NVIDIA杰出科学家讲述视觉语言模型如何革命性地推动边缘AI的发展
NVIDIA杰出科学家讲述视觉语言模型如何革命性地推动边缘AI的发展

本文整理自:

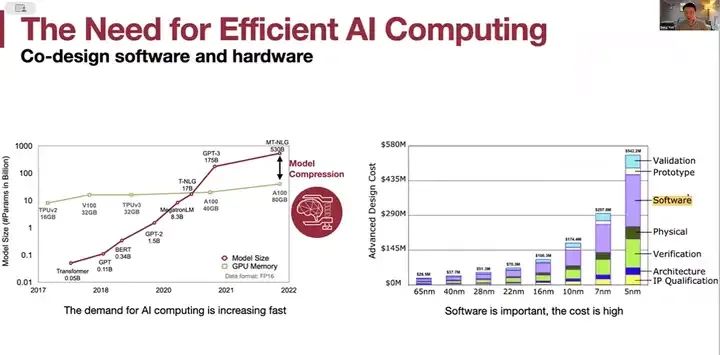
对高效AI计算的需求非常大。这是绿色表示的计算供应与红色表示的需求之间的对比。对AI计算的需求增长得非常快,而软件的重要性也日益凸显。从65纳米到5纳米,先进技术节点的成本非常高,软件成本也在不断增加,并且变得越来越重要,以应对高效的计算需求。我之前的工作包括深度压缩和EIE,通过剪枝和量化,我们可以压缩神经网络模型并去除冗余计算。我们试图减少工作量,拒绝或避免那些无效的工作,比如避免零值和使用更少的位进行处理,以及高效推理引擎。
我之前的工作包括深度压缩和EIE,通过剪枝和量化,我们可以压缩神经网络模型并去除冗余计算。我们试图减少工作量,拒绝或避免那些无效的工作,比如避免零值和使用更少的位进行处理,以及高效推理引擎。我们首次引入了权重稀疏性神经网络加速和剪枝,自2015、2016年左右以来,稀疏性变得越来越流行,近年来有大量相关出版物。高效机器学习项目的目标是通过算法和系统协同设计,缩小计算供应与AI计算需求之间的差距。
我们希望降低延迟、减少内存、降低功耗和能量消耗,同时提高吞吐量、准确性和最重要的可扩展性。
因此,我们致力于软件和硬件的协同设计,既针对小型模型,也针对最近的大型语言模型。我们关注于ST模型和稀疏模型,如何加速稀疏性并得到系统和其他支持。全精度模型与量化模型在推理和训练方面的对比,从判别模型到最近的生成模型,都使用了扩散技术。从单一模态到多模态,这是今天演讲的重点——多模态视觉语言模型。我们还有一个关于量子机器学习的CI项目。
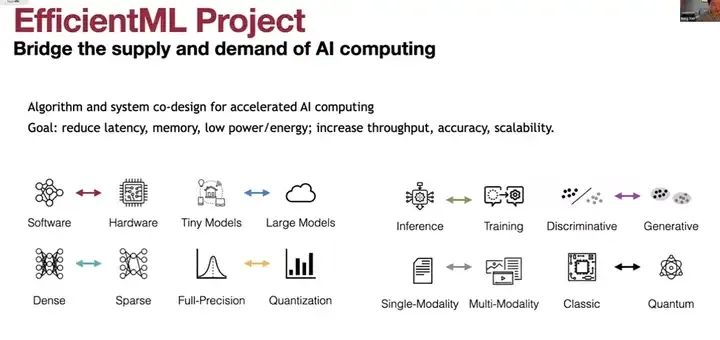
这是我们之前的工作——K机器学习与MCET。K机器学习的目标是设计轻量级的神经网络,以适应低成本、低功耗的设备,因为在数十亿个物联网设备中,MCU网络和P19到2021年,我们用了两年的时间推动了这个边界。我们将内存消耗从2256千字节压缩到了仅约32千字节,而准确性实际上还在增加。从MC V1到MC V2,我们使用仅30千字节的ICE RAM,就能将模型进一步压缩四倍,并能在微控制器上部署多个模型。
例如,这里有一个基于补丁的推理演示,展示了我们的MCET V2模型在搭载Cortex M7微控制器的OpenMV摄像头上的运行情况。这个设备非常小,甚至比AirPods还小。这个演示正在运行人员检测功能,例如,当有人在远离设备的地方坐着时,我们的模型能够检测到这个人。这对于资源有限的微型设备或微控制器来说是非常困难的,而我们的方法可以解决这个问题。
现在,有一个人从右向左走,也被我们的模型检测到了。为了节省时间,我们继续下一章的内容,不仅是在设备上进行推理,还有训练。在这个视频中,我们展示了我们可以在设备上进行训练,例如Tiny Training。设备上的训练可以帮助我们定制模型,但这更具挑战性,因为我们需要在边缘设备上本地执行反向传播,这需要存储那些中间激活值,这与推理不同,需要更多的内存占用。
为了解决这个问题,我们提出了8位量化训练中的量化感知缩放,以稳定训练与推理之间的权重更新比率。然后,我们使用稀疏更新,我们发现并非所有层都贡献同等,因此我们可以稀疏更新少数几层。在这里,我们有两个按钮来向模型提供本地标签,所有操作都在这个设备上本地进行。
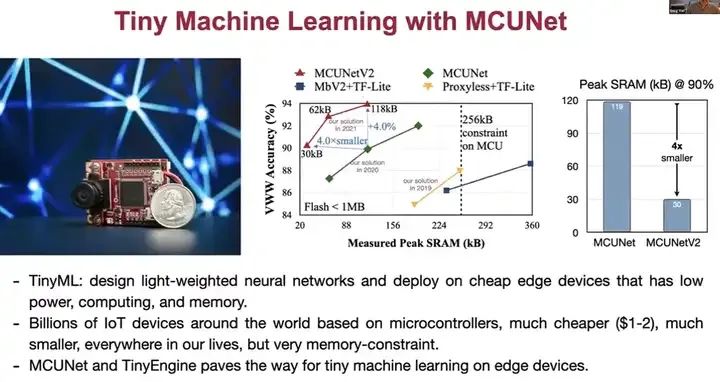
这个演示正在运行人员检测功能,例如,当有人在远离设备的地方坐着时,我们的模型能够检测到这个人。这对于资源有限的微型设备或微控制器来说是非常困难的,而我们的方法可以解决这个问题。现在,有一个人从右向左走,也被我们的模型检测到了。

