数据处理:A New Coefficient of Correlation

数据处理:A New Coefficient of Correlation

引入
假设告诉你有一种新的方法可以像相关性一样衡量两个变量之间的关系,甚至可能更好,你会怎么想呢?具体来说,2020年发表了一篇名为《一个新的相关系数》的论文,介绍了一种新的衡量方法,当且仅当两个变量独立时等于0,当且仅当一个变量是另一个变量的函数时等于1,而且具有一些良好的理论性质,可以进行假设检验,同时在实际应用中对数据不做任何假设。
在深入讨论[1]之前,让我们简要谈谈更传统的相关性衡量方法是如何工作的。
相关性 复习
比起流行的相关系数,有一些工具更常用(也更容易被误用)来帮助理解数据。皮尔逊相关系数(Pearson’s r),几乎在每个统计学/商业课程中都会教授的样本相关系数,可以说是每个数据专业人士必须熟悉的头号工具。其原因有很多,其中之一是它既易于使用又易于解释。提醒一下,样本相关系数衡量了两个变量之间的线性关系,并可以使用以下公式计算。
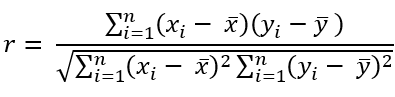
最后提醒一下,这个数值的范围可以从-1到+1,负值表示被测量的两个变量之间存在反向线性关系,正值则表示相反的情况。需要注意的是,目前为止我们一直强调的是对线性关系的测量。线性关系可以理解为关系的形状在某种程度上可以用一条直线来描述。

不足为奇的是,我们在现实世界中很少看到直线关系。因此,多年来已经发展出了一些新的衡量标准,例如斯皮尔曼相关系数ρ(rho)和肯德尔相关系数τ(tau)。这些新方法更擅长发现单调性关系,而不只是直线关系,这使得它们更为可靠,因为直线关系实际上是单调性关系的一个特定实例。简而言之,单调性关系可以理解为始终上升或始终下降的关系。
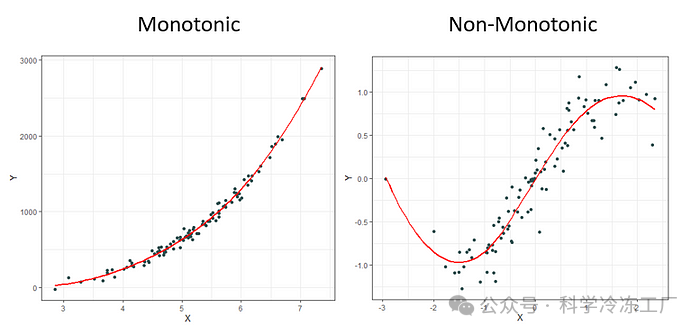
通常,我们使用相关性分析的目的,并非仅仅是为了找出两个变量之间的线性或单调性联系,而是为了探究它们之间是否存在某种联系。然而,如果变量间的关系既不是线性的也不是单调的,现有的相关性度量方法就不太有效。
观察下面的图表,它们明显展示了两个变量之间的紧密联系,但常用的相关性分析技巧主要擅长识别单调性关系。

