦGhostNetV2ΡΘ–Άœύ±»Θ§–‘ΡήΒΟΒΫΝΥœ‘÷χΧα…ΐΓΘ
¥ΥΆβΘ§Ής’Ώ±»ΫœΝΥ÷Ί≤ΈΜ·“ρΉ”
ΒΡ≤ΜΆ§≈δ÷ΟΘ§ΫαΙϊ»γ±μ2Υυ ΨΓΘΗυΨίΫαΙϊœ‘ ΨΘ§1
1…νΕ»ΨμΜΐ‘Ύ÷Ί≤ΈΜ·÷–ΤπΉ≈ΙΊΦϋΉς”ΟΓΘ»γΙϊ÷Ί≤ΈΜ·ΡΘ–Ά÷–≤Μ Ι”Ο1
1…νΕ»ΨμΜΐΘ§Τδ–‘Ρή…θ÷ΝΥφΉ≈Ζ÷÷ß ΐΝΩΒΡ‘ωΦ”Εχœ¬ΫΒΓΘœύ±»÷°œ¬Θ§Β±≈δ±Η1
1…νΕ»ΨμΜΐ ±Θ§GhostNetV3ΡΘ–Ά‘Ύ
ΈΣ3 ±¥οΒΫ77.6%ΒΡΖε÷Βtop-1ΉΦ»Ζ¬ Θ§Ϋχ“Μ≤Ϋ‘ωΦ”
ΒΡ÷Β≤Δ≤ΜΜα¥χά¥–‘ΡήΒΡΕνΆβΧα…ΐΓΘ“ρ¥ΥΘ§‘ΎΚσ–χ Β―ι÷–ΫΪ÷Ί≤ΈΜ·“ρΉ”
…η÷ΟΈΣ3“‘ΜώΒΟΗϋΚΟΒΡ–‘ΡήΓΘ
Knowledgedistillation
‘Ύ±ΨΫΎ÷–Θ§Ής’ΏΤάΙάΝΥ÷Σ Ε’τΝσΕ‘GhostNetV3–‘ΡήΒΡ”ΑœλΓΘΨΏΧεά¥ΥΒΘ§―Γ”ΟResNet-101ΓΔDeiT-BΚΆBeiTV2-BΉςΈΣΫΧ ΠΡΘ–ΆΘ§ΥϋΟ«Ζ÷±π¥οΒΫ77.4%ΓΔ81.8%ΚΆ86.5%ΒΡtop-1ΉΦ»Ζ¬ ΓΘ±μ3÷–ΒΡΫαΙϊœ‘ ΨΝΥ≤ΜΆ§ΫΧ ΠΡΘ–Άœ¬ΒΡ–‘Ρή±δΜ·ΓΘ÷ΒΒΟΉΔ“βΒΡ «Θ§ΫΧ ΠΡΘ–Ά–‘ΡήΒΡ”≈‘Ϋ–‘”κ―ß…ζΡΘ–ΆΒΡ–‘ΡήΧαΗΏ¥φ‘ΎœύΙΊ–‘ΓΘ