为了节省时间,我们继续下一章的内容,不仅是在设备上进行推理,还有训练。在这个视频中,我们展示了我们可以在设备上进行训练,例如Tiny Training。设备上的训练可以帮助我们定制模型,但这更具挑战性,因为我们需要在边缘设备上本地执行反向传播,这需要存储那些中间激活值,这与推理不同,需要更多的内存占用。
为了解决这个问题,我们提出了8位量化训练中的量化感知缩放,以稳定训练与推理之间的权重更新比率。然后,我们使用稀疏更新,我们发现并非所有层都贡献同等,因此我们可以稀疏更新少数几层。

在这里,我们有两个按钮,用于在本地向模型提供标签。所有操作都在这台设备上本地进行,该设备只有512千字节的SRAM用于模型,以及两兆字节的闪存。最后,我们设计了这个微型训练引擎,以实现量化感知缩放和稀疏更新。经过20个周期后,我们可以进行测试。现在我们可以看到,红色表示有人,绿色表示无人,分类非常流畅。

基本上,这就是1.0版本的Edge AI基础模型,它可以用于各种任务,如医疗成像、自动驾驶、智能制造、机器翻译等。对于不同的任务,我们需要不同的模型和不同的数据,而且缺乏负样本确实阻碍了某些用例,例如异常检测。由于训练图像较小,且泛化能力有限,很容易遇到那些特殊情况的失败。因此,2.0版本基本上要求我们使用具有世界知识的通用模型,通过利用Transformer大型语言模型和大容量,
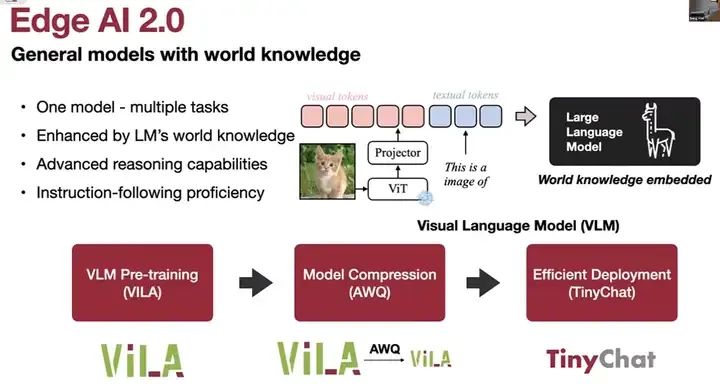
2.0版本的基本要求是,我们需要使用具有世界知识的通用模型。这主要通过利用Transformer大型语言模型的大容量技术来实现。我们的目标是创建一个能够处理多个不同任务且具备零样本学习能力的单一模型。这种能力得益于大型语言模型、世界知识、高级推理能力、上下文学习能力、融合学习能力和视觉思维链能力。同时,我们也希望这个模型能够遵循各种指令,无论是地标识别、驾驶、患者监测还是智能制造。之后,我们将在Jetson Orin平台上看到多个实例,展示我们如何使用单个视觉语言模型来处理所有这些情况。
本次演讲包含三个部分。首先,我们将讨论视觉语言模型的预训练,特别是即将在今年CVPR上发布的ViLA视觉语言模型。这款拥有27亿参数的ViLA模型可以部署在Jetson Orin Nano上。
接着,我们将探讨大型语言模型的模型压缩量化问题。特别是,我们将讨论AWQ(Activation Aware Quantization)技术,这是NVIDIA Chat With RTX和TensorRT-LLM背后的技术,该技术计划在今年发布,可以对视觉语言模型和大型语言模型进行权重量化,以避免权重内存带宽瓶颈,从而将大型ViLA模型压缩为仅使用四位的小型ViLA模型。
