标题:逆光、眩光问题视觉模型怎么解决?一个感知卷积让检测/识别/跟踪/深度估计等任务,统统适用!
标题:逆光、眩光问题视觉模型怎么解决?一个感知卷积让检测/识别/跟踪/深度估计等任务,统统适用!


视觉传感器具有多功能性,能够捕捉广泛的视觉线索,如颜色、纹理、形状和深度等。这种多功能性,加上机器视觉相机相对便宜的可获得性,在自动驾驶车辆(AVs)中采用基于视觉的环境感知系统方面发挥了重要作用。 然而,基于视觉的感知系统在强光照射下,例如在阳光直射或夜间对面车辆的前大灯照射下,或者仅仅是雪或冰覆盖表面反射的光线时,都很容易受到影响;这些情况在驾驶过程中经常会遇到。 在本文中,作者研究了各种减少眩光的技术,包括所提出的针对自动驾驶车辆感知层所使用的计算机视觉(CV)任务的饱和像素感知减少眩光技术以提升性能。 作者基于感知层所使用的CV算法的各种性能指标评估这些减少眩光的方法。具体来说,作者考虑的是对自动驾驶至关重要的目标检测、目标识别、目标跟踪、深度估计和车道线检测。实验发现验证了所提出眩光减少方法的有效性,它展示了在多种感知任务上的性能提升,并对不同 Level 的眩光具有显著的抗干扰能力。
I Introduction
一个准确且鲁棒的环境感知系统对于智能交通的发展至关重要,尤其是在自动驾驶车辆的情况下。满足J3016国际标准中规定的第5级自主性的要求,意味着需要具备在所谓的操作设计域之外进行操作的能力。不是在精心管理(通常是城市)的环境中,拥有大量专用基础设施。自动驾驶车辆(AVs)应该能够在不可控环境中运行,包括具有挑战性的天气、眩光、霾和雾造成的照明变化、标识不良的道路以及不可预测的道路使用者。
自动驾驶软件堆栈中的感知层负责通过各种计算机视觉(CV)任务,如目标检测与识别、深度估计、车道线检测等,及时感知车辆环境中的变化。近年来,自动驾驶车辆中的基于视觉的感知层已经获得了极大的关注。
几家汽车公司,如特斯拉、宝马和 Mobileye,已经创建了它们自己的基于视觉的感知系统。这一趋势可以归因于几个因素,包括道路标记和标志以人为中心,机器视觉摄像头的成本降低,以及在视觉相关任务中使用的深度神经网络的快速发展。然而,在驾驶过程中经常遇到的强烈眩光现象,如在隧道中行驶、刺眼的阳光、迎面而来的车头灯、雪或雾,以及空气中的水滴反射的光,都会显著降低基于视觉的检测系统的性能。
通常由于成本以及更重要的是尺寸限制,部署在自动驾驶车辆上的机器视觉相机使用的是较为简单的镜头系统,这些系统缺少防炫光涂层,因此产生的炫光要比高端无反光镜相机强得多。此外,目前最先进的基于视觉的自动驾驶车辆感知算法使用深度神经网络,并在正常条件下捕获的图像数据上进行预训练,因此在遇到具有显著炫光的图像时,其性能会受到影响。由于光线在镜头表面散射(反射或折射)而产生的炫光,是任何相机系统的主要限制因素,因为它可以显著降低捕获图像的动态范围,或者当图像的某部分由于炫光而过曝时,它可能造成重要细节和特征的丢失。它还能产生像晕、闪光和重影这样的伪影,这些伪影可能会扭曲或遮挡图像,并可能导致颜色失真,从而使得图像中的颜色不准确或不真实。
在一个理想的情况下,一个聚焦的点光源应该只照亮一个像素。然而,在现实中,由于光线在相机镜头和机身内部的散射和反射,光线也会到达传感器上的其他像素。为了减少到达传感器的额外光线量,已经提出了几种消光技术。目前用于减少光晕的大部分方法可以分为三个主要类别:增强光学器件、计算或后处理技术,以及利用 Mask Mask 的技术。这些不同类别的所有技术要么涉及昂贵的硬件修改,要么是针对特定成像系统设计的复杂计算模型。即使是更先进的基于深度学习的方法,通常也是在一个单一光源捕获的数据集上进行训练,并且需要大量数据集进行细致调整以适应另一个成像系统。
这种对单一摄像机模型的特定性限制了它们在自动驾驶车辆(AV)中的应用,因为高级成像组件,例如长焦镜头,专为高速和远距离目标检测而设计,在与近距离反光作斗争时遇到困难。这一限制的出现是因为长焦镜头具有更窄的视野,并优化于远距离对焦,这降低了对抗来自附近光源的反光的有效性。相比之下,那些具有高分辨率和光敏感技术的摄像机,在面对远距离反光时遇到困难,因为它们强调在城区设置中的详细记录。这些摄像机针对中近程场景的清晰度和细节进行了优化。因此,它们在焦点范围或动态范围上有限,无法有效处理来自远距离光源的反光,这种反光可能更为扩散且不太明显,导致在更远距离时能见度降低和反光管理的减弱。