ΥφΉ≈ΗΡΫχΒΡGhostNetV3–‘ΡήΒΡΧαΗΏΘ§«ΩΒςΝΥ‘Ύ÷Σ Ε’τΝσ÷–Θ§Ε‘”ΎΫτ¥’–ΆΡΘ–Άά¥ΥΒΘ§“ΜΗω±μœ÷ΝΦΚΟΒΡΫΧ ΠΡΘ–ΆΒΡ÷Ί“Σ–‘ΓΘ
Ής’ΏΫχ“Μ≤Ϋ±»ΫœΝΥ‘Ύ≤ΜΆ§≥§≤Έ ΐ…η÷Οœ¬ΒΡ÷Σ Ε’τΝσΥπ ßΘ§“‘BEiTV2-BΉςΈΣΫΧ ΠΡΘ–ΆΓΘ±μ4÷–ΒΡΫαΙϊ±μΟςΘ§Ε‘”ΎΫτ¥’–ΆΡΘ–Άά¥ΥΒΘ§ΒΆΈ¬Ε»÷ΒΗϋΈΣΚœ ΓΘ¥ΥΆβΘ§÷ΒΒΟΉΔ“βΒΡ «Θ§Β±Ϋω Ι”Ο÷Σ Ε’τΝσΥπ ßΘ®Φ¥
=1.0Θ© ±Θ§top-1ΉΦ»ΖΕ»Οςœ‘œ¬ΫΒΓΘ
Ής’ΏΆ§―υΧΫΧ÷ΝΥΫΪ÷Ί≤ΈΜ·”κ÷Σ Ε’τΝσΫαΚœΕ‘GhostNetV2–‘ΡήΒΡ”ΑœλΓΘ»γ±μ5Υυ ΨΘ§ΫαΙϊœ‘ Ψ”…”Ύάϊ”ΟΝΥ÷Σ Ε’τΝσΘ§–‘Ρή”–ΝΥœ‘÷χΒΡΧα…ΐΘ®ΗΏ¥ο79.13%Θ©ΓΘ¥ΥΆβΘ§’β«ΩΒςΝΥ‘Ύ÷Ί≤ΈΜ·÷–1
1…νΕ»ΨμΜΐΒΡ÷Ί“Σ–‘ΓΘ’β–©ΖΔœ÷«ΩΒςΝΥ―–ΨΩΗς÷÷ΦΦ θΦΑΤδ«±‘ΎΉιΚœ“‘Χα…ΐΫτ¥’–ΆΡΘ–Ά–‘ΡήΒΡ÷Ί“Σ–‘ΓΘ
»®÷ΊΥΞΦθΓΘ±μ7’Ι ΨΝΥ»®÷ΊΥΞΦθΕ‘GhostNetV2ΒΡtop-1ΉΦ»ΖΕ»ΒΡ”ΑœλΓΘΫαΙϊ±μΟςΘ§Ϋœ¥σΒΡ»®÷ΊΥΞΦθΜαœ‘÷χΫΒΒΆΡΘ–ΆΒΡ–‘ΡήΓΘ“ρ¥ΥΘ§ΩΦ¬«ΒΫΤδΕ‘Ϋτ¥’–ΆΡΘ–ΆΒΡ”––ß–‘Θ§Ής’ΏΈΣGhostNetV2±Θ≥÷ΝΥ0.05ΒΡ»®÷ΊΥΞΦθ÷ΒΓΘ