最后,我将介绍一个名为TinyChat的高效部署引擎,它能够在移动设备上部署视觉语言模型ViLA和其他大型语言模型。
边缘设备上的ViLA
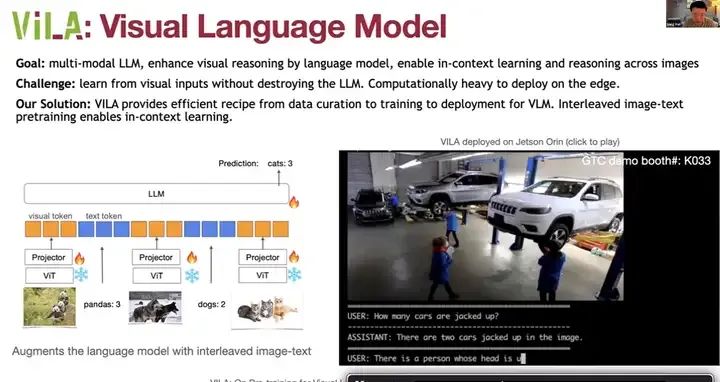
ViLA的目标是支持多模态大型语言模型,既包含视觉AI,也包含语言,通过语言模型增强视觉推理能力,并实现跨多个图像的上下文学习和推理。这里不仅仅涉及单个图像,而是多个图像。上下文学习意味着我们可以只提供上下文和一些示例,而无需明确说明任务是什么。例如,这里有三只狗和两只熊猫,然后我们展示这张图像,你就能明白任务是计算动物的数量,它会进行三分类和计数。
我们想要从视觉提示中学习,但我们不希望部署庞大的语言模型。另一个挑战是,视觉和语言部分同时存在时,在边缘设备上的计算负担很重。我们的解决方案是ViLA,它提供了从数据整理到训练再到部署的视觉语言模型的高效方案。我们使用图像文本对进行训练,例如,这里展示的是图像文本数据集格式,它支持这种跨上下文的学习。
通过这种方式,ViLA能够在不破坏大型语言模型的前提下,从视觉输入中学习,并实现高效的边缘设备部署。
所以,我们可以将所有的标记(Token)拼接在一起,首先是ViT提取的视觉标记,然后是一个投影器。在这个投影器之后,我们将其与文本标记拼接在一起。这样,所有的内容都变成了标记。一旦所有内容都变成了标记,我们就可以将其输入到大型语言模型中。与先前的工作不同,我们打开了这个大型语言模型,并找到了与其一起调整的方法,也就是与视觉投影器一起调整。我们发现这对于实现多图像推理至关重要。因此,我们可以在实际的设备上部署它,例如Jetson Orin。
例如,给定这张图像,我们可以询问任何安全问题。我可以告诉你,有一个人正在绳子后面躲藏,并且存在几个与安全相关的问题,比如掉下来的风险等。在工厂场景中,我们可以回答有多少辆车被顶起来了,答案是两辆车被顶起来了,并且有一个人的头在车下,戴着橙色的手套。回答是即时的,非常快。我们还可以识别出那辆车实际上是吉普车。
我们还可以询问图像中情况的不寻常之处。这是一张卫星图像还是无人机图像?我可以告诉你,路上有大量的汽车,导致交通显著增加。这张图像有什么不寻常之处呢?可能是自动驾驶场景中的边缘情况。我们可以看到很多鹿,鹿过马路并不常见,那么司机应该鸣笛提醒动物吗?你可以看到,它非常擅长处理这种边缘情况,而且只使用了一个模型。一般来说,不建议对动物鸣笛。好的,这展示了使用单一模型处理这些边缘情况的强大能力。