在本文中,作者介绍了一种基于联合眩光扩散函数(GSF)的新颖眩光缓解方法。该方法采用点光源的高动态范围图像,并在联合GSF估计过程中细化了一个径向对称函数。这种细化专门设计用来吸收新成像系统的眩光特性,同时保留对先前使用相机的有效性。该技术的重点是适应性和鲁棒性,使其适合于自动驾驶车辆遇到的多种多样和具有挑战性的条件。所提出的方法旨在通过使用预先估计的GSF对观察到的图像进行反卷积,恢复一个无眩光的图像。然而,基于反卷积的方法需要了解眩光源的像素强度才能表现良好。在实践中,一些像素可能会饱和,例如夜间车辆的 Head 灯光,这会在图像中引入非线性和信息丢失,违反了线性反卷积过程的基本假设,因此限制了在饱和情况下应用于眩光缓解的范围。这个问题通过使用暗通道先验[6]准确估计输入图像中的饱和区域来解决。通过用估计的辐射度替换饱和区域,从而恢复线性的假设。在此之后,执行反卷积以有效恢复退化的输入。
所提出方法的有效性在光源位于相机视场(FoV)内时显著提升。该方法基于这样一个假设:可以通过更简单的解决方案,例如使用相机遮光罩,来适当管理FoV外的光源,从而限制图像质量的下降。在[5]中简要介绍的技术没有联合GSF估计,这限制了其应用于人类感知,而这项任务与涉及多种相机的自动驾驶车辆(AVs)感知完全不同。本文的主要贡献概括如下:
本文提出了一种利用联合GSF估计的眩光减少方法,以克服基于反卷积的眩光减少技术中的两个普遍问题:饱和度处理和GSF特异性。
本文展示了迄今为止在眩光减少研究背景下研究的感知任务的最广泛范围。
它对各种减少眩光技术进行了彻底评估,直接基于自动驾驶车辆感知算法的性能指标。
II Related Work
眩光在高动态范围成像中是一个公认的技术挑战。先前关于减轻眩光的研究可以广泛地分为三个主要类别:光学技术的进步、计算或后期处理技术,以及涉及遮挡 Mask 的技术。以下段落将对每一组技术进行回顾。
为了解决光学中的反光问题,使用了高质量的防反光镜头涂层以显著降低反射率。然而,像塑料内部和涂漆表面这样的相机内部组件仍然可能导致反光。在[7]中,提出了一种新颖的方法,使用充满液体的电荷耦合器件(CCD)以最小化杂散光。这种被称为模拟眼设计(SED)的相机,具有一个玻璃镜头,其液体层延伸至CCD,减少了反射界面。另一种在[8]中的方法,是在相机镜头前使用一个电子控制的光学快门阵列。通过选择性地激活这个阵列的元素,可以有效阻挡反光源。尽管这些方法有效,但它们涉及对相机的修改,可能并非普遍适用。虽然这些方法有效,但它们需要对相机或光学器件进行某些修改,因此在不进行适应性调整的情况下可能无法直接应用。
在先前的研究中,反卷积通常被用作一种后期处理技术来消除眩光。Reinhard等人于[9]提出的一种方法是基于盲目反卷积的方法,通过拟合一个径向对称多项式到明亮像素周围光线的减少来估计眩光扩散函数(GSF)。在[10]中,眩光扩散函数(GSF)由一个三角函数伴随一个低值、低频的组分来表征,该组分代表不希望的眩光。该过程涉及通过用建模的GSF对受眩光的图像进行反卷积来去除图像中的眩光。然而,值得注意的是,反卷积方法只有在场景中最亮的物体,即对眩光贡献最大的物体,能够在没有饱和的情况下被捕捉到时才能有效。不幸的是,即使在许多情况下,即使是高动态范围(HDR)相机也可能难以捕捉到场景的完整动态范围,这限制了基于反卷积的眩光减少方法的性能。
在[11]中,Nayar等人提出了一种消除眩光的替代方法。他们的方法包括将场景的辐射分成两个分量:直接辐射,由光源对一点的直接照射产生,以及全局辐射,由场景中其他点对一点的照射产生。这种分离可以通过结构化照明或遮挡 Mask 来实现。在[10]中提出了这种方法另一种变体,其中通过在相机和场景之间插入高频遮挡 Mask 来限制图像中的全局光分量。尽管眩光在2D中表现为一种附加的低频偏置,但Raskar等人[12]表明,眩光中有很大一部分是4D光线空间中的高频噪声。为了去除这部分高频眩光,在靠近相机传感器的位置引入了一个高频 Mask ,它像一个筛子,在光线空间中分离虚假光线。同样,这些方法需要一些额外的硬件或对相机设计的修改。
类似于炫光,大气雾霾是通过向场景的整体辐射中引入反射光成分来降低图像质量的现象。近年来,基于深度学习,已经提出了几种非常有效的去雾方法。鉴于去雾的目标是减少不希望有的附加光成分,这些技术也可能适用于解决炫光减少的问题。例如,在中,提出了一种基于卷积神经网络(CNN)的端到端去雾系统,称为DehazeNet。DehazeNet接收一个有雾图像作为输入,并为输入图像输出介质透射图。然后,透射图通过大气散射模型用于恢复无雾图像。在[14]中,杨等人提出了近端去雾网(proximal dehaze-net),它将雾模型、暗通道和透射先验作为优化问题中使用的能量项结合起来。
