超越BEVFusion!DifFUSER:扩散模型杀入自动驾驶多任务(BEV分割+检测双SOTA)
超越BEVFusion!DifFUSER:扩散模型杀入自动驾驶多任务(BEV分割+检测双SOTA)

写在前面&笔者的个人理解
目前,随着自动驾驶技术的越发成熟以及自动驾驶感知任务需求的日益增多,工业界和学术界非常希望一个理想的感知算法模型,可以同时完成如3D目标检测以及基于BEV空间的语义分割在内的多个感知任务。对于一辆能够实现自动驾驶功能的车辆而言,其通常会配备环视相机传感器、激光雷达传感器以及毫米波雷达传感器来采集不同模态的数据信息,从而充分利用不同模态数据之间的互补优势,比如三维的点云数据可以为3D目标检测任务提供算法模型必要的几何数据和深度信息;2D的图像数据可以为基于BEV空间的语义分割任务提供至关重要的色彩和语义纹理信息,通过将不同模态数据的有效结果,使得部署在车上的多模态感知算法模型输出更加鲁棒和准确的空间感知结果。
虽然最近在学术界和工业界提出了许多基于Transformer网络框架的多传感、多模态数据融合的3D感知算法,但均采用了Transformer中的交叉注意力机制来实现多模态数据之间的融合,以实现比较理想的3D目标检测结果。但是这类多模态的特征融合方法并不完全适用于基于BEV空间的语义分割任务。此外,除了采用交叉注意力机制来完成不同模态之间信息融合的方法外,很多算法采用基于LSS中前向的2D到3D的视角转换方式来构建融合后的特征,但也存在着如下的一些问题:
- 由于目前提出的相关多模态融合的3D感知算法,对于不同模态数据特征的融合方式设计的还不够充分,造成感知算法模型无法准确捕获到传感器数据之间的复杂连接关系,进而影响模型的最终感知性能。
- 不同传感器采集数据的过程中难免会引入无关的噪声信息,这种不同模态之间的内在噪声,也会导致不同模态特征融合的过程中会混入噪声,从而造成多模态特征融合的不准确,影响后续的感知任务。
针对上述提到的在多模态融合过程中存在的诸多可能会影响到最终模型感知性能的问题,同时考虑到生成模型最近展现出来的强大性能,我们对生成模型进行了探索,用于实现多传感器之间的多模态融合和去噪任务。基于此,我们提出了一种基于条件扩散的生成模型感知算法DifFUSER,用于实现多模态的感知任务。通过下图可以看出,我们提出的DifFUSER多模态数据融合算法可以实现更加有效的多模态融合过程。