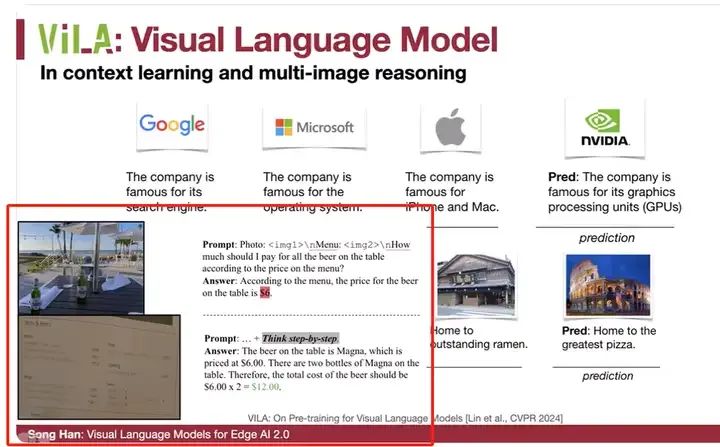
让我们来看看ViLA的上下文学习和多图像推理能力。例如,给定这个例子,我们首先展示了一个标志,并告诉模型这个公司因搜索引擎而闻名。接着是另一个标志,它因操作系统而闻名。然后是苹果标志,它因iPhone和Mac而闻名。当我们给出Nvidia标志时,它可以推断出它因GPU而闻名。这是模型在没有明确告知任务的情况下,从上下文中推断出的结果。
类似地,对于这张图像,它因炸鸡而闻名;这张图像因无与伦比的炸鱼薯条而闻名;这张图像是跑男节目的家;而这张图像则是披萨之家的代表。

我们还可以进行多图像推理。例如,根据菜单上的价格,我应该为桌上的所有啤酒支付多少钱?最初,模型给出的答案是错误的,但我们可以启用视觉思维链提示,让它逐步思考。然后,它可以识别出桌上的啤酒是Magna品牌,通过OCR技术识别出这是Magna,价格为6美元。模型还可以将Magna与菜单上的条目关联起来,确定每瓶的价格为6美元。接下来,模型进行计数检测,发现有两瓶Magna,因此总费用是6乘以2,即12美元。
另一个多图像推理的案例是基于这些图像来推断温度的变化。从1984年、2004年和2012年的图像中,我们可以看到北极冰层覆盖的变化。这暗示着冰层覆盖在逐年减少。通过比较这些不同年份的图像,我们可以得出关于气候变化的重要结论。

在这项研究中,我们给出了几个上下文学习示例。给定一些上下文,我们提供了几个简短的示例,然后给出目标图像。你可以告诉它进行预测,例如进行OCR(光学字符识别)、进行数学计算、写诗,以及特殊风格。

这对于现实世界中的许多应用非常有用,例如自动驾驶。我们可以启用可解释的自动驾驶,如果正在驾驶,系统可以判断是否应该向行人鸣笛,并说明鸣笛是不恰当的、隐含的且不尊重人的。这里包含了很多常识和世界知识。
我们不仅仅是从图像中学习,还从这种PL的轻量级学习中学习,而这种常识是从语言中学习的,所以语言确实有助于视觉感知。同样,对于驾驶员监控系统,我们可以询问驾驶员是否分心、是否在打电话、车里有多少人、乘客坐在哪里等问题。我们不需要为每个任务训练特定的模型,而只需使用单个模型来处理不同的任务。