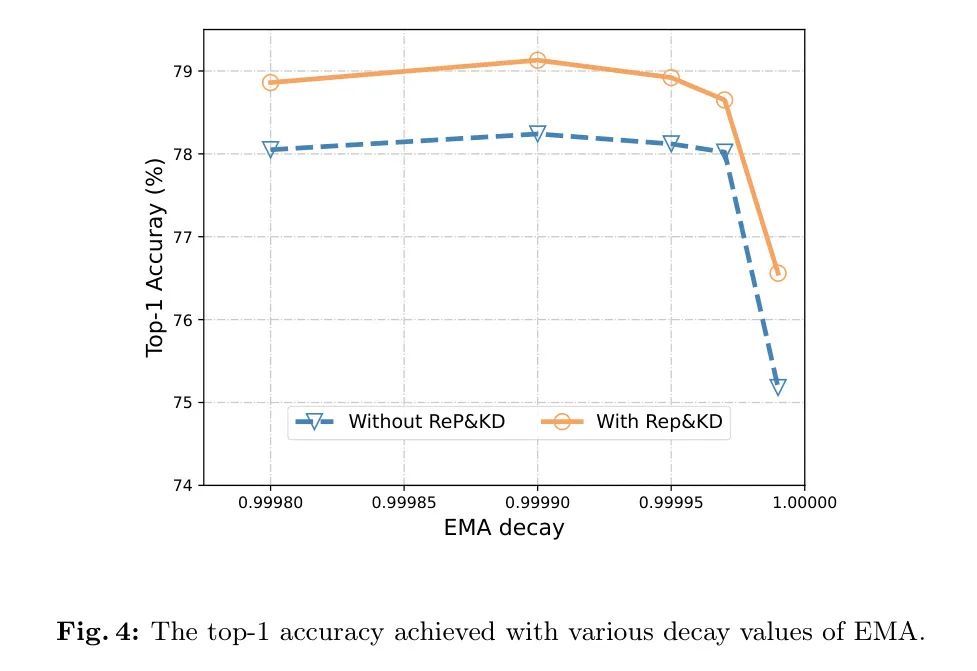
‘ΎΆΦ4÷–Θ§Ω…“‘Ιέ≤λΒΫΒ±EMAΒΡΥΞΦθ÷ΒΈΣ0.99999 ±Θ§Έό¬έ «Ζώ Ι”Ο÷Ί≤ΈΜ·ΚΆ÷Σ Ε’τΝσΦΦ θΘ§–‘ΡήΕΦΜαœ¬ΫΒΓΘΉς’ΏΆΤ≤β’βΩ…Ρή «”…”ΎΥΞΦθ÷ΒΙΐ¥σ ±Θ§Β±«ΑΒϋ¥ζΒΡœς»θ–ß”ΠΥυ÷¬ΓΘΕ‘”ΎΫτ¥’–ΆΡΘ–ΆΘ§ΥΞΦθ÷Β0.9999Μρ0.99995±Μ»œΈΣ «Κœ ΒΡΘ§’β”κ¥ΪΆ≥ΡΘ–ΆΒΡ÷ΒœύΥΤΓΘ
DataAugmentation
ΈΣΝΥ±»Ϋœ≤ΜΆ§ΒΡ ΐΨί‘ω«ΩΖΫΑΗΕ‘«αΝΩΦΕΡΘ–Ά–‘ΡήΒΡ”ΑœλΘ§Ής’Ώ―ΒΝΖΝΥΜυ”ΎΨμΜΐ…ώΨ≠Άχ¬γΘ®CNNΘ©ΒΡGhostNetV2ΚΆΜυ”ΎViTΒΡΡΘ–ΆΓΘ
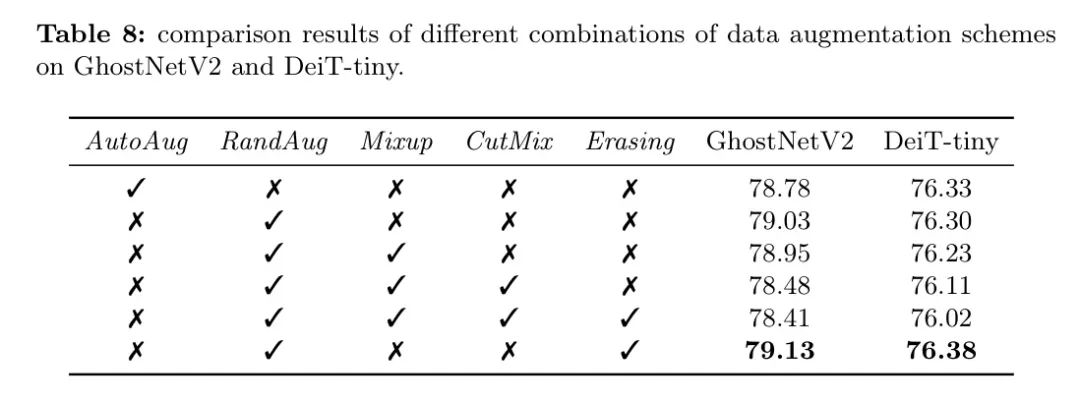
‘Ύ≤…”Ο≤ΜΆ§‘ω«Ω≤Ώ¬‘œ¬ΒΡDeiT-tinyΡΘ–ΆΓΘΫαΙϊ’Ι Ψ‘Ύ±μ8÷–ΓΘΙέ≤λΒΫ_ΥφΜζ‘ω«Ω_ΚΆ_ΥφΜζ≤Ν≥ΐ_Ε‘GhostNetV2ΚΆDeiT-tinyΕΦ”–άϊΓΘœύΖ¥Θ§_Mixup_ΚΆ_CutMix_≤ζ…ζΝΥ≤Μάϊ”ΑœλΘ§“ρ¥Υ±Μ»œΈΣ≤Μ ΚœΫτ¥’–ΆΡΘ–ΆΓΘ
Comparisonwithothercompactmodels