尽管存在显而易见的不足,这些相关性度量仍然广泛应用于对各类数据的分析和结论中。那么,我们是否能够识别出比前文所述更为复杂的关系呢?这里引入了一个新系数 ξ(读作“克斯爱”)。
在深入讨论之前,值得一提的是,2022年有一篇论文《线性与单调性关联的误区》发表,该论文讨论了在不同类型数据中,哪种相关性度量方法更为合适。
我之前提到,皮尔逊相关系数 r 适合用于线性关系的度量,而斯皮尔曼等级相关系数 ρ 和肯德尔等级相关系数 τ 更适合用于单调性关系的分析。虽然这一观点在数据科学界广为接受并被广泛实践,但该论文却提出,这种看法并非绝对,某些情况下,情况可能正好相反。
公式
在正式介绍公式之前,有必要先做一些基本的准备工作。我们之前提到,相关性是用来衡量两个变量之间关系的一种方法。例如,我们正在评估变量X和Y之间的相关性。如果存在线性关系,那么这种关系可以被认为是双向的,也就是说,X与Y之间的相关度总是与Y与X之间的相关度相同。但是,采用我们的新方法,我们将不再仅仅测量X和Y之间的线性关系,而是要测量Y作为X的函数的相关程度。理解这种传统相关性分析中的微妙但重要的差异,将有助于我们更好地理解公式。因为按照这种新方法,ξ(X,Y) 并不一定等于 ξ(Y,X),这与传统的相关性测量不同。
延续之前的思路,假设我们想要继续评估Y相对于X的函数关系。每个数据点实际上是X和Y组成的有序对。首先,我们需要将这些数据点按照X的值从小到大排序,即形成(X?,Y?), (X?,Y?), …, (X?,Y?)的序列,确保X? ≤ X? ≤ … ≤ X?。换句话说,我们需要根据X的值对数据进行排序。排序完成后,我们可以定义一系列变量r?, r?, …, r?,其中r?代表Y?在排序后列表中的排名。一旦确定了这些排名,我们就可以进行计算了。
根据您使用的数据类型,使用两个公式。如果您的数据不可能(或极不可能)存在联系:

如果允许:
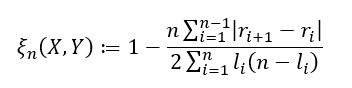
在这里,( l_i ) 表示的是 ( Y_j ) 大于或等于 ( Y_i ) 的 j 的个数。当数据中允许有并列情况时,我们需要注意一个重要的细节。除了应用第二个公式外,为了尽可能得到更准确的估计,我们需要以一种随机的方式对并列的数据点进行排序,确保在排名时一个值高于或低于另一个值,这样做是为了确保 ( (r_{i+1} - r_i) ) 的值不会为零。简单来说,( l_i ) 就是表示 ( Y_i ) 在所有观测值中实际大于或等于的数量。
为了避免过于深入理论,这里简要提一下,这种新相关性方法有着坚实的渐近理论基础,这使得我们可以在不对数据背后的分布做任何假设的情况下,轻松地进行假设检验。这是因为该方法基于数据的排序而不是具体数值,因此它属于非参数统计范畴。如果 X 和 Y 确实是独立的,并且 Y 是一个连续变量,那么