我们还可以用它来进行无人机监控,检查设施是否看起来良好、状况是否良好,以及是否需要立即维护。

在医疗保健方面,与其让护士24小时盯着病人以监测其状况,我们可以使用V进行监测,了解病人的状态,如是否处于危急状况、是否在呼吸机上、是否在医院病床上睡觉等。

这里有一个有趣的训练示例。这个训练是关于什么的?是关于心肺复苏术(CPR)。实践会对图像中的病人造成疼痛吗?实际上,这是一个模拟人,不应该造成疼痛,而V可以正确地回答这一点。这是一个模拟,不是真实的病人,不会造成疼痛。它是一个假人,不是真人,所以它理解得很好,并能进行推理。

ViLA在智能工厂中的应用非常广泛。例如,我们可以询问Robert机械臂拾取了多少芯片袋。从这段短视频中,我可以看出机械臂拾取了两个芯片袋。这八个输入图像是样本,每秒两帧。机械臂拾取芯片袋需要多长时间?我可以进行一些推理并谈论这个问题,大约需要1.5秒。

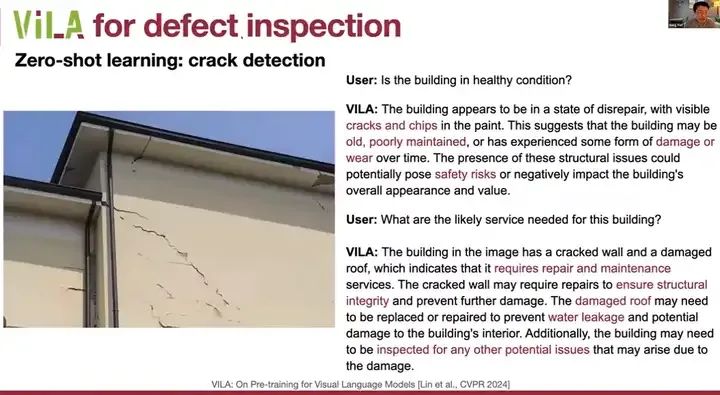
此外,我们还可以进行缺陷检查。处于健康状态的建筑实际上会有裂缝和碎片,都需要妥善维护。损坏、战争和安全隐患都需要进行修理和维护,因此对于监测和缺陷检查非常有帮助。
LLM Compression:低比特量化
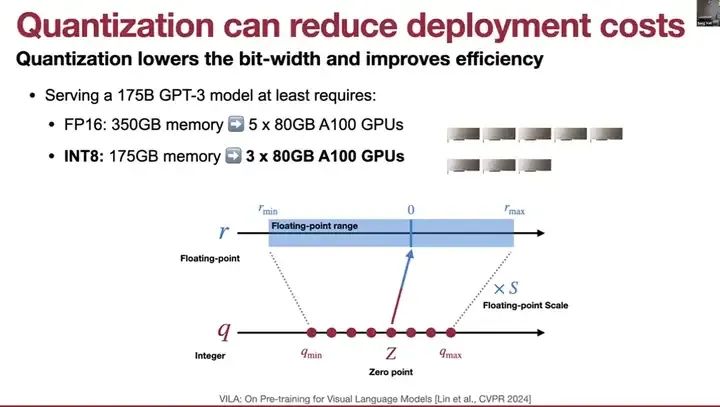
那么,我们如何在设备上部署如此大型的模型呢?这就涉及到了大型语言模型压缩和低比特量化的概念。量化可以降低部署成本,例如,它可以将浮点范围映射到整数范围,从而减少服务成本。
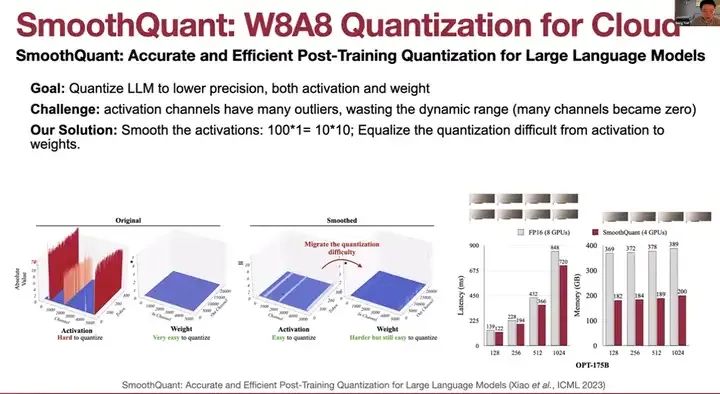
那么,我们如何在设备上部署如此大型的模型呢?这就涉及到了大型语言模型压缩和低比特量化的概念。量化可以降低部署成本,例如,它可以将浮点范围映射到整数范围,从而减少服务成本。然而,传统的量化方法虽然广泛应用于视觉模型,但并不适用于大型语言模型,因为这些输出层的瓶颈问题。我们发现激活通道有许多异常值,浪费了动态范围,因为许多通道会被钳制为零。
我们的解决方案是平滑激活。这是激活,这是权重,这是平滑前,这是平滑后。100 * 1 映射为 10 * 10,所以100代表一个大通道,这是一个小通道,我们使它们相等,这样激活就会更平滑。我们将量化难度从激活转移到权重,因此激活更加平滑。结果,我们可以保持准确性,甚至更快,并且将GPU数量减少一半。这就是为云端设计的8位权重和8位激活量化,带有平滑量化。
但是,对于边缘设备,我们需要单批次服务,而w8A8无法解决低计算强度与编码之间的问题。在单批次推理中,内存与权重绑定。因此,我们需要激进地对权重进行量化,以减少到最低位数。那么,我们能否在不损失准确性的情况下将量化方式降低到4位呢?