‘Ύ±ΨΫΎ÷–Θ§Ής’Ώ±»ΫœΝΥGhostNetV3”κΤδΥϊΫτ¥’–ΆΡΘ–Ά‘Ύ≤Έ ΐΝΩΓΔFLOPs“‘ΦΑ‘ΎCPUΚΆ ÷Μζ…œΒΡ―”≥ΌΓΘΨΏΧεά¥ΥΒΘ§Ής’ΏΫΪ’β–©ΡΘ–Ά‘Υ––‘Ύ“ΜΗω≈δ±ΗΝΥ3.2GHzInteli7-8700¥ΠάμΤςΒΡWindowsΧ® ΫΜζ…œ“‘≤βΝΩCPU―”≥ΌΘ§≤Δ Ι”Ο≈δ±ΗΝΥςηςκ¥ΠάμΤςΒΡΜΣΈΣMate40Pro ÷ΜζΫχ––≤β ‘ΓΘ
Ι”Ο9000CPUά¥ΤάΙά‘Ύ δ»κΖ÷±φ¬ ΈΣ224ΓΝ224ΒΡ≈δ÷Οœ¬ ÷ΜζΒΡ―”≥ΌΓΘΈΣ»Ζ±ΘΉνΒΆ―”≥ΌΚΆΉνΗΏ“Μ÷¬–‘Θ§ΙΊ±’CPUΚΆ ÷Μζ…œΥυ”–ΤδΥϊ”Π”Ο≥Χ–ρΓΘΟΩΗωΡΘ–Ά÷¥––100¥Έ“‘ΜώΒΟΩ…ΩΩΒΡΫαΙϊΓΘ
±μ9œξœΗ±»ΫœΝΥGhostNetV3”κΤδΥϊ≤Έ ΐΝΩ‘Ύ20M“‘œ¬ΒΡΫτ¥’–ΆΡΘ–ΆΓΘ¥”ΫαΙϊά¥Ω¥Θ§Ήν–ΓΒΡΜυ”ΎTransformerΒΡΦήΙΙ‘Ύ“ΤΕ·…η±Η…œΫχ––ΆΤάμ–η“Σ12.5msΒΡ―”≥ΌΘ§ΕχΥϋΟ«ΒΡtop-1ΉΦ»Ζ¬ ΫωΈΣ69.0%ΓΘœύ±»÷°œ¬Θ§GhostNetV3‘Ύœ‘÷χΫΒΒΆΒΡ7.81ms―”≥Όœ¬¥οΒΫΝΥ77.1%ΒΡtop-1ΉΦ»Ζ¬ ΓΘΒ±«ΑΉνœ»ΫχΒΡΡΘ–ΆMobileFormer Βœ÷ΝΥ79.3%ΒΡtop-1ΉΦ»Ζ¬ Θ§ΒΪ―”≥ΌΈΣ129.58msΘ§’β‘Ύ ΒΦ ”Π”Ο÷– «ΈόΖ®Ϋ” ήΒΡΓΘœύ±»÷°œ¬Θ§GhostNetV3‘Ύ―”≥ΌΫωΈΣ18.87msΒΡ«ιΩωœ¬Θ§1.6
