Bert类模型也具备指令遵循能力吗?
Bert类模型也具备指令遵循能力吗?

BERT模型,依托Transformer架构及其大规模预训练,为自然语言处理领域带来了深远的影响。BERT模型架构包含多层双向Transformer编码器,通过这种结构,BERT及其家族成员,如RoBERTa、ELECTRA、DeBERTa和XLM-R,能够深入学习并理解语言的上下文,尤其在自然语言理解任务上表现卓越。
然而,关于BERT家族在文本生成方面的潜能,研究还相对较少。虽然早期理论研究显示BERT家族能生成连贯且高质量的文本内容,主要应用还是集中在提取上下文特征上。近期,一些研究开始探索使用BERT进行非自回归文本生成,并在性能上取得了积极的反馈。这些尝试仍遵循传统的预训练和任务特定微调范式。
今天分享的这篇研究进一步探索了BERT家族作为多任务指令跟随者的可能性。这是一个在自回归语言模型中已被广泛探索的领域,但对于BERT家族来说却是新的领域。

论文:Are Bert Family Good Instruction Followers? A Study On Their Potentia And Limitations. 链接: https://openreview.net/pdf?id=x8VNtpCu1I
概要
通过带注释示例和人类偏好反馈进行指令调整,能够使LLMs的输出在各种任务上更好地符合人类的期望。最新研究探索了成功指令遵循技术的关键因素,包括注释质量、数据格式和模型扩展。预计未来将有更多强大的对齐方法涌现,服务于更广泛的模型变体。
为了扩大对齐技术的应用范围,最新的一篇研究深入研究了BERT家族作为指令跟随者的潜力与局限性,这是首次尝试在BERT家族上构建指令跟随模型。研究动机来自现有的观察:1) BERT家族也可以是零样本学习者。进一步赋予它们理解指令的能力将扩大它们的使用场景;2) 它们的掩码语言模型目标可以支持开放式长文本生成,同时实现比流行的自回归方式更快的解码速度;3) 复杂的现实世界应用通常涉及生成型LLMs和专家模型的合作,而BERT家族在大型生成模型兴起之前已推动了无数任务的发展,并仍保持各种下游任务的记录。
该研究还探讨了使BERT家族与当前流行的编解码器和仅解码器模型竞争的关键因素,并提供了进一步提升性能的可能方法和建议。
利用Bert进行语言生成
与传统的从左到右的单向语言模型不同,BERT家族使用的条件独立分解捕捉了训练中标记之间更复杂的依赖关系。这种复杂性在从头开始生成可靠文本时带来了挑战。本节描述了如何将BERT模型视为马尔可夫随机场语言模型,利用基于图的表示来管理标记之间的依赖关系,这影响了文本生成过程。
具体来说,作者介绍了一种视序列
为无向完全连接图
的方法,其中的潜在图团可以被分解为
个对数势能项之和:
这里的
表示从原始序列
创建的完全连接图,
表示序列
的长度,即随机变量的数量。通过这种表示,BERT家族可以在条件分布和伪对数似然中简化,这最大化了每个变量的概率,而不是整个图的联合概率:
一步训练与动态混合注意力
作者介绍了一种新的训练方法,该方法从之前的语言生成实践中汲取灵感,尤其是在编解码器基模型中,源序列
被输入到编码器以提取表示,而目标序列
则用于通过解码器学习内部关系。随后,每个解码器层中插入一个跨注意力模块,以聚合源表示和目标序列。
在BERT家族中,与传统的编解码器模型不同,BERT仅包含一个多层双向Transformer编码器。为了更好地匹配传统学习格式,首先构建一个额外的模型来扮演解码器的角色,然后引入混合注意力模块来替代原始的交叉注意力和自注意力模块。具体来说,给定训练对
,预训练的MLM包含
层,每层包括一个自注意力层和一个前馈层。可以获得每个编码器层
的源表示
