

写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
本文关键字:算法导论、插入排序、直接插入排序、算法实践
本专栏为《手撕算法》栏目的子专栏:《算法导论》,会讲述一些经典算法,并进行分析。在此之前我们要先了解什么是算法,能够解决什么样的问题。
以下为经典教材《Introduction.to.Algorithms》开篇中的内容。
Informally, an algorithm is any well-de?ned computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as output. An algorithm is thus a sequence of computational steps that transform the input into the output.
可以看到,任何被明确定义的计算过程都可以称作算法,它将某个值或一组值作为输入,并产生某个值或一组值作为输出。所以算法可以被称作将输入转为输出的一系列的计算步骤。
这样的概括是比较标准和抽象的,其实说白了就是步骤明确的解决问题的方法。由于是在计算机中执行,所以通常先用伪代码来表示,清晰的表达出思路和步骤,这样在真正执行的时候,就可以使用不同的语言来实现出相同的效果。
概括的说,算法就是解决问题的工具。在描述一个算法时,我们关注的是输入与输出。也就是说只要把原始数据和结果数据描述清楚了,那么算法所做的事情也就清楚了。我们在设计一个算法时也是需要先明确我们有什么和我们要什么,这一点相信大家在后面的文章中会慢慢体会到。
算法经常会和数据结构一起出现,这是因为对于同一个问题(如:排序),使用不同的数据结构来存储数据,对应的算法可能千差万别。所以在整个学习过程中,也会涉及到各种数据结构的使用。
常见的数据结构包括:数组、堆、栈、队列、链表、树等等。
在一个算法设计完成后,还需要对算法的执行情况做一个评估。一个好的算法,可以大幅度的节省运行的资源消耗和时间。在进行评估时不需要太具体,毕竟数据量是不确定的,通常是以数据量为基准来确定一个量级,通常会使用到时间复杂度和空间复杂度这两个概念。
通常把算法中的基本操作重复执行的频度称为算法的时间复杂度。算法中的基本操作一般是指算法中最深层循环内的语句(赋值、判断、四则运算等基础操作)。我们可以把时间频度记为T(n),它与算法中语句的执行次数成正比。其中的n被称为问题的规模,大多数情况下为输入的数据量。
对于每一段代码,都可以转化为常数或与n相关的函数表达式,记做f(n)。如果我们把每一段代码的花费的时间加起来就能够得到一个刻画时间复杂度的表达式,在合并后保留量级最大的部分即可确定时间复杂度,记做O(f(n)),其中的O就是代表数量级。
常见的时间复杂度有(由低到高):O(1)、O(
log
?
2
n
\log _{2} n
log2?n)、O(n)、O(
n
log
?
2
n
n\log _{2} n
nlog2?n)、O(
n
2
n^{2}
n2)、O(
n
3
n^{3}
n3)、O(
2
n
2^{n}
2n)、O(n!)。
程序从开始执行到结束所需要的内存容量,也就是整个过程中最大需要占用多少的空间。为了评估算法本身,输入数据所占用的空间不会考虑,通常更关注算法运行时需要额外定义多少临时变量或多少存储结构。如:如果需要借助一个临时变量来进行两个元素的交换,则空间复杂度为O(1)。
伪代码是用来描述算法执行的步骤,不会具体到某一种语言,为了表达清晰和标准化,会有一些约定的含义:
缩进:表示块结构,如循环结构或选择结构,使用缩进来表示这一部分都在该结构中。
循环计数器:对于循环结构,在循环终止时,计数器的值应该为第一个超出界限的值。
to:表示循环计数器的值增加。
downto:表示循环计数器的值减少。
by:循环计数器的值默认变化量为1,当大于1时可以使用by。
变量默认是局部定义的。
数组元素访问:通过"数组名[下标]"形式,在伪代码中,下标从1开始("A[1]“代表数组A的第一个元素)。
子数组:使用”…"来代表数组中的一个范围,如"A[i…j]"代表从第i个到第j个元素组成的子数组。
对象与属性:复合的数据会被组织成对象,如链表包含后继(next)和存储的数据(data),使用“对象名 + 点 + 属性名”。
特殊值NIL:表示指针不指向任何对象,如二叉树节点无子孩子可认为左右子节点信息为NIL。
return:返回到调用过程的调用点,在伪代码中允许返回多个值。
and和or:与运算和或运算默认短路,即如果已经能够确定表达式结果时,其他条件不会去判断或执行。
插入排序的基本思路是每次插入一个元素,每一趟完成对一个待排元素的放置,直到全部插入完成。
直接插入排序是一种最简单的排序方法,过程就是将每个待排元素逐个插入到已经排好的有序序列中。
由于在插入排序的过程中,已经生成了一个(排好的元素组成的)有序数列。所以在插入待排元素时可以使用折半查找的方式更快速的确定新元素的位置,当元素个数较多时,折半插入排序优于直接插入排序。
希尔排序可以看做是分组插入的排序方法,把全部元素分成几组(等距元素分到一组),在每一组内进行直接插入排序。然后继续减少间距,形成新的分组,进行排序,直到间距为1时停止。
n个数的序列,通常直接存放在数组中,可能是任何顺序。
输入序列的一个新排列,满足从小到大的顺序(默认讨论升序,简单的修改就可以实现降序排列)。
每次从原有数据中取出一个数,插入到之前已经排好的序列中,直到所有的数全部取完,那么新的有序排列也就完成了。
通俗一点的解释就是好比我们在打扑克抓牌,所有的牌扣在桌面上,我们一张一张的抓,抓起一张就在手里把它排好。那么等我们把所有的牌都抓起来之后,手里的牌也都是有序的了。
对于计算机来说,我们必须要详细的告诉它如何比较大小,以及如何确定位置,毕竟它不能像我们一样,“一眼”就看出位置。试想一下,当数据量比较多的时候,我们也是需要一个一个的看过来,然后才能确定新插入元素的位置。整个过程如下:

直接插入排序是一个比较好理解的算法,大家直接用抓牌就可以完美刻画:每次摸起一张牌,从右至左(从大到小)的与手中的牌比较,如果摸起来的这张是手牌里最大的,就直接放在最右边,如果不是最大的,就顺次滑过比它大的牌(相当于串位),直到遇见一个比刚摸起这张牌小的手牌,插入到这张牌的后面。
按照这样的步骤重复操作,当所有的牌都被抓完时,手里的牌就都是有序的了,理解了算法的思路后,我们用伪代码来进行表示:
for j = 2 to A.length
key = A[j]
i = j - 1
while i > 0 and A[i] > key
A[i + 1] = A[i]
i = i - 1
A[i + 1] = key
初始计数器为2,代表第一个元素默认排好,从第二个元素开始操作,直到最后一个元素。
每次用key记录新操作的元素,i的初始值代表当前操作元素的前一个元素,也就是第一个要与之比较的元素。
while循环为内层循环,作用是在已排好的元素中找到合适的位置,来将key插入。
如果进入到循环体中执行,代表key相对较小,还要再向前寻找,同时,与之比对的元素要向后串位,因为此时可以确定,key一定在这个元素的前面,在进入下一次循环时,使用再前面一位的元素进行比对。
for循环的最后一行是将key插入到对应的位置,外层循环结束(每次循环插入一个数)。
这里需要注意源代码与伪代码的区别,请查看文章开头补充的概念部分,这里不做过多说明。
public class DirectInsert {
public static void main(String[] args) {
// input data
int[] a = {11,34,20,10,12,35,41,32,43,14};
// 数组下标从0开始,j初始为1,指向第二个元素
for (int j = 1;j < a.length;j++){
// 使用key记录当前元素的值
int key = a[j];
// 初始化i,为j的前一个元素
int i = j - 1;
// while循环作用:在已经排好的有序数列中确定key的位置,并串出对应的位置
while(i > 0 && a[i] > key){
// 串位覆盖,不需要使用交换,值已经被记录在key中
a[i + 1] = a[i];
// 逐渐前移
i = i - 1;
}
// 将待排元素放在对应的位置
a[i + 1] = key;
}
// 查看排序结果
for (int data : a){
System.out.print(data + "\t");
}
}
}
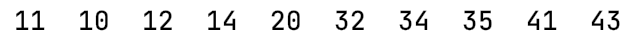
最坏的情况就是指每一行代码都被执行了,循环也是被完全拉满的情况,一次都没有少,确实很充实很悲催了。
对于直接插入排序来说,如果输入的元素刚好是反向有序的,那么每次取出一个元素,都要和已经排好的每一个元素进行比较,直到比较到第一个元素,然后把自己放在最前面,没办法,每次拿到的都是比之前小的元素,好气哦。
在这种情况下,内层while循环中的代码一共执行了
∑
i
=
1
n
?
1
i
=
n
(
n
?
1
)
2
=
O
(
n
2
)
\sum_{i=1}^{n-1} i=\frac{n(n-1)}{2}=O\left(n^{2}\right)
∑i=1n?1?i=2n(n?1)?=O(n2),其中n为输入的数据个数。
在计算时间复杂度时,我们只关心最后的量级就好,比如for循环中代码以及while循环中的代码都有多行,最后的结果一定比
n
2
n^{2}
n2大,但都是属于O(
n
2
n^{2}
n2)。
最好的情况就是指能不被执行的步骤都没有被执行,来的数据刚刚好,并且每个数据都是这样,简直就是天选之人。
对于直接插入排序来说,如果输入的元素已经是正向有序的,那么每次取出一个元素,在和已经排好的序列中的最后一个元素比较之后,就可以直接放到后面,循环都不用进,因为已经找到了它应该在的位置。
在这种情况下,内层的while循环可以只看成一个判断语句了,嗯,就是这样。所以代码执行的次数主要看外层for循环就好了,一共是n-1次,属于O(n)。
综合两种情况,插入排序的时间复杂度为O( n 2 n^{2} n2),有关于平均时间复杂度的计算大家可以自己去了解一下。
除计数器以外,算法执行过程中需要使用临时变量key来记录一下当前元素的值,除此之外的其他操作都可以在原数据结构(数组)上完成,所以空间复杂度为O(1)。


本文转载自微信公众号「SQL数据库」,作者丶平凡世界 。转载本文请联系开发公众...
本文转载自微信公众号「SH的全栈笔记」,作者SH。转载本文请联系SH的全栈笔记公...
本文实例讲述了AJAX+Servlet实现的数据处理显示功能。分享给大家供大家参考,具...
前言 项目开发中不管是前台还是后台都会遇到烦人的null,数据库表中字段允许空值...
在Flash Player 10.1及以上版本中,adobe新增了全局错误处理程序UncaughtErrorEv...
来源:DeepenStudy 漏洞文件:js.asp % Dimoblog setoblog=newclass_sys oblog.a...
大家好,我是狂聊君。 今天来聊一聊 Mysql 缓存池原理。 提纲附上,话不多说,直...
CKeditor,以前叫FCKeditor,已经使用过好多年了,功能自然没的说。最近升级到3....
问题:我们在做flex的开发中,如果用到别人搭建好的框架,而别人的server名称往...
idea官方推送了2020.2.4版本的更新,那么大家最关心的问题来了,之前激活idea202...