Χα…ΐΝΥΉΦ»Ζ¬ ÷Ν80.4%Θ§±»MobileFormerΩλ6.8
ΓΘ
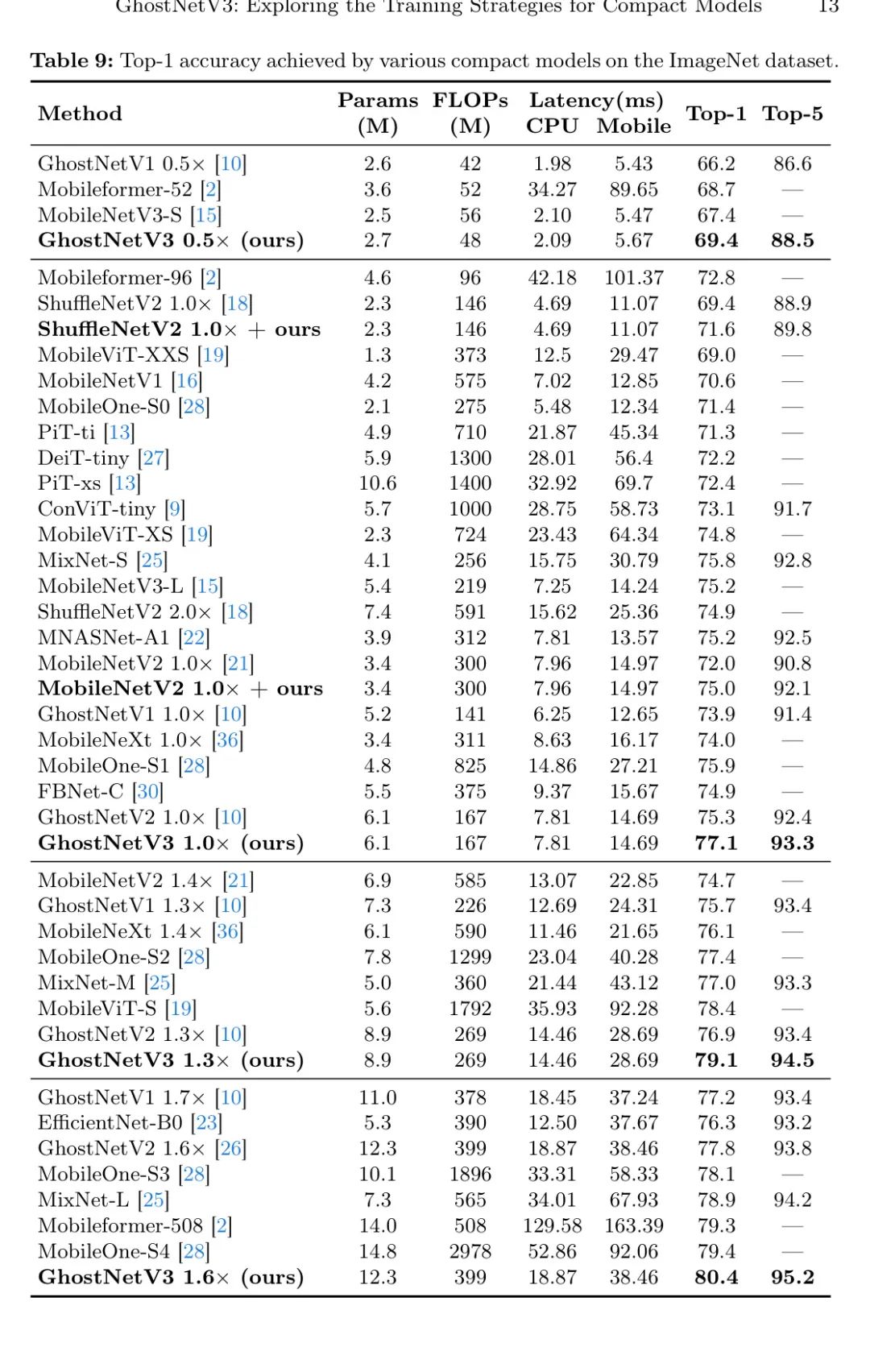
Ϋ”œ¬ά¥Θ§Ής’ΏΫΪGhostNetV3”κΤδΥϊΜυ”ΎCNNΒΡΫτ¥’–ΆΡΘ–ΆΫχ––±»ΫœΘ§Αϋά®MobileNetsΘ§ShuffleNetsΘ§MixNetΘ§MNASNetΘ§FBNetΘ§EfficientNetΘ§“‘ΦΑMobileOneΓΘΤδ÷–Θ§FBNetΓΔMNASNetΚΆMobileNetV3 «Μυ”ΎΥ―ΥςΒΡΡΘ–ΆΘ§Τδ”ύΒΡ « ÷Ε·…ηΦΤΒΡΡΘ–ΆΓΘΧΊ±π «Θ§FBNet≤…”ΟΝΥ”≤ΦΰΥ―Υς≤Ώ¬‘Θ§ΕχMNASNetΚΆMobileNetV3Υ―ΥςΦήΙΙ≤Έ ΐΘ§±»»γΡΘ–ΆΒΡΩμΕ»ΓΔΡΘ–ΆΒΡ…νΕ»ΓΔΨμΜΐ¬Υ≤®ΤςΒΡ¥σ–ΓΒ»ΓΘ
”κMobileNetV2œύ±»Θ§GhostNetV21.0
‘ΎΦΗΚθœύΆ§ΒΡ―”≥ΌΘ®7.81msΕ‘7.96msΘ©œ¬Θ§»ΓΒΟΝΥ5.1%ΒΡΗΡΫχΓΘGhostNetV21.3
“≤±»MobileNeXtΚΆEfficientNet-B0ΒΡtop-1ΉΦ»Ζ¬ ”–ΥυΧαΗΏΘ§Ζ÷±πΗΏ≥ωΝΥ3.0%ΚΆ2.8%ΓΘΧΊ±π «”κ«Ω¥σΒΡ ÷Ε·…ηΦΤΒΡMobileOneΡΘ–Άœύ±»Θ§GhostNetV31.0