这就是AWQ,一种在设备上广泛使用的LLM(大型语言模型)量化方法。它是激活权重量化的常用配方,用于在边缘设备上压缩和加速LM(语言模型),如Jetson Orin或AIPC。这是一种非常广泛使用的方法,其思路是将权重量化为4位,而激活和算术运算保持在fp16(16位浮点数)格式,以解决权重的内存带宽瓶颈问题。同时,由于激活和计算不是瓶颈,我们可以很好地保持准确性。这里的关键是,我们想要利用激活感知,根据激活幅度来缩放并保留关键的权重通道。虽然我们在量化权重,但不应该只看权重的幅度,而应该看激活的幅度。如果激活通道较大,我们应该保留该权重。一种保留权重的方法是为当前通道引入fp16,但fp16在引入这种混合精度场景时并不友好。我们发现,通过简单地放大这个通道并保护这个通道,如果将这个通道放大两倍,就相当于有效地增加了一位;如果放大四倍,就相当于有效地增加了两位。对于某些通道,如果激活很小,我们实际上会缩小它们。因此,平均而言,我们使用了与在激活和权重之间转移量化难度类似的方法,类似于平滑量化。AWQ是Nvidia Chat with RTX上使用的支持技术。
这是一个演示,我们早在去年夏天之前就做过,编写一个程序以C对数组进行排序,该程序在上本地运行,笔记本电脑速度非常快,
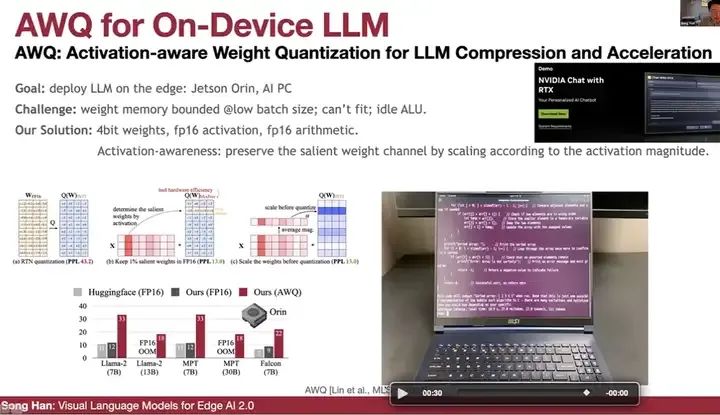
AWQ的优势在于它准确、简单且易于实现,无需反向传播,对训练数据集的依赖度也较低,与基于回归的方法(如GPTQ)相比,这是一个与AWQ相比的示例。
与GPTQ相比,当你拥有这个——这是校准序列的数量。如果序列变得更小,GPTQ的性能会迅速下降,但AWQ则保持非常稳定。AWQ并不依赖于校准集,因此它具有更好的泛化能力,无需过度拟合校准数据集。在不同数据集上,如果我们使用PubMed进行校准并在PubMed上进行评估,GPTQ和Enron都表现良好。但是,如果你在一个数据集上进行校准,却在另一个数据集上进行评估,我们的方法AWQ对新的数据集更具鲁棒性。因此,AWQ在多模型语言模型方面表现得相当出色。