在中提出了一种密集连接的金字塔去雾网络(DCPDN)。DCPDN共同学习传输图、大气光和去雾。传统的基于固定 Patch 大小的去雾算法(例如暗通道先验)会导致过饱和和色彩失真等问题。为了解决这些问题,提出了一种名为Patch Map Selection network(PMS-Net)的CNN模型,用于对每个像素自适应和自动选择 Patch 大小。
模糊是另一种图像退化形式,它与眩光一样,被建模为潜在的无模糊图像与模糊核(也称为点扩散函数(PSF))的卷积。图像去模糊已经通过几种不同的方法在文献中成功地得到了解决。大多数为图像去模糊设计的盲解卷积和非盲解卷积方法没有考虑到输入图像中的饱和度,这使得它们在解决眩光减少问题时效果不佳。
提出的方法采用了简单的去卷积方法,作者采用了傅里叶域的方法。作者使用已知GSF的维纳去卷积来去除眩光,因为它对于信噪比低的频率具有鲁棒性,并将其作为后处理步骤应用。这种方法解决了先前基于去卷积的减光方法观察到的重大局限性,即图像中存在饱和区域的问题。为了克服这一挑战,该方法通过利用暗通道先验估计饱和区域的真正辐射度,从而实现更准确的减光。
III Testing framework
作者的测试框架概述如图1所示。用于数据采集的相机是IDS UI-3860CP-C-HQ计算机视觉相机,它配备了索尼IMX290 1/2.8" CMOS传感器,分辨率为1936x1096像素,像素大小为2.9
m。作者使用了一种类似于在行车记录仪中使用的广角镜头,具体为“焦距为3.5 mm,有效视场为85
x 62.9"的广角Navitar MVL4WA镜头”。本文中的测试数据集包括了在[23]中描述并在1处可获得的隧道场景。此外,评估还扩展到了由真实自动驾驶车辆捕获的数据集,具体描述见实验结果部分。测试 Pipeline 的输入是线性彩色相机帧。在进一步处理之前,原始帧使用DDFAPD [24]进行去马赛克处理,然后进行白平衡调整。白平衡是通过调整RGB值来确保色卡中的白块在所有颜色通道上具有相等的强度。最终生成的16位图像是通过从捕获的曝光堆栈中选择适当的曝光来生成的。
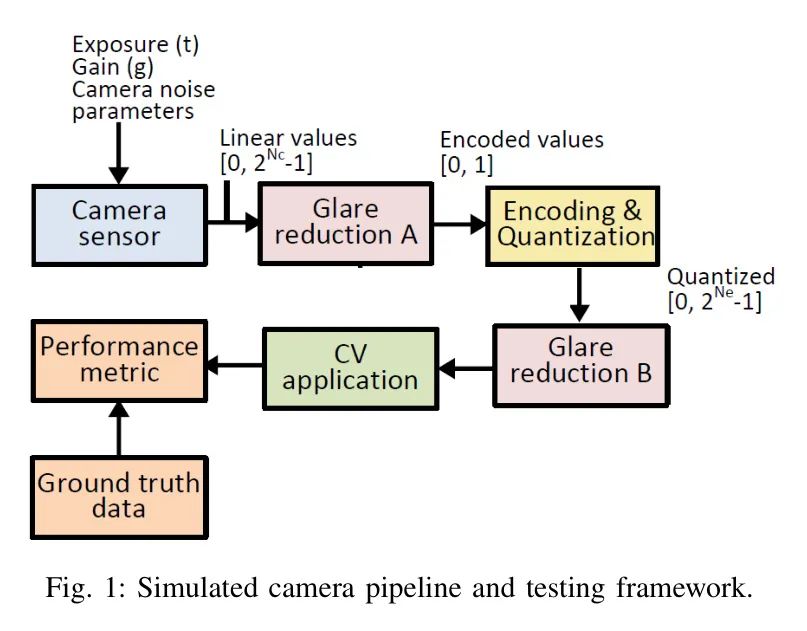
眩光减少在 Pipeline 的两个阶段进行。需要在物理光量(线性值)上操作的方法在编码之前使用传输函数(TF)减少眩光。这在上图中的_Glare reduction A_块中显示。然而,一些减少眩光的方法需要在对(伽马)编码值进行操作。这在上图中的_Glare reduction B_块中显示。作者使用两种TF(_编码与量化_块)进行测试:对数和伽马,以及线性输入。测试对数TF是因为它在作者之前的测试中表现最好之一。测试伽马TF是因为它是计算机视觉中编码图像的主导方法。
图1:模拟相机流水线与测试框架。
最终,经过减少光晕影响的TF编码图像被传递给计算机视觉算法,并将结果与真实解进行比较。对于每种计算机视觉算法,真实解是通过简单地测试在统一光照条件下同一场景的所有图像来获得的。所有真实解图像都进行了伽马编码,以匹配通常由最先进的计算机视觉方法使用的训练数据的编码。最后,用于评估每种减少光晕方法的性能指标在第VII部分中有详细描述。## 第四部分 面向不同相机系统的联合gsf估计。
离线校准步骤包括从多个相机形成一个综合数据集,涵盖各种反光场景。作者考虑以下相机镜头组合进行联合GSF估计:GoPro HERO5,佳能EOS 2000D / Rebel T7数码单反相机,全画幅无反相机(索尼
7R1),以及IDS UI-3140CP-M-GL搭配以下镜头组合:55毫米定焦镜头(索尼SEL55F18Z),佳能EF 50mm f/1.8 STM镜头,以及焦距为3.5毫米的广角Navitar MVL4WA镜头,以及25毫米C口镜头(富士HF25HA-1B)。
作者使用一个部分被纸板覆盖的小型光源来捕捉高动态范围(HDR)图像。纸板覆盖了光源的所有部分,只留下中心一个直径为2毫米的圆形孔径。该装置在图2中有所展示。让作者将光源的强度表示为
,孔径的直径表示为
,每张图像的曝光时间表示为
,其中
根据捕捉的图像数量而变化。每张图像中捕捉到的总光量可以表示为这些变量的函数。

光通过孔径的强度表达如下:
在公式中,
代表圆形孔径的面积。对于在不同曝光时间下捕获的每张图像,总捕获的光线
可以表示为。