‘Ύtop-1ΉΦ»Ζ¬ …œ±»MobileOne-S1ΗΏ≥ω1.2%Θ§ΕχΥυ–ηΒΡ―”≥Ό÷Μ”–“ΜΑκΓΘGhostNetV31.3
“≤±»MobileOne-S2ΒΡΉΦ»Ζ¬ ΗΏ≥ωΝΥ1.7%Θ§Εχ―”≥Ό≥…±ΨΫωΈΣ60%ΓΘ¥ΥΆβΘ§Β±GhostNet1.6
»ΓΒΟΝΥ±»MobileOne-S4ΗϋΗΏΒΡtop-1ΉΦ»Ζ¬ Θ®80.4% Ε‘79.4%Θ© ±Θ§MobileOne‘ΎCPU…œΒΡ―”≥Ό «GhostNetV3ΒΡ2.8
ΓΘ
‘ΎΫΪGhostNetV31.0
”κΜυ”ΎΥ―ΥςΒΡΫτ¥’ΡΘ–ΆΫχ––±»Ϋœ ±Θ§ΗΟΡΘ–Ά‘ΎCPUΚΆ ÷Μζ…œΒΡΆΤάμΥΌΕ»ΨυΩλ”ΎFBNet-CcitefbnetΘ§«“–‘ΡήΗΏ≥ω2.2%ΓΘ¥ΥΆβΘ§GhostNetV31.0
œύΫœ”ΎMobileNetV3ΚΆMAASNetΘ§‘Ύ±Θ≥÷œύΥΤ―”≥ΌΒΡΆ§ ±Θ§top-1ΉΦ»Ζ¬ ΧαΗΏΝΥ1.9%ΓΘ’β–©ΫαΙϊ÷ΛΟςΝΥΉς’ΏΧα≥ωΒΡ―ΒΝΖ≤Ώ¬‘‘ΎΜώ»Γ”≈–ψΫτ¥’ΡΘ–ΆΖΫΟφΘ§”≈”Ύœ÷”–ΒΡ ÷Ε·…ηΦΤΚΆΜυ”ΎΥ―ΥςΒΡΦήΙΙ…ηΦΤΖΫΖ®ΓΘ