AWQ在多模型语言模型上表现得很好。这是Open Flamingo用于字幕生成的情况,RTN模型说是一个模型飞机在天空中飞翔,但AWQ说是一个玩具飞机坐在草地上;RTM方法说是一个男人抱着一只小象,而AWQ则说是一个人与大象合影。

因此,SmoothQuant和AWQ影响最近被广泛使用,但还有Nvidia TensorRT-LLM、IBM Granite VM、Berkeley vLLM, FastChat,以及Hugging Face Transformer量化API和几家初创公司以及开源项目。

TinyChat: 高效的LLM推理引擎
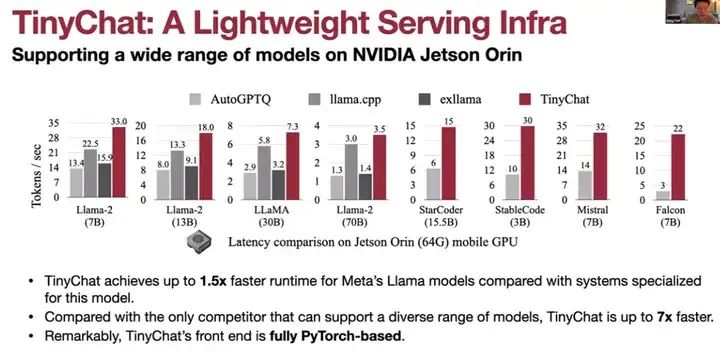
我们有了ViLA模型,也有了压缩和量化技术,现在让我们使用TinyChat进行部署,它是一个高效的边缘LLM推理引擎。TinyChat是一个轻量级的服务基础设施,基于Python,既轻量又高效。Hugging Face使用起来非常简单但速度较慢,TensorRT-LLM效率很高但使用较难,基于C++。而TinyChat既高效又轻量,它是Python原生的,可以与其他堆栈(如VLM)组合使用。

因此,与其他系统相比,TinyChat在Llama模型上的速度提升了高达1.5倍。这是在Jetson Orin上与其他Llama模型和不同编码模型(如Mistral和Falcon)比较的结果。
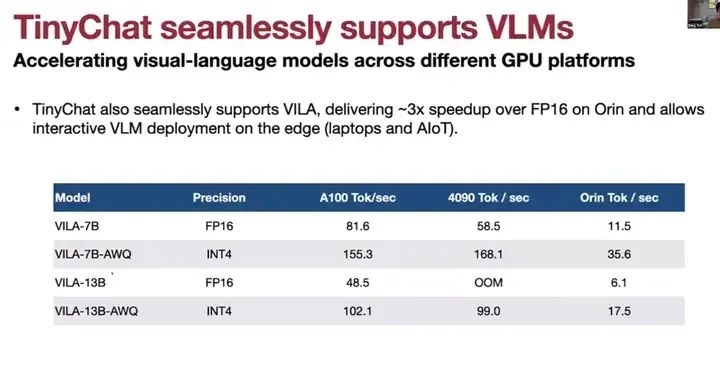
TinyChat同样可以支持视觉语言模型,以在不同GPU平台上加速视觉语言模型的运行速度,相比FP16版本的模型,速度提升高达3倍。这里展示的是4090显卡、Orin和A100显卡的测试结果。我们正在比较FP16、INT4 AWQ ViLA、FP 16 ViLA以及AWQ ViLA的性能。特别是在Orin平台上,使用AWQ ViLA-7B模型可以达到每秒运行35个标记的速度。
这是一个使用Jetson Orin运行Lama 2模型的示例,
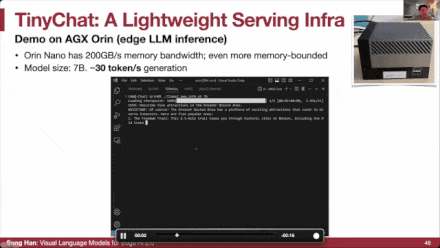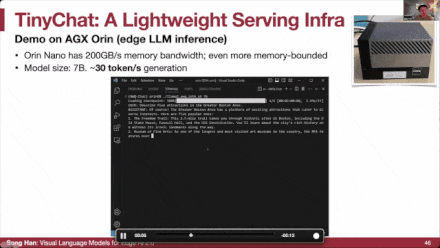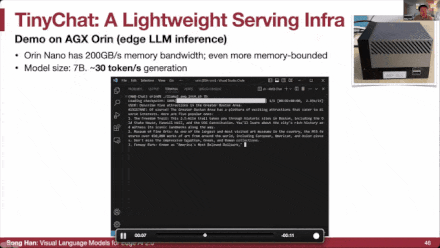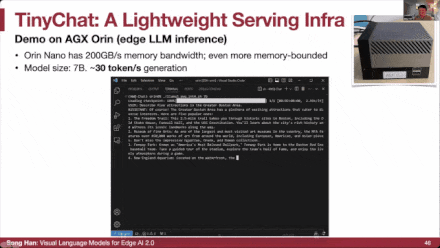
不仅限于Jetson Orin,我们还基于Jetson Orin Nano构建了这款TinyChat计算机。我们3D打印了这个盒子。现在我们来聊聊波士顿的一些景点,比如美术博物馆、哈佛广场等等。这就是后方的7B Lama模型,你可以看到它实际上是在后方的一个非常小的Jetson Orin NANO上运行的。