因此,整个捕获过程是指每张图像捕捉不同亮度 Level 的情况,例如,较短的曝光时间能够捕捉到最亮区域的信息,防止这些区域过曝,而较长的曝光时间则能在较暗区域限制噪声,构成了多种反光场景的广泛范围。这可以表示为每个曝光时间对应的单独捕获的光强度的一系列:
其中
是使用不同曝光时间拍摄图像的数量。
这些图像随后使用_pfstools_2软件进行合并。为确保最佳的图像质量,曝光时间会相应调整,以防止在最短曝光时间捕获的图像中出现任何像素饱和。### 统一参数GSF优化
眩光是 一种物理现象,有必要用线性辐射值来表示它。在许多相机中,可以通过使用GSF的空间不变卷积来近似眩光。投射到传感器上的辐射,记作
,可以近似如下:
在文中,
表示梯度空间模糊(GSF),而
表示投射到坐标
的像素上的入射辐射照度。在相机中建模眩光是一个挑战,因为需要一个 Kernel
,其大小是图像的两倍,才能准确模拟眩光。这是因为图像一个角落的明亮像素可以影响对角线另一端的像素。然而,直接使用如此大的 Kernel 进行卷积在计算上是昂贵的。因此,在实际操作中,卷积通常在傅里叶域中执行:
在这里,
、
和
分别是
、
和
的傅里叶变换。为了确保对炫光精确的模拟,作者假设原始辐射图
首先被扩展到原来的两倍分辨率,然后用零进行填充。这有两个目的:(a) 它确保图像尺寸与卷积核的大小一致,该卷积核的大小是图像大小的两倍;(b) 它有助于避免由于傅里叶变换的圆对称性导致的模拟错误。如果不进行零填充,图像边缘附近的一个明亮光源可能会导致对面边缘产生强烈的炫光。通过用零填充
,作者可以模拟相机上精心设计的镜头遮光罩的效果,该遮光罩可以阻挡所有无法聚焦到传感器上的光线。
图像中的眩光是由光线在相机镜头及其机身上的散射和反射产生的。因此,在眩光扩散函数估计中,需要准确地建模成像系统(镜头和相机机身组合)的散射和反射模式。由于这些模式在不同的镜头-相机组合中有所不同,作者采用以下联合GSF估计策略:
由于可以获得无眩光的真实图像
(除了圆形光源外全黑),因此可以通过反卷积获得GSF。然而,由于这种方法不可靠且对噪声敏感,因此采用了另一种方法来估计GSF。该方法涉及优化一个径向对称函数的参数:
图2:用于眩光估计的高动态范围图像捕捉实验设置。
其中
是狄拉克 delta 函数,
,...,
是模型的参数,
是以传感器像素为单位的距离(
)。
包含狄拉克 delta 函数
,表示由参数
调制的瞬间亮点或眩光。
模拟了眩光从中心点向外扩散的情况。它是一个指数衰减函数,其中
调整强度,
影响衰减速率,
调整与距离
相关的非线性响应。这些参数是通过最小化以下目标函数来估计的:
在这里,
表示从第
个相机捕获的HDR图像。
代表将 GT 辐射图与参数化GSF进行卷积的结果。参数
是一个权重因子,而
是正则化系数。
是正则化项,作者选择它为参数的L2范数,以防止过度拟合某一类型的相机。
作者采用非线性优化算法来最小化上述目标函数。由参数
控制的正则化项,在多种相机类型之间平衡了模型的灵活性和泛化能力。
的值较高可以确保模型不会过度适应某一特定相机的眩光特性,从而保持其适用于更广泛的系统。
优化后,GSF模型使用来自多个相机的一组独立图像进行验证。这一步骤对于评估模型的性能和泛化能力至关重要。根据验证结果,作者调整
和
以微调模型,确保在多种相机下实现最佳性能。
V Saturated pixel aware glare reduction
场景中的明亮光线有时即使是通过HDR相机也难以捕捉,例如夜晚车辆的 headlights 或者是隧道尽头照耀的明亮阳光,这导致图像中存在一些饱和区域
。这样的图像
可以被表示为饱和区域
和非饱和区域
的组合。
饱和区域是图像中最大炫光的主要原因,而在饱和区域内没有真实强度的情况下进行反卷积,在显著减少炫光方面是失败的。在提出的方法中,如算法1所述,利用暗通道先验和联合GSF来估计饱和区域的真正辐射度,随后使用已知的GSF进行反卷积。
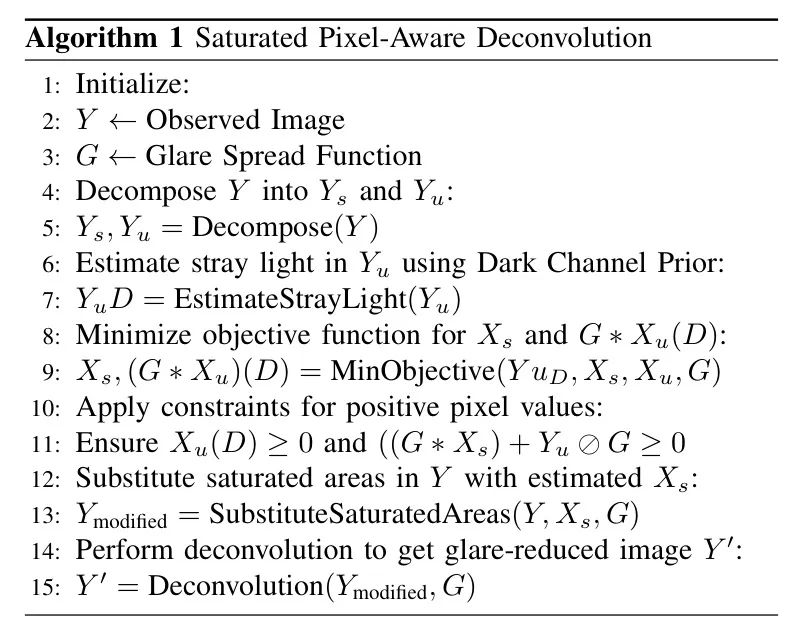
算法1 饱和像素感知的反卷积
在典型的图像形成模型中:图像中的眩光被表示为GSF
与潜在图像
的卷积,如下方程所示:
在公式中,
是观察到的图像,
是眩光扩散函数,
是潜在图像,
是加性噪声。将方程式9写成如方程式8所示,分别表示饱和区域和非饱和区域,作者得到:
为了估计式(8)中饱和区域的真实辐射度,采用了“暗通道先验”知识。根据暗通道先验的关键观察,无光晕图像
中存在一些像素
(其中