ΆΦ5’Ι ΨΝΥΗς÷÷Ϋτ¥’–ΆΡΘ–ΆΒΡΉέΚœ–‘Ρή±»ΫœΓΘΉσΆΦΚΆ”“ΆΦΖ÷±πΥΒΟςΝΥ‘Ύ ÷Μζ…œ≤βΝΩΒΡFLOPsΚΆ―”≥ΌΓΘ÷ΒΒΟΉΔ“βΒΡ «Θ§Ής’Ώ―ΒΝΖΒΡGhostNetV2‘Ύ“ΤΕ·…η±Η…œ‘Ύ―”≥ΌΚΆtop-1ΉΦ»ΖΕ»÷°Φδ±μœ÷≥ωΉνΦ―ΒΡΤΫΚβΓΘ
ΤδΥϊΫτ¥’ΡΘ–ΆΈΣΝΥΫχ“Μ≤Ϋ’Ι ΨΥυΧα≥ω―ΒΝΖ≤Ώ¬‘ΒΡΩ…ά©’Ι–‘Θ§Ής’ΏΫΪΥϋΟ«”Π”Ο”Ύ―ΒΝΖΝμΆβΝΫ÷÷ΙψΖΚ Ι”ΟΒΡΫτ¥’ΡΘ–ΆΘΚShuffleNetV2ΚΆMobileNetV2ΓΘ±μ9÷–ΒΡΫαΙϊœ‘ ΨΘ§Ής’ΏΒΡ≤Ώ¬‘Ω…“‘Ζ÷±πΫΪShuffleNetV2ΚΆMobileNetV2ΒΡtop-1ΉΦ»Ζ¬ ΧαΗΏ2.2%ΚΆ3.0%ΓΘ
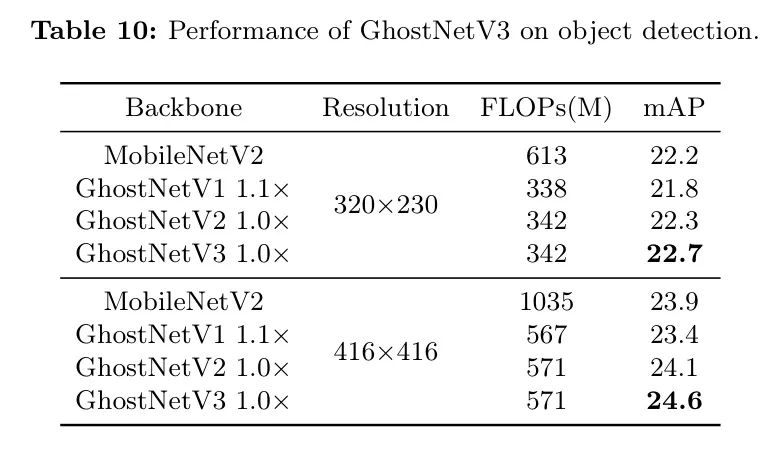
Extendtoobjectdetection
ΈΣΝΥΧΫΨΩ―ΒΝΖ ’Ψί «Ζώ“≤Ρή‘ΎΤδΥϊ ΐΨίΦ·…œ±μœ÷ΝΦΚΟΘ§Ής’ΏΫΪ Β―ιά©’ΙΒΫCOCO ΐΨίΦ·…œΒΡΡΩ±ξΦλ≤β»ΈΈώΘ§“‘―ι÷ΛΥϋΟ«ΒΡΖΚΜ·ΡήΝΠΓΘΫαΙϊ’Ι Ψ‘Ύ±μ10÷–ΓΘ÷ΒΒΟΉΔ“βΒΡ «Θ§Ζ÷άύ»ΈΈώ÷–ΒΡΕ¥≤λ“≤ ”Ο”ΎΡΩ±ξΦλ≤β»ΈΈώΓΘάΐ»γΘ§‘ΎΝΫ÷÷ Ι”ΟΒΡΖ÷±φ¬ …η÷Οœ¬Θ§GhostNetV3ΡΘ–ΆΖ÷±π“‘0.4ΚΆ0.5ΒΡmAP÷Β”≈”ΎGhostNetV2ΓΘ¥ΥΆβΘ§GhostNetV3‘ΎΆΤάμ ±Υυ–ηΒΡFLOPsΗϋ…ΌΘ§Ά§ ±–‘Ρή“≤≥§ΙΐΝΥMobileNetV2ΓΘ