这意味着,如果您有足够大的样本量,那么该相关统计量大约遵循正态分布。如果您想测试正在测试的两个变量之间的独立程度,这会很有用。
代码
随着这一新方法的推出,相应的 R 语言包 XICOR 也发布了,它内置了一些实用的函数,比如 xicor(),这个函数能够方便地计算统计量 ξ,只要提供了 X 和 Y 的向量或矩阵,以及诸如假设检验的 p 值等附加信息。
和我之前所有的文章一样,我会提供 R、Python 和 Julia 的原始函数代码,你可以直接复制并保留它们以备后用。在这种情况下,X 和 Y 应该是向量或数组的形式。对于 Python 和 Julia,你可能需要分别安装 NumPy 和 Random 这两个库。
- R
## R Function ##
xicor <- function(X, Y, ties = TRUE){
n <- length(X)
r <- rank(Y[order(X)], ties.method = "random")
set.seed(42)
if(ties){
l <- rank(Y[order(X)], ties.method = "max")
return( 1 - n*sum( abs(r[-1] - r[-n]) ) / (2*sum(l*(n - l))) )
} else {
return( 1 - 3 * sum( abs(r[-1] - r[-n]) ) / (n^2 - 1) )
}
}
- Python
## Python Function ##
from numpy import array, random, arange
def xicor(X, Y, ties=True):
random.seed(42)
n = len(X)
order = array([i[0] for i in sorted(enumerate(X), key=lambda x: x[1])])
if ties:
l = array([sum(y >= Y[order]) for y in Y[order]])
r = l.copy()
for j in range(n):
if sum([r[j] == r[i] for i in range(n)]) > 1:
tie_index = array([r[j] == r[i] for i in range(n)])
r[tie_index] = random.choice(r[tie_index] - arange(0, sum([r[j] == r[i] for i in range(n)])), sum(tie_index), replace=False)
return 1 - n*sum( abs(r[1:] - r[:n-1]) ) / (2*sum(l*(n - l)))
else:
r = array([sum(y >= Y[order]) for y in Y[order]])
return 1 - 3 * sum( abs(r[1:] - r[:n-1]) ) / (n**2 - 1)
- Julia
## Julia Function ##
import Random
function xicor(X::AbstractVector, Y::AbstractVector, ties::Bool=true)
Random.seed!(42)
n = length(X)
if ties
l = [sum(y .>= Y[sortperm(X)]) for y ∈ Y[sortperm(X)]]
r = copy(l)
for j ∈ 1:n
if sum([r[j] == r[i] for i ∈ 1:n]) > 1
tie_index = [r[j] == r[i] for i ∈ 1:n]
r[tie_index] = Random.shuffle(r[tie_index] .- (0:sum([r[j] == r[i] for i ∈ 1:n])-1))
end
end
return 1 - n*sum( abs.(r[2:end] - r[1:n-1]) ) / (2*sum(l.*(n .- l)))
else
r = [sum(y .>= Y[sortperm(X)]) for y ∈ Y[sortperm(X)]]
return 1 - 3 * sum( abs.(r[2:end] - r[1:end-1]) ) / (n^2 - 1)
end
end
示例
为了首先了解使用这个新公式可能带来的好处,让我们比较几个模拟示例的计算相关值,这些示例突出了每种相关方法之间的主要差异。