),在至少一个颜色通道中具有非常低的强度值,接近零。因此,在图像
的光晕版本中,这些像素的强度值可以被认为是该像素处散光的近似量。然而,暗区域中噪声的存在限制了这种方法的效果。为了减少噪声的影响,作者在寻找最小值之前对图像应用高斯模糊。基于上述假设,作者可以用暗像素
来写出式(10):
作者最小化以下目标函数,同时遵循(13)、(14)和(15)中给出的约束,以估计
和
。
(13)式中的约束类似于主要的数据项,但依赖于所有未饱和的像素,其目的是防止像素值出现负数。在此处,
表示未饱和像素,而
是通过与炫光扩散函数
进行去卷积操作得到的
。
其中(14)确保了对图像中暗像素的所有估计保持为正值,从而防止在较暗区域出现非物理性数值。
在式(15)中,应用于估计的饱和像素(
)和实际未饱和像素(
)的组合图像上。"
" 表示去卷积操作,这确保了在每次迭代中,去卷积的结果始终保持严格正值。
鉴于GSF扩展到图像大小的两倍,在空间域进行反卷积变得不切实际。因此,作者选择了傅里叶域的方法。为了去除光晕,使用了与已知GSF结合的_维纳反卷积_。这种方法特别有效,因为它在处理低信噪比频率时具有鲁棒性。经过减光晕处理后的图像
最终是通过将观察图像
中的饱和区域替换为估计的辐射值
,然后使用已知的GSF进行维纳滤波得到的,表示为:
需要强调的是,成功恢复最终的图像
依赖于两个主要因素:在由炫光退化输入图像中,拥有充足的暗区域,这允许尽管存在噪声的情况下也能准确估计杂散光;以及所采用的炫光模型在测量 GSF
时的准确性。
VI Transfer functions for glare-induced luminance variations
眩光对场景的动态范围影响显著,常常导致图像中出现过曝或欠曝的区域。因此,编码的选择变得至关重要,因为不同的传递函数提供了独特的缓解这些挑战的方法。编码方法针对受眩光影响的亮度调整其响应,确保最佳的细节保留和动态范围处理,从而提高计算机视觉性能。
大多数相机传感器,包括CCD和CMOS,对光的响应是线性的,它们计数入射的光子,并以与辐射度量量(辐射照度)线性相关的值进行记录。虽然线性色彩值在感知上是非均匀的,且需要高比特深度来存储,但它们通常会被色调映射为经过伽马校正的表示形式,以产生视觉上吸引人的内容。然而,对于计算机视觉(CV)任务来说,尤其是在强光条件下,感知均匀性不如详细信息的捕获重要,因此需要转换函数:a) 在极端强光下能够编码大动态范围;b) 在所需比特深度方面是高效的。
Gamma encoding
伽马编码是一种非线性操作,它通过将传感器上的线性光强度值提升到一个小于1的指数来压缩这些值,通常这个指数的范围在
到
之间。这种编码使得编码后的值在感知上更加均匀,并且它部分考虑了相机噪声的非均匀方差。伽马编码可以通过以下方程式表示:
在.gamma编码中,
是输入像素值,
是经过gamma编码后的输出像素值,而gamma则是gamma值。Gamma编码中的幂次关系增强了较低亮度范围,这对于抵消强光导致的过度曝光和冲淡细节的倾向至关重要。
Lograthmic encoding
对数编码用于将图像中的像素值转换为更好地表示广泛的强度 Level 。这在需要捕获大动态范围的应用中特别有用,比如在场景中存在强光源时。作者定义作者的对数变换函数(TF)为:
其中
是用于表示线性数字信号
的比特数。编码值
在0到1之间,并且可以用所需数量的比特来表示。在公式(18)中,亮度的光谱高端得到了很好的压缩。这是非常重要的,因为强光往往会导致高亮度值,这些值可能会掩盖图像的微妙细节。
Linear encoding
由19式所表达的直接线性确保了原始亮度值的最小改变。在眩光影响不太明显的情况下,保持原始数据的完整性对于准确的图像分析是有益的。
其中
是输入像素值,
被转换为输出,
是增益因子,
是偏移量。
这些传递函数基于其独特的数学属性,为由眩光引起的各种挑战提供了定制化的解决方案,它们在自动驾驶车辆感知中有效应用,以处理在眩光存在时遇到的高动态范围场景,这是不可避免的。
VII AV perception algorithms
机器视觉在自动驾驶感知方面发挥着关键作用,它使车辆能够理解和解释其环境。本文涉及并包含的一些关键的机器视觉应用有:目标检测(OD)、目标识别(OR)、车道线检测(LD)、目标跟踪(OT)以及深度估计(DE)。由于这些感知算法固有地脆弱,因为它们主要是为可见光谱设计的,在面对强光时会遇到显著的性能下降。
Object detection:
作者使用了最先进的深度学习算法,Yolov5 [25]来检测场景中的各种目标,例如车辆、行人、交通标志和交通信号灯。作者的测试场景“隧道”包含了在道路及周围可能遇到的大量的目标,其中一些测试场景的图像展示在图8和图6中。在各种可能条件下,包括强烈眩光存在时,及时且精确地检测上述所有可能的道路目标,对于自动驾驶车辆做出明智决策和安全导航至关重要。然而,眩光减少了目标与背景之间的对比度,这对于目标检测是关键,同时也极大地增加了对眩光的敏感性。因此,为了评估眩光减少方法在目标检测中的性能,作者通过在无主要眩光源的均匀照明下捕获的数据集上应用相同的检测算法来生成GT,如图6所示;并将所有检测到的目标边界框(BB)坐标存储为GT。


平均交并比(MIoU)指标,如下所示,被选用于评估目标检测中炫光减少的效果,因为它在评估预测边界框与实际边界框之间精确度和召回率,以及测量预测与实际边界框的重叠准确性方面非常有效。
其中
是所有预测的
个边界框的并集,而
是所有
个参考边界框的并集。
Object Recognition:
物体识别在自动驾驶车辆中对于感知和理解周围环境起着至关重要的作用。一旦检测到物体,它们就需要被归类到特定的类别或类别中,例如行人、骑车人、汽车或交通标志。作者采用了最先进的Detic [26]物体识别方法来定量评估所选眩光减少方法在物体识别中的性能。与OD一样,用于测试识别的数据集是隧道场景,其中包含了在驾驶过程中可能遇到的各种物体。
除了分类,Detic [26] 还进行了分割,为每个像素分配相应的物体标签。这种对场景的细粒度理解使得车辆能够在区域和物体之间进行区分,从而实现更精确的决策制定,并允许在复杂的交通场景中进行更安全的导航和避障。与目标检测(OD)一样,评估遮挡去除(OR)的真实值是通过在相同场景的数据集上运行相同的算法生成的,不同之处在于没有主要的反光源,并且光照均匀。选择的评估指标是平均平均精度(MAP),它衡量排序检索结果的质量或目标检测和定位的准确性。MAP 是平均精度(AP)的扩展,它计算每个类别的平均精度,然后对所有类别取平均值:
在这里,
和
分别是第
个阈值下的精确度和召回率。
是数据集中总类别或分类的数量,AP_1, AP_2,..., 以及 AP_N 分别是每个类别的平均精度得分。
Object Tracking:
物体追踪帮助车辆理解周围物体的移动和行为。OT识别并监控环境中的物体,预测它们未来的位置,并了解它们如何与车辆互动。因此,它有助于车辆的整体态势感知。通过不断更新对周围环境的了解,车辆可以适应变化的道路条件、交通动态和意外的障碍物。物体追踪算法估计车辆当前的位置和运动状态,这包括确定车辆的位置、速度、加速度和方向。
在本工作中使用的追踪算法[27]是一种基于深度学习的方法,称为DeepSORT,它考虑了物体的当前状态和历史数据来预测其在接下来几秒钟内的移动情况。与其他感知任务一样,OT的真实数据是通过使用具有均匀照明且没有主要反光源的情景数据集生成的,所使用的评估指标为(多目标跟踪准确性)MOTA和(多目标跟踪精确度)MOTP。MOTA评估检测性能、遗漏和ID切换。追踪器的准确性MOTA是通过以下方式计算的:
在本文中,FN代表假阴性数量,FP代表假阳性数量,IDS代表在时间
的身份转换次数,而GT代表真实值。MOTA(多目标跟踪准确度)也可能是一个负值。MOTP(多目标跟踪精确度)的计算公式如下,
其中
是目标
与其分配的 GT 物体之间的边界框重叠程度,而
是 GT 与检测输出之间总共匹配的数量。
Lane detection:
车道线检测是自动驾驶车辆感知系统的重要组成部分。当自动驾驶车辆打算变道或汇入高速公路时,它能帮助车辆识别交通中的空隙,并判断何时变道是安全的。变道操作与目标检测系统协调,以避免与其他车辆发生碰撞。基于深度学习的水道检测算法在处理各种道路条件和适应不同环境方面具有优势。它们还可以学习可能难以手动设计的复杂特征。在这项工作中,作者采用了一种深度学习模型[28]来评估在各种眩光减少技术中车道线检测的有效性。回归模型性能的评价最好通过误差值来描述。为此,作者计算了常用的均方根误差指标(RMSE)[52]和[29]。以下方程式呈现了计算RMSE的公式。
其中 Predicted
表示以像素单位预测的车道线点坐标值,而 Actual
是同一点坐标的 GT 值。在实际应用中,Actual 和 Predicted 值作为二维向量给出,包含车道线上选定点的 x 和 y 坐标。因此,较小的 RMSE 意味着预测的车道线比具有较大 RMSE 的预测线更接近 GT 值。