:
对于目标序列
,我们随机选择部分标记被替换为
标记,并将这个损坏的序列输入到额外的MLM中。然后,这个模型在训练过程中尝试恢复这些掩码标记,并获取每个解码器层
的目标表示
:
其中
表示连接操作。混合注意力不引入额外参数,而是将源和目标隐藏状态的连接向量作为原始注意力机制中的键和值。因此,这个额外的MLM可以与MLM编码器完全共享参数。这样,我们只需要一个预训练的BERT模型即可节省模型参数,并加速训练过程。然而,混合注意力机制首先需要获取最后一层的源表示。我们必须在训练期间通过模型两次,导致训练效率降低。为此,我们引入动态混合注意力,允许模型在同一遍中获取源表示并学习预测掩码标记。这种机制采用每个源表示的相应前一层而不是最后一层:
在实践中,我们可以简单地将源和掩码的目标序列连接起来,然后输入到模型中进行训练。此外,如图1所示,我们阻止每个源标记在注意力模块中访问目标序列,以保持与推理过程的一致性,因为在推理中没有预先存在的目标序列。动态混合注意力与BERT家族的预训练任务更加匹配,使得共享参数的想法更加可靠。
训练与推理过程
本节详细描述了在生成任务中适应BERT家族的方法。首先,在给定的训练对
中,我们均匀地掩盖1到L(目标长度)的标记,采用CMLM(条件掩码语言模型)的方式,与BERT家族的原始固定掩膜不同。此外,我们还会随机掩盖源序列中的一小部分标记,以提高泛化性能,如在AMOM(Adaptive Masking Over Masking)中提到的。然后,训练目标是最大化条件MLM损失,如下所示:
其中
是掩码目标序列
中的掩码标记数量。请注意,模型不需要预测源序列
中的掩码标记。
在推理过程中,我们采用与CMLM相同的Mask-Predict算法,该算法在多次迭代中生成最终序列。具体来说,给定事先的总解码迭代
,我们从第一次解码迭代的完全掩码目标序列开始。在后续的
次迭代中,将会掩盖特定数量的低置信度标记并重新生成。每次迭代中掩码标记的数量可以计算为
,其中
表示当前迭代编号。模型根据预测概率选择下一次迭代中特定的掩码标记,具有最低概率的标记将被掩码,并在新的预测后更新其分数。此外,与传统的从左到右的自回归模型不同,在初始化完全掩码目标序列之前,我们应该获得目标长度。我们可以直接给出一个长度,在推理前。我们还引入了一个长度预测模块,跟随之前的非自回归模型,使用特殊的标记
来预测目标长度。
实验设置
微调详情 Backcone模型选择了XML-R,它是在大约100种语言上进行了预训练,采用了掩码语言建模目标,并且有两个大版本,XML-RXL和XML-RXXL,分别包含35亿和107亿个参数。由于计算资源的成本,我们在主要实验中选择了XML-RXL。
对于微调指令数据,为了充分利用XML-R预训练过程中的多语言知识,作者选择了一个多语言指令数据集xP3。xP3添加了30个新的多语言数据集,具有英语提示,并且作为P3的多语言版本。总体而言,xP3包含46种语言,以及与ROOTS相似的语言分布。在原始xP3论文中,作者使用了约8000万个样本进行训练,这远远超过了实际需求,增加了训练开销。因此,作者在实验中从原始训练语料库中抽样部分指令样本。
实验使用了预训练的XML-RXL,其中包含36层、2560隐藏大小和10240前馈滤波器大小。基于Fairseq库在8个NVIDIA A100-PCIE-40GB GPU卡上实现了所有实验。在训练过程中采用Adam作为优化算法。
Baseline 选择了mT0-3.7B和BLOOMZ-3B,因为它们具有可比较的模型参数,并且也是在指令数据集xP3上进行微调的。
任务和数据集 遵循之前的工作,评估了模型在三个不包含在微调指令数据中的保留任务上的任务泛化能力:会议决议、句子完成和自然语言推理(NLI)。