这里的量化方法使用的是AWQ,而TinyChat则是支持我AIPC的技术。我们模拟支持个人笔记本电脑,无论是Intel还是ARM CPU。我们构建的TinyChat引擎完全是从零开始构建的,没有任何依赖项。我们有适用于GPU的TinyChat,也有TinyChat引擎的两个版本,但实际上,它们使用的是类似的技术。因此,如果你有ARM设备,请随时下载TinyChat引擎,因为它没有依赖项,可以同时在Intel和ARM CPU上编译和部署。

简短总结如下:TinyChat和ViLA为ViLA 2.0利用基础模型实现更好的泛化能力、融合学习能力和更丰富的世界知识铺平了道路。首先,我们使用ViLA为多模型能力提供大型语言模型的多模型能力;然后,我们使用AWQ将ViLA量化为4位,通过使用激活感知实现4倍权重减少;最后,我们使用高效的推理框架TinyChat将ViLA部署在Jetson Orin和Jetson Orin Nano上。我们制作了一个演示,欢迎大家在ViIA.hanlab.ai上尝试ViLA。所有内容都是开源的,包括ViLA的所有训练代码(使用了128个GPU),以及量化和部署的配方。如果你有笔记本电脑,你可以访问ViLA并使用那里的代码在笔记本电脑上运行ViLA。
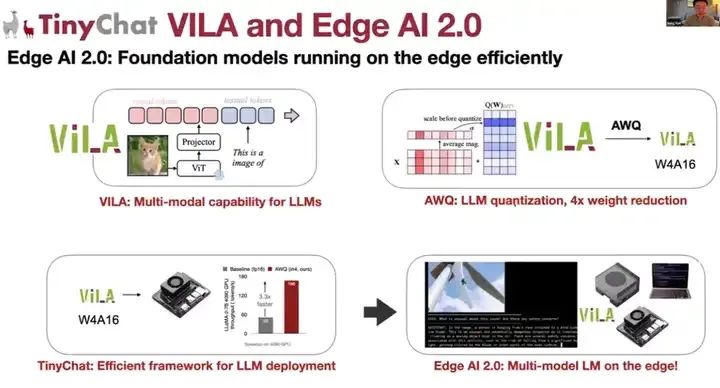
总之,Edge AI 2.0需要全栈优化,ViLA是一个非常好的应用侧示例,它轻量级,2.7B大小,利用跨模态图像文本实现上下文学习能力以及多图像推理能力和不同场景下的泛化能力。 因此,这就是计算模型压缩的需求,它弥补了计算供应与需求之间的鸿沟,通过量化模型来解决内存带宽问题,并使用TinyChat这一高效的系统进行部署,从而提供计算供应。