Depth estimation:
深度估计提供了关于环境三维结构的基本信息。这些信息对于与周围环境进行安全有效的导航和交互至关重要。深度数据有助于路径规划和控制算法。它使车辆能够确定道路的地形,并针对地形做出适当的加速、减速和转向决策。理解道路及其周围环境的深度对于执行诸如并入高速公路、变道或穿越复杂交叉口等安全操作至关重要。
基于深度学习的单目深度估计方法旨在从单个输入图像预测场景中物体的深度或距离信息,在本研究中,作者采用了最先进的单目深度估计方法MIDAS [30]。类似于LD,作者使用了均方根误差(RMSE)来评估各种去眩光方法对深度估计性能的影响。RMSE是从GT图像估计的深度图和将去眩光技术应用于输入眩光图像后得到的最终图像的深度图中直接计算得出的。
VIII Experimental results
在本节中,作者展示了所提出的光晕减少方法在提高自动驾驶车辆感知任务性能方面的定量和定性评估。作者选择隧道场景进行评估,因为它展现了高动态范围并提供了一个包含多个光晕源的真实场景。所选择的 数据集提供了在均匀光照条件下同一场景的图像,这对于估计诸如深度估计和目标跟踪等感知任务的真实值至关重要。此外,该数据集通过不同的曝光捕获提供了足够的光晕变化,为光晕减少方法的稳健评估提供了充足的数据。
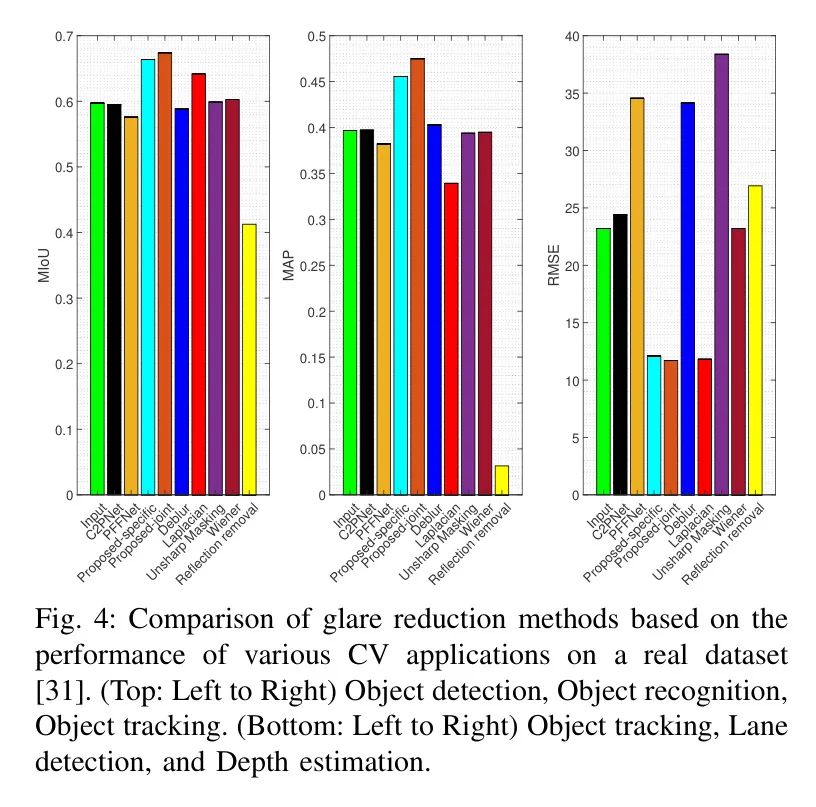
此外,作者将提出的方法在一个由自动驾驶汽车使用GoPro HERO5相机捕获的真实数据集[31]上的性能进行了比较。本文中的测试数据集由[31]中包含强光反射的图像子集组成,即所有夜间图像,已公开发布3。作者将提出的方法与适用于减少光晕的各种技术进行了比较。特别是,作者探索了针对减少眩光对自动驾驶车辆感知任务影响五个不同的技术类别。这些包括基于基本去卷积的方法,例如不考虑饱和像素的维纳滤波方法。此外,作者研究了图像去雾方法,特别是C2PNet[32]和PFFNet[33]。还考虑了图像增强技术,如非锐化 Mask 和局部拉普拉斯滤波。另外,作者还评估了反射去除[34]和图像去模糊[35]技术的有效性。
这些不同方法的选取是基于它们对眩光问题的适用性以及不同的计算复杂性。例如,与眩光类似,雾气也会将光的反射成分添加到不同的传感器位置。在雾气的情况下,光在大气中的悬浮颗粒或分子上发生散射,导致图像对比度降低、颜色失真以及细节丢失。当光在相机镜头或光学系统内部散射和反射时,就会产生眩光,导致同样不希望出现的伪影。
图像增强可以成为图像去卷积和图像去雾的简单且计算效率高的替代方法,以减轻炫光的不利影响并提高自动驾驶车辆感知模块的性能。
图像去模糊技术旨在纠正因模糊或其他降低图像清晰度的因素而受损的图像。这些方法在低到中等曝光水平下是有效的,但在强烈反光条件下表现不佳。在文献[35]中特别考虑了像素饱和度,因此被包括在作者的比较之中。反射去除方法针对的是由相机镜头或光学系统内部的反射引起的退化。在反光不是由于外部光源而是由于相机内部反射的情况下,反射去除尤为重要。
在图3、4和5中,作者展示了所提出联合GSFs估计技术在感知任务上的有效性。在图3中,对于第IV部分讨论的摄像机镜头组合,联合GSF进行了估计,所使用的数据集是用第III部分指定的摄像机和镜头捕获的。值得注意的是,如图3所示,尽管在GSF估计中涉及到了不同的摄像机-镜头组合,但基于作者联合GSF估计的方法表现出一致的性能。与图3中多个摄像机-镜头性能的均匀性不同,在图4中,联合GSF方法甚至对于在数据采集阶段使用的同一摄像机——GoPro HERO5,也稍微优于特定估计的GSF。这种差异可以归因于数据集之间的不同。在图3中使用的是在室内捕获的数据集,与图4中呈现的实际数据集相比,其深度变化不显著。
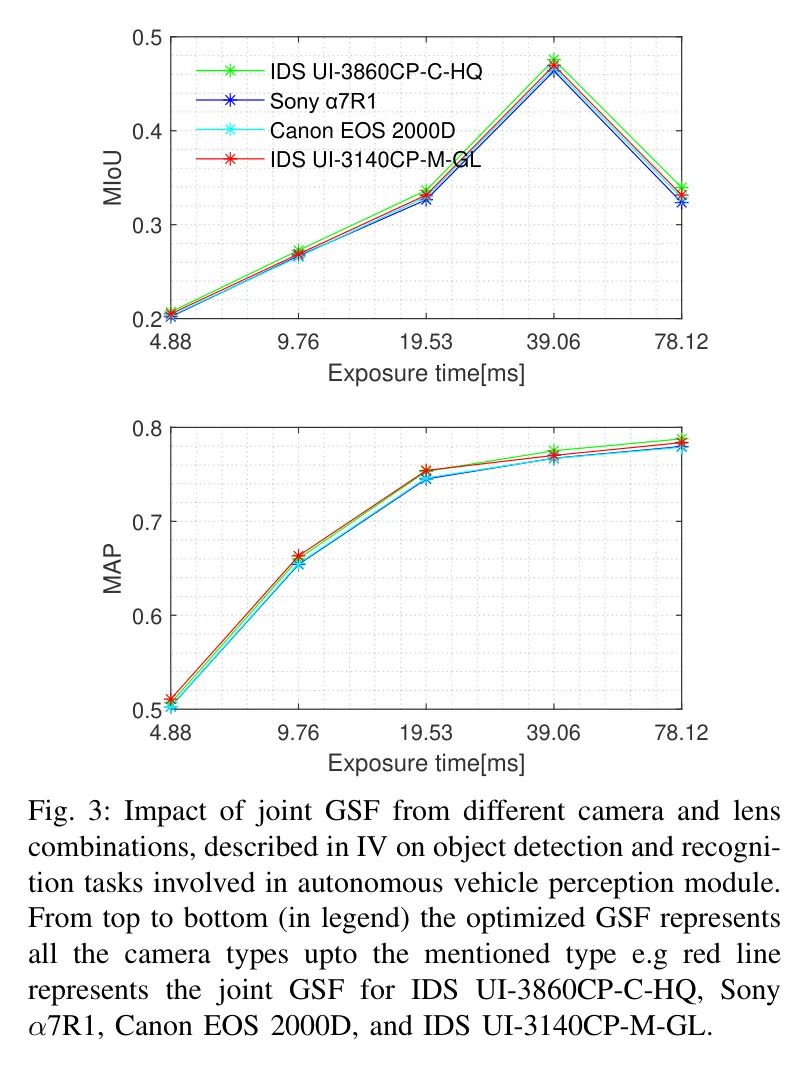
联合GSF与特定相机GSF的有效性对比,在当AVs的感知能力在数据由未包含在特定GSF估计中的相机捕获时显著下降的情景中变得尤为突出,如图5 Sony α7R1图表所示。
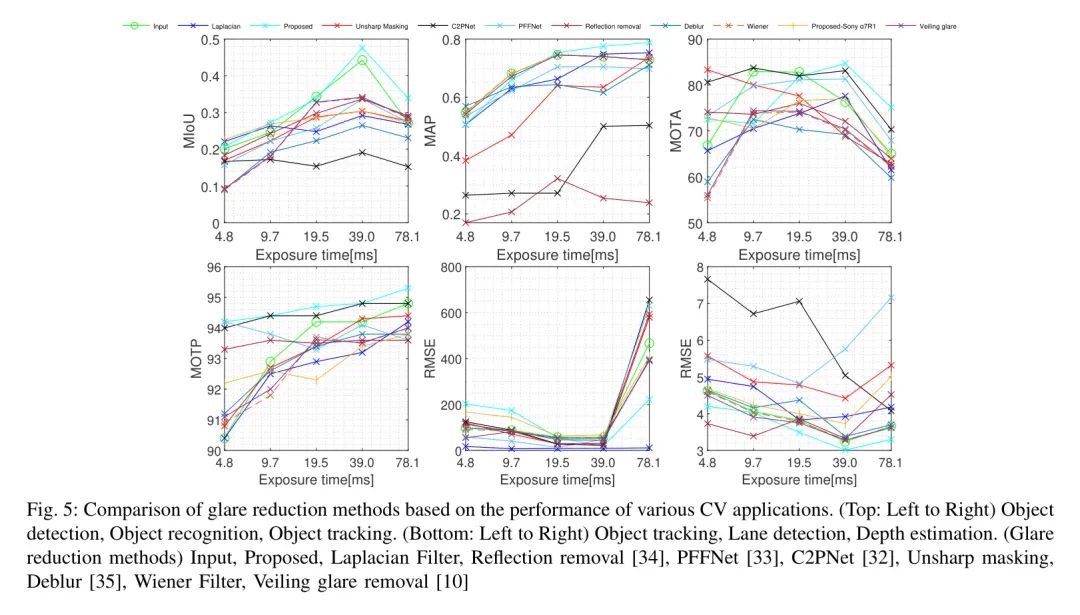
图5、表1和图6显示,在不同的感知任务中,各种眩光减少方法的表现存在显著差异。由于亮度和眩光增加之间的相关性,在最高曝光值下,受眩光影响的输入性能往往显著下降。然而,在计算机视觉任务的整个范围内,各种眩光减少方法的表现展现出独特的趋势,这对于理解它们在特定情况下的有效应用至关重要。特别是基于去卷积的方法,包括所提出的方法,在不同任务中处理眩光方面表现出显著的熟练度,并且在较高曝光水平下,其一致的高性能(高于任务报告的平均指标值)尤为突出。这种方法巧妙地保留了输入图像的特征,同时最小化眩光,这一特点并没有被维纳滤波器和Veiling眩光去除方法[10]有效地反映出来。