评估设置 在评估过程中,从PromptSource中选择了五个提示,并将它们用于上述每个数据集的所有语言拆分。最后,报告这些提示的平均性能。
主要发现
长度预测
对于几种非自回归模型,长度预测是在推断期间确定目标序列长度的额外任务。相比之下,自回归模型(例如,两个基准模型BLOOMZ和mT0)以从左到右的方式逐一生成文本,并且它们可以在遇到特殊的表示句子结束的标记(例如,[EOS])时动态完成生成。对于采用MaskPredict算法进行文本生成的Instruct-XMLRXL,长度预测是一个重要过程,直接影响最终生成结果的质量。
作者选择了XWinograd任务,设置提示为{下面句子中的“the”指的是{option1}。是True还是False?{sentence}},标签空间为{True,False}。
具体来说,采用长度预测模块为传统的语言生成任务(例如,机器翻译,因为它们的目标长度可以是灵活的)获取目标长度,并为确定的任务(例如,多项选择任务,因为它们的目标长度总是为一)采用固定长度。然而,对于这样的任务,其标签长度确定但不同的情况,例如具有标签空间{False,True}的任务,我们可以将标签空间转换为{Yes,No},这样标签长度就相同了,然后采用相应的固定长度,而不会泄漏有关目标标签的信息。
模型表现
下表呈现了Instruct-XMLR是否能够成功理解并完成未包含在微调过程中的任务。实验发现,Instruct-XMLR也展现出了强大的任务泛化能力。在仅微调基线模型1/25的令牌后,Instruct-XMLR在所有任务中都能显著优于具有可比大小的解码器模型BLOOMZ-3B。与更具竞争力的模型mT0-3.7B相比,Instruct-XMLR在XCOPA上取得了更好的表现,在XWinograd上表现可比,但在XNLI上表现稍逊一筹。
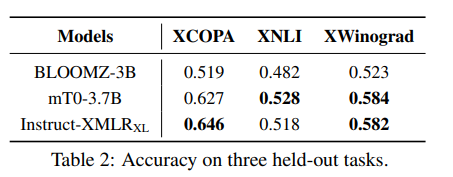
作者将这一失败归因于:
- XNLI是用于传统自然语言推理任务的多语言数据集,而具有编码器-解码器架构的mT0对这一任务更有益
- mT0-3.7B在预训练阶段(1万亿对比0.5万亿令牌)和指令调整阶段(15亿对比0.6亿令牌)都进行了更长时间的训练,这可以提升NLI任务的性能
Scaling law
由于XML-R有包含不同参数的不同版本,作者研究了随着模型尺寸增加性能的变化。此外,作者还关注了另一层次的规模化,即微调过程中的训练令牌数量。首先,XML-RBase和XML-RLarge,分别具有270M和550M的参数。下表呈现了结果。我们可以发现,随着模型参数的增加,存在明显的增长趋势。在使用相同数据微调后,Instruct-XMLRXL在所有任务上表现优于Instruct-XMLRBase和Instruct-XMLRLarge,表明模型大小在任务泛化中起着重要作用。

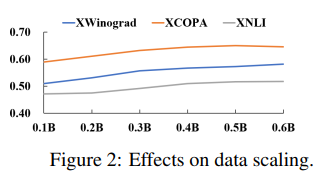
然后,让我们来看一看指导调整过程中训练令牌数量的规模效应。下图绘制了训练过程中性能的变化。随着训练的进行,所有任务的性能都在不断提高。总的来说,Instruct-XMLR也展示了正面的规模效应,这显示了未来潜在的改进空间。
总结
这篇论文深入探讨了BERT家族作为指令跟随者的潜力和局限性。作者发现,与当前流行的具有可比模型参数的模型架构的大型语言模型相比,微调的Instruct-XMLR在跨任务和语言上也表现良好。此外,作者也提出了一些局限性,例如长文本生成任务的性能下降以及在少量样本提示学习中的失败。其中一些问题可能是由于骨干模型的能力有限,因为迄今为止尚未有任何BERT家族模型能与解码器模型和编码器-解码器模型相媲美。