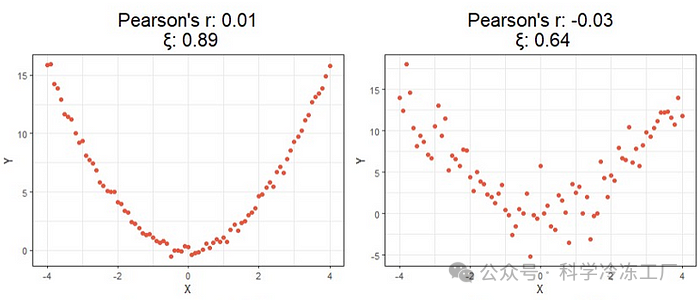
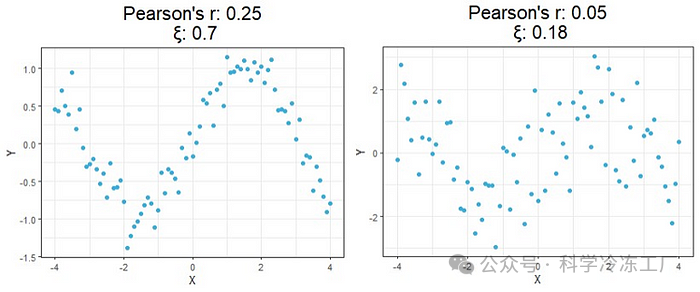
首先,我们可以观察到,使用这种新方法计算的相关性不再指示关系的走向,因为相关值不会是负数。然而,与预期相符,当两个变量间的关系越强,这个相关值越接近1;关系越弱,相关值越接近0,这与传统的相关性度量方法相似。
进一步观察图表的下部,我们会发现这种新方法的有趣之处。从底部的四个图表中可以明显看出,与常规计算方法相比,这种新方法在识别显著关系方面要有效得多。这些案例正是推动这项研究并导致新公式诞生的主要原因。例如,第二个案例中,皮尔逊相关系数 r 错误地得出 X 和 Y 之间没有显著关系,尽管实际上存在一个抛物线形状的关系;第三个案例中,该方法错误地认为存在轻微的正相关,但实际上关系并没有显示出上升趋势。
到目前为止,我们仅分析了模拟数据。现在,让我们通过一个真实世界的例子,来观察使用这种新相关性分析方法的一些可视化结果。假设我们的目标是衡量大脑信号与时间之间独立性的程度。
接下来的数据是利用功能性磁共振成像(fMRI)技术记录的大脑活动,以血氧水平依赖(BOLD)信号的形式呈现,这些数据可通过广受欢迎的 R 语言包 astsa 获取。为了提供更丰富的背景信息,该数据集包含了在大脑皮层、丘脑和 cerebellum(小脑)的八个不同区域,对五位不同受试者进行观测得到的平均反应。每位受试者都接受了为期 32 秒的手部周期性刷触刺激,随后是 32 秒的休息,形成了一个 64 秒的信号周期。数据以每 2 秒一次的频率记录,总共记录了 256 秒,即 128 个数据点。
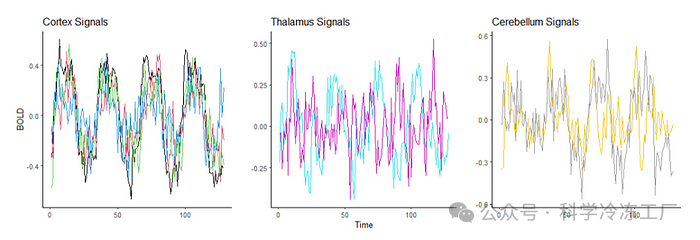
假设我们想要确定大脑这三个区域中哪一个与时间的关联性最强,也就是说,在进行指定刺激时哪一个区域的活动最为活跃。从上面的图表中可以观察到,大脑皮层的信号噪声最小,而丘脑的某个信号噪声最大。不过,为了更精确地评估,我们将利用新开发的相关性统计方法来进行量化分析。下面的表格列出了使用传统的皮尔逊相关系数 ( r ) 和新提出相关系数 ( ξ ) 计算的八个不同测量点的相关性数值。
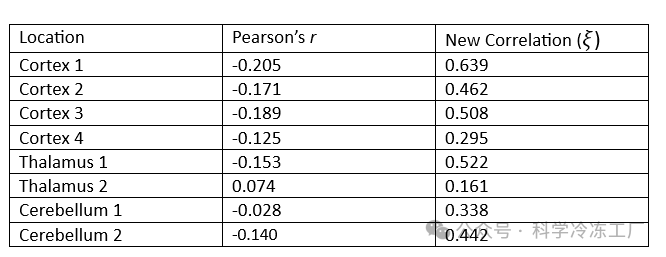
上表显示,传统相关性分析方法一致地将这些关系判定为负值或接近零,暗示着这些大脑活动与时间之间几乎没有或不存在明显的关系,即使有关系,也呈现出下降的趋势。然而,实际情况并非如此,因为我们可以看到,某些波长与时间之间存在明显的强相关性,而且它们整体上似乎并不遵循特定的趋势。
更重要的是,新相关性分析方法更有效地识别出哪个脑区的信号最为清晰。分析结果表明,在进行刺激的时段,皮层的某些区域使用最为频繁,因为这些区域的相关性数值平均最高。此外,丘脑的某些部分似乎也参与了响应,而这一结果在使用传统分析方法时并不容易被察觉。
总结
我们完全可以继续深入分析,比如运用先前提及的渐近理论,执行一个正式的独立性假设检验。但本报告的宗旨是向您简单介绍这一新的度量方法,并展示这些计算的简便性,以及如何应用这些结果。如果您对进一步了解这种方法的优势与局限感兴趣,我建议您查阅文末参考文献中介绍该方法的正式出版物。
尽管这一新方法并不完美,但它的提出旨在解决当前普遍采用方法中的一些显著问题。
Reference
[1]Source: https://towardsdatascience.com/a-new-coefficient-of-correlation-64ae4f260310