去雾方法在目标识别(OR)中呈现出明显的对比,其中PFFNet [33]能够表现得相当不错,而C2PNet [32]却完全失败。虽然这些方法降低了整体亮度,这在高曝光环境下可能是有利的,但通常的权衡是清晰度的降低和暗斑的出现,这显著影响了诸如目标检测(OD)和去模糊(DE)等任务。有趣的是,目标追踪(OT)似乎受到上述瑕疵的影响较小,在中等至高眩光水平下,去雾方法的表现超过了计算效率较高的图像增强方法,显示出它们的选择性效用。
对于图像增强技术,如局部拉普拉斯滤波和反锐化 Mask ,作者注意到其在有效性上的差异。尽管这些方法能增强对比度,但在存在炫光的情况下,它们常常会引入显著的伪影,正如在OD中看到的,这些伪影影响了它们的性能,降低了效率。然而,在OR中,尤其是在较高的曝光条件下,它们展示了提高性能的能力,这表明了基于特定任务和曝光条件的它们的选择性适用性。
去模糊和反射消除方法在减少炫光方面占有其独特的位置。去模糊技术在一些任务中,在低到中等曝光水平下虽然有效,但随着炫光的增强往往效果不佳。反射消除在恒定的光照条件下可能是一个可靠的选择,但在变化的光照环境中则失效。
图4:基于实际数据集上各种计算机视觉应用性能的炫光减少方法比较[31]。(顶部:从左至右) 目标检测、目标识别、目标追踪。(底部:从左至右) 目标追踪、车道线检测和深度估计。
总的来说,在计算机视觉任务中,去眩光方法的性能并不是一成不变的,而是显著地随不同类别及其内部的变化而变化。基于反卷积的方法,尤其是所提出的方法,在处理眩光方面通常表现卓越,特别是在高曝光度条件下。这一观察在诸如隧道场景中得到了进一步例证,在这些场景中,物体主要位于较暗的动态范围内。然而,值得注意的是,在极高曝光度水平下性能有所下降,这突显了这些方法在极端强烈的眩光条件下所面临的挑战。上述去眩光类别性能评估的总结在表1中呈现。
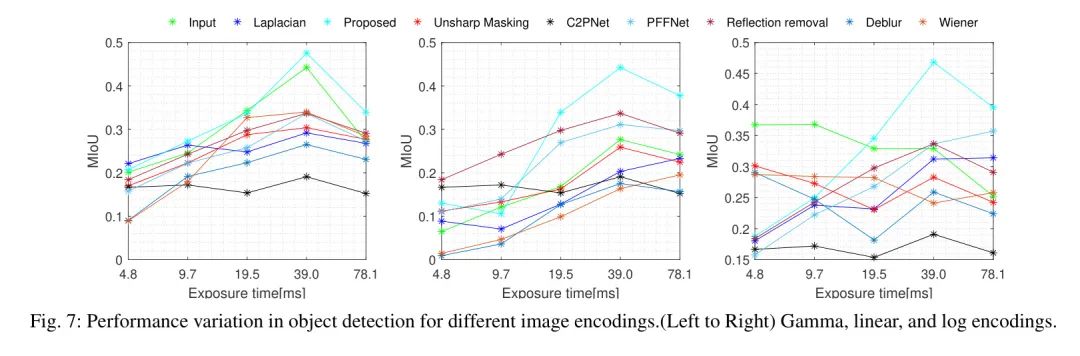
先前的研究,如[36]中所展示的,已经强调在传统的图像信号处理(ISP)流程中,有两个关键阶段显著影响着机器视觉算法的性能:去马赛克和图像编码。因此,在作者的研究中,作者采用了三种不同的图像编码技术,即伽马、对数和线性编码,具体细节将在第六节中阐述。
这种有意的选择使作者能够在减少与编码方法选择相关的潜在偏见的同时,全面评估各种眩光减少方法的有效性。尽管所提出的方法在其他眩光减少方法中表现出明显的优势,尤其是在目标检测任务中,如图7和图8所示,值得注意的是,在所测试的各种图像编码中,伽马编码明显更为优越。必须强调的是,本文评估的所有机器视觉技术都是在使用包含伽马编码图像的大型数据集进行预训练的。因此,对伽马编码存在一种偏见。因此,作者在评估眩光减少方法时选择了伽马编码。
为了全面评估作者的消眩光技术,必须在对来自实际自动驾驶车辆(AV)的数据集上进行测试,以此确认它在各种场景下的有效性。图4、图9和表2提供了作者的方法与现有方法在定量和定性上的比较。这种比较分析仅限于在原始数据集中可获得 GT 情况的选择性感知任务。所选择的任务取决于手动标注 GT 情况的可行性。正如图4和图9所示,作者的方法显著优于当前技术。然而,在受控实验设置(图5)和现实世界自动驾驶场景(图4)中,作者方法与现有技术之间性能差异的观察减小,可归因于实际数据集中较小的数据量和有限的眩光实例。

IX Conclusions
在本文中,作者介绍了一种旨在提高自动驾驶车辆(AV)感知能力的减光晕技术。该方法通过离线校准得到的组合GSF来估计受光晕影响饱和像素的真实辐射度。它解决了基于反卷积方法面临的两个主要挑战:在饱和区域准确预测辐射度以及由于GSF限制仅适用于单一数据源的应用限制。本文还研究了光晕对各种自动驾驶车辆感知任务的影响,强调了减光晕的重要性。评估结果表明,在多种感知任务上,提出的方法超过了在真实自动驾驶车辆捕获数据集上表现最佳的减光晕策略。具体来说,在目标检测上性能提高了5.15%,在目标识别上提高了18.16%,在车道线检测上提高了1.03%,这代表平均改进了8.11%。
参考
[1].How to deal with glare for improved perception of Autonomous Vehicles.