6Conclusion
‘Ύ±ΨΈΡ÷–Θ§Ής’Ώ»ΪΟφ―–ΨΩΝΥ÷Φ‘ΎΧαΗΏœ÷”–Ϋτ¥’ΡΘ–ΆΒΡ–‘ΡήΒΡ―ΒΝΖ≤Ώ¬‘ΓΘ’β–©ΦΦ θΑϋά®÷Ί–¬≤Έ ΐΜ·ΓΔ÷Σ Ε’τΝσΓΔ ΐΨί‘ω«Ω“‘ΦΑ―ßœΑΦΤΜ°Βς’ϊΘ§«“‘ΎΆΤάμΙΐ≥Χ÷–Έό–ηΕ‘ΡΘ–ΆΦήΙΙΫχ–––όΗΡΓΘΧΊ±π «Θ§Ής’Ώ―ΒΝΖΒΡGhostNetV3‘ΎΉΦ»Ζ–‘ΚΆΆΤάμ≥…±Ψ÷°Φδ¥οΒΫΝΥΉν”≈ΤΫΚβΘ§’β“ΜΒψ“―Ά®ΙΐCPUΚΆ ÷ΜζΤΫΧ®ΒΟΒΫΝΥ―ι÷ΛΓΘΉς’ΏΜΙΫΪ‘ΎΤδΥϊΫτ¥’ΡΘ–ΆΘ§»γMobileNetV2ΚΆShuffleNetV2…œ”Π”ΟΥυΧα≥ωΒΡ―ΒΝΖ≤Ώ¬‘Θ§Ιέ≤λΒΫΉΦ»Ζ–‘ΒΡœ‘÷χΧα…ΐΓΘΉς’ΏœΘΆϊΉς’ΏΒΡ―–ΨΩΡήΈΣΈ¥ά¥ΗΟΝλ”ρΒΡ―–ΨΩΧαΙ©”–Φέ÷ΒΒΡΦϊΫβΚΆΨ≠―ιΓΘ
≤ΈΩΦ
GhostNetV3: ExploringtheTrainingStrategiesforCompactModels.
±ΨΈΡΖ÷œμΉ‘ arXivΟΩ»’―ß θΥΌΒί ΈΔ–≈ΙΪ÷ΎΚ≈Θ§«ΑΆυ≤ιΩ¥
»γ”–«÷»®Θ§«κΝΣœΒ cloudcommunity@tencent.com …Ψ≥ΐΓΘ
±ΨΈΡ≤Έ”κ?ΧΎ―Ε‘ΤΉ‘ΟΫΧεΖ÷œμΦΤΜ°? Θ§ΜΕ”≠»»Α°–¥ΉςΒΡΡψ“ΜΤπ≤Έ”κΘΓ