提出的算法模型与其它算法模型的结果可视化对比图
论文链接:https://arxiv.org/pdf/2404.04629.pdf
网络模型的整体架构&细节梳理
在详细介绍本文提出的基于条件扩散模型的多任务感知算法的DifFUSER的模块细节之前,下图展示了我们提出的DifFUSER算法的整体网络结构。
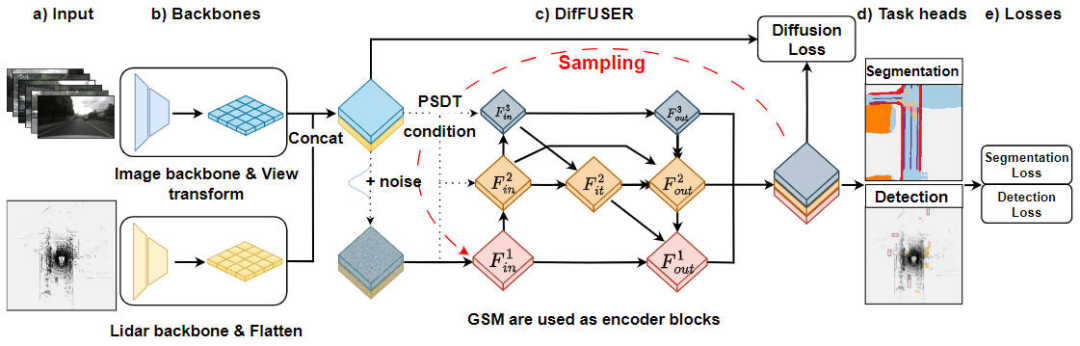
提出的DifFUSER感知算法模型网络结构图
通过上图可以看出,我们提出的DifFUSER网络结构主要包括三个子网络,分别是主干网络部分、DifFUSER的多模态数据融合部分以及最终的BEV语义分割、3D目标检测感知任务头部分。
- 主干网络部分:该部分主要对网络模型输入的2D图像数据以及3D的激光雷达点云数据进行特征提取用于输出相对应的BEV语义特征。对于提取图像特征的主干网络而言,主要包括2D的图像主干网络以及视角转换模块。对于提取3D的激光雷达点云特征的主干网络而言,主要包括3D的点云主干网络以及特征Flatten模块。
- DifFUSER多模态数据融合部分:我们提出的DifFUSER模块以层级的双向特征金字塔网络的形式链接在一起,我们把这样的结构称为cMini-BiFPN。该结构为潜在的扩散提供了可以替代的结构,可以更好的处理来自不同传感器数据中的多尺度和宽高详细特征信息。
- BEV语义分割、3D目标检测感知任务头部分:由于我们的算法模型可以同时输出3D目标检测结果以及BEV空间的语义分割结果,所以3D感知任务头包括3D检测头以及语义分割头。此外,我们提出的算法模型涉及到的损失则包括扩散损失、检测损失和语义分割损失,通过将所有损失进行求和,并通过反向传播的方式来更新网络模型的参数。
接下来,我们会仔细介绍模型中各个主要子部分的实现细节。
融合架构设计(Conditional-Mini-BiFPN,cMini-BiFPN)
对于自动驾驶系统中的感知任务而言,算法模型能够对当前的外部环境进行实时的感知是至关重要的,所以确保扩散模块的性能和效率是非常重要的。因此,我们从双向特征金字塔网络中得到启发,引入一种条件类似的BiFPN扩散架构,我们称之为Conditional-Mini-BiFPN,其具体的网络结构如上图所示。
通过上图展示出的框架图可以看出,由2D图像主干网络以及3D点云主干网络输出的特征经过处理得到的三个初始的模块分别为
、
以及
,用于处理部分被掩膜盖住的原始特征
以及扰动的BEV特征
,其中
用于指导模块的扩散过程,从而实现细化BEV空间的特征,然后利用自上而下以及自下而上的双向融合过程来生成最终的BEV特征
、
以及
。具体而言,相关的过程可以表述如下:
其中,
代表Swish激活函数,
代表
和
的中间融合结果,
通过
、
以及
的混合计算得到结果。
以及
分别是加权因子,
和
的构建方式与
的方式类似,最终的特征图则是
、
以及
三个特征沿着通道进行拼接的结果,进而用于后续完成3D目标检测以及基于BEV空间的语义分割任务。
渐进传感器Dropout训练(PSDT)
对于一辆自动驾驶汽车而言,配备的自动驾驶采集传感器的性能至关重要,在自动驾驶车辆日常行驶的过程中,极有可能会出现相机传感器或者激光雷达传感器出现遮挡或者故障的问题,从而影响最终自动驾驶系统的安全性以及运行效率。基于这一考虑出发,我们提出了渐进式的传感器Dropout训练范式,用于增强提出的算法模型在传感器可能被遮挡等情况下的鲁棒性和适应性。
通过我们提出的渐进传感器Dropout训练范式,可以使得算法模型通过利用相机传感器以及激光雷达传感器采集到的两种模态数据的分布,重建缺失的特征,从而实现了在恶劣状况下的出色适应性和鲁棒性。具体而言,我们利用来自图像数据和激光雷达点云数据的特征,以三种不同的方式进行使用,分别是作为训练目标、扩散模块的噪声输入以及模拟传感器丢失或故障的条件,为了模拟传感器丢失或故障的条件,我们在训练期间逐渐将相机传感器或激光雷达传感器输入的丢失率从
增加到预定义的最大值
。整个过程可以用下面的公式进行表示:
其中,
代表当前模型所处的训练轮数,通过定义dropout的概率
用于表示特征
中每个特征被丢弃的概率。通过这种渐进式的训练过程,不仅训练模型有效去噪并生成更具有表现力的特征,而且还最大限度地减少其对任何单个传感器的依赖,从而增强其处理具有更大弹性的不完整传感器数据的能力。
门控自条件调制扩散模块(GSM Diffusion Module)
与传统的扩散模型所采用的条件不同,我们设计的门控自条件调制扩散模块利用时间
以及部分掩码样本
中包含的传感器信息来指导扩散过程。这就需要在噪声上具有更强的条件来塑造扩散轨迹以生成高质量的特征,进而确保整个扩散过程更加侧重于特征增强,为后续的感知任务提供更具表现力的特征。
具体而言,门控自条件调制扩散模块的网络结构如下图所示
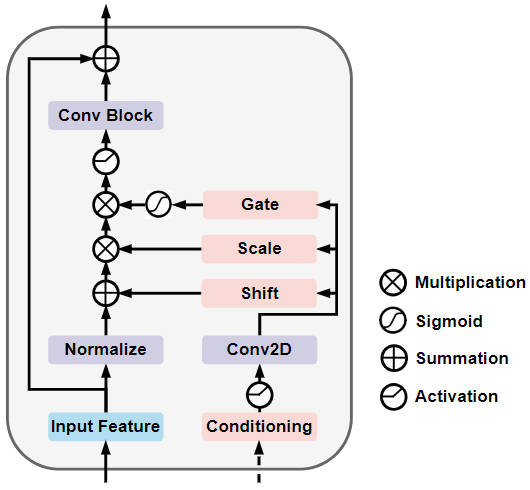
门控自条件调制扩散模块网络结构示意图
通过上图可以看出,门控自条件调制扩散模块由类似的特征线性调制进行封装,该调制过程根据条件
动态调整扩散参数,相关公式定义如下:
其中,参数
、
和
通过缩放和移动调制输入特征
,
作为sigmoid门控自条件的元素,根据特征元素本身重新调整层激活值。
实验结果&评价指标
定量分析部分
为了验证我们提出的算法模型DifFUSER在多任务上的感知结果,我们主要在nuScenes数据集上进行了3D目标检测以及基于BEV空间的语义分割实验。
首先,我们比较了提出的算法模型DifFUSER与其它的多模态融合算法在语义分割任务上的性能对比情况,具体的实验结果如下表所示:

不同算法模型在nuScenes数据集上的基于BEV空间的语义分割任务的实验结果对比情况
通过实验结果可以看出,我们提出的算法模型相比于基线模型而言在性能上有着显著的提高。具体而言,BEVFusion模型的mIoU值只有62.7%,而我们提出的算法模型已经达到了69.1%,具有6.4%个点的提升,这表明我们提出的算法在不同类别上都更有优势。此外,下图也更加直观的说明了我们提出的算法模型更具有优势。具体而言,BEVFusion算法会输出较差的分割结果,尤其在远距离的场景下,传感器错位的情况更加明显。与之相比,我们的算法模型具有更加准确的分割结果,细节更加明显,噪声更少。

提出算法模型与基线模型的分割可视化结果对比
此外,我们也将提出的算法模型与其它的3D目标检测算法模型进行对比,具体的实验结果如下表所示

不同算法模型在nuScenes数据集上的3D目标检测任务的实验结果对比情况
通过表格当中列出的结果可以看出,我们提出的算法模型DifFUSER相比于基线模型在NDS和mAP指标上均有提高,相比于基线模型BEVFusion的72.9%NDS以及70.2%的mAP,我们的算法模型分别要高出1.8%以及1.0%。相关指标的提升表明,我们提出的多模态扩散融合模块对特征的减少和特征的细化过程是有效的。
此外,为了表明我们提出的算法模型在传感器故障或者遮挡情况下的感知鲁棒性,我们进行了相关分割任务的结果比较,如下图所示。
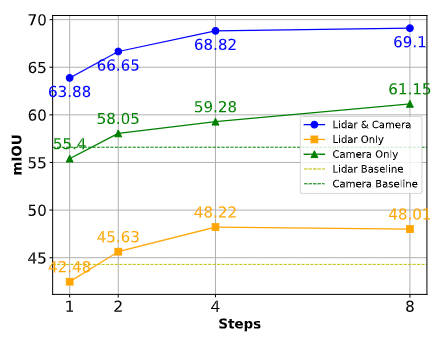
不同情况下的算法性能比较
通过上图可以看出,在采样充足的情况下,我们提出的算法模型可以有效的对缺失特征进行补偿,用于作为缺失传感器采集信息的替代内容。我们提出的DifFUSER算法模型生成和利用合成特征的能力,有效地减轻了对任何单一传感器模态的依赖,确保模型在多样化和具有挑战性的环境中能够平稳运行。
定性分析部分
下图展示了我们提出的DifFUSER算法模型在3D目标检测以及BEV空间的语义分割结果的可视化,通过可视化结果可以看出,我们提出的算法模型具有很好的检测和分割效果。

结论
本文提出了一个基于扩散模型的多模态感知算法模型DifFUSER,通过改进网络模型的融合架构以及利用扩散模型的去噪特性来提高网络模型的融合质量。通过在Nuscenes数据集上的实验结果表明,我们提出的算法模型在BEV空间的语义分割任务中实现了SOTA的分割性能,在3D目标检测任务中可以和当前SOTA的算法模型取得相近的检测性能。