

一、分析网页
以经典的爬取豆瓣电影 Top250 信息为例。每条电影信息在 ol class 为 grid_view 下的 li 标签里,获取到所有 li 标签的内容,然后遍历,就可以从中提取出每一条电影的信息。
翻页查看url变化规律:
- 第1页:https://movie.douban.com/top250?start=0&filter=
- 第2页:https://movie.douban.com/top250?start=25&filter=
- 第3页:https://movie.douban.com/top250?start=50&filter=
- 第10页:https://movie.douban.com/top250?start=225&filter=
start参数控制翻页,start = 25 * (page - 1)

本文分别利用正则表达式、BeautifulSoup、PyQuery、Xpath来解析提取数据,并将豆瓣电影 Top250 信息保存到本地。
二、正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便地检查一个字符串是否与某种模式匹配,常用于数据清洗,也可以顺便用于爬虫,从网页源代码文本中匹配出我们想要的数据。
re.findall
示例如下:
- import re
- text = """
- <div class="box picblock col3" style="width:186px;height:264px">
- <img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26584_s.jpg" 123nfsjgnalt="山水风景摄影图片">
- <a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
- <img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26518_s.jpg" enrberonbialt="山脉湖泊山水风景图片">
- <a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
- <img src2="http://pic2.sc.chinaz.com/Files/pic/pic9/202006/apic26029_s.jpg" woenigoigniefnirneialt="旅游景点山水风景图片">
- <a target="_blank" href="http://sc.chinaz.com/tupian/200509002684.htm"
- """
- pattern = re.compile(r'\d+') # 查找所有数字
- result1 = pattern.findall('me 123 rich 456 money 1000000000000')
- print(result1)
- img_info = re.findall('<img src2="(.*?)" .*alt="(.*?)">', text) # 匹配src2 alt里的内容
- for src, alt in img_info:
- print(src, alt)
- ['123', '456', '1000000000000']
- http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26584_s.jpg 山水风景摄影图片
- http://pic2.sc.chinaz.com/Files/pic/pic9/202007/apic26518_s.jpg 山脉湖泊山水风景图片
- http://pic2.sc.chinaz.com/Files/pic/pic9/202006/apic26029_s.jpg 旅游景点山水风景图片
代码如下:
- # -*- coding: UTF-8 -*-
- """
- @Author :叶庭云
- @公众号 :修炼Python
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- import re
- from pandas import DataFrame
- from fake_useragent import UserAgent
- import logging
- # 日志输出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "Connection": "keep-alive",
- "User-Agent": ua.random
- }
- return headers
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('请求网页失败')
- def get_data(page):
- url = f"https://movie.douban.com/top250?start={25 * page}&filter="
- html_text = scrape_html(url)
- # 电影名称 导演 主演
- name = re.findall('<img width="100" alt="(.*?)" src=".*"', html_text)
- director_actor = re.findall('(.*?)<br>', html_text)
- director_actor = [item.strip() for item in director_actor]
- # 上映时间 上映地区 电影类型信息 去除两端多余空格
- info = re.findall('(.*) / (.*) / (.*)', html_text)
- time_ = [x[0].strip() for x in info]
- area = [x[1].strip() for x in info]
- genres = [x[2].strip() for x in info]
- # 评分 评分人数
- rating_score = re.findall('<span class="rating_num" property="v:average">(.*)</span>', html_text)
- rating_num = re.findall('<span>(.*?)人评价</span>', html_text)
- # 一句话引言
- quote = re.findall('<span class="inq">(.*)</span>', html_text)
- data = {'电影名': name, '导演和主演': director_actor,
- '上映时间': time_, '上映地区': area, '电影类型': genres,
- '评分': rating_score, '评价人数': rating_num, '引言': quote}
- df = DataFrame(data)
- if page == 0:
- df.to_csv('movie_data2.csv', mode='a+', header=True, index=False)
- else:
- df.to_csv('movie_data2.csv', mode='a+', header=False, index=False)
- logging.info(f'已爬取第{page + 1}页数据')
- if __name__ == '__main__':
- for i in range(10):
- get_data(i)
三、BeautifulSoup
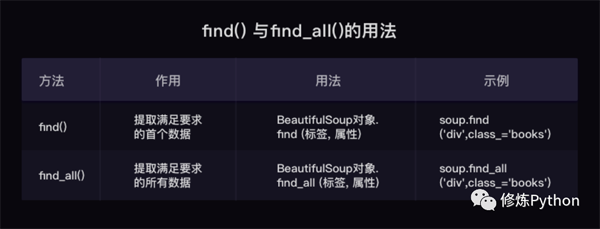
find( )与 find_all( ) 是 BeautifulSoup 对象的两个方法,它们可以匹配 html 的标签和属性,把 BeautifulSoup 对象里符合要求的数据都提取出来:

代码如下:
- # -*- coding: UTF-8 -*-
- """
- @Author :叶庭云
- @公众号 :修炼Python
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- from bs4 import BeautifulSoup
- import openpyxl
- from fake_useragent import UserAgent
- import logging
- # 日志输出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook() # 创建工作簿对象
- sheet = wb.active # 获取工作簿的活动表
- sheet.title = "movie" # 工作簿重命名
- sheet.append(["排名", "电影名", "导演和主演", "上映时间", "上映地区", "电影类型", "评分", "评价人数", "引言"])
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "Connection": "keep-alive",
- "User-Agent": ua.random
- }
- return headers
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('请求网页失败')
- def get_data(page):
- global rank
- url = f"https://movie.douban.com/top250?start={25 * page}&filter="
- html_text = scrape_html(url)
- soup = BeautifulSoup(html_text, 'html.parser')
- lis = soup.find_all('div', class_='item')
- for li in lis:
- name = li.find('div', class_='hd').a.span.text
- temp = li.find('div', class_='bd').p.text.strip().split('\n')
- director_actor = temp[0]
- temptemp1 = temp[1].rsplit('/', 2)
- time_, area, genres = [item.strip() for item in temp1]
- quote = li.find('p', class_='quote')
- # 有些电影信息没有一句话引言
- if quote:
- quotequote = quote.span.text
- else:
- quote = None
- rating_score = li.find('span', class_='rating_num').text
- rating_num = li.find('div', class_='star').find_all('span')[-1].text
- sheet.append([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- logging.info([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- rank += 1
- if __name__ == '__main__':
- rank = 1
- for i in range(10):
- get_data(i)
- wb.save(filename='movie_info4.xlsx')
四、PyQuery
如下示例:在解析 HTML 文本的时候,首先需要将其初始化为一个 pyquery 对象。它的初始化方式有多种,比如直接传入字符串、传入 URL、传入文件名等等。
- from pyquery import PyQuery as pq
- html = '''
- <div>
- <ul class="clearfix">
- <li class="item-0">first item</li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li><img src="http://pic.netbian.com/uploads/allimg/210107/215736-1610027856f6ef.jpg"></li>
- <li><img src="http://pic.netbian.com//uploads/allimg/190902/152344-1567409024af8c.jpg"></li>
- </ul>
- </div>
- '''
- doc = pq(html)
- print(doc('li'))
结果如下:
- <li class="item-0">first item</li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li><img src="http://pic.netbian.com/uploads/allimg/210107/215736-1610027856f6ef.jpg"/></li>
- <li><img src="http://pic.netbian.com//uploads/allimg/190902/152344-1567409024af8c.jpg"/></li>
首先引入 pyquery 这个对象,取别名为 pq,然后定义了一个长 HTML 字符串,并将其当作参数传递给 pyquery 类,这样就成功完成了初始化。接下来,将初始化的对象传入 CSS 选择器。在这个实例中,我们传入 li 节点,这样就可以选择所有的 li 节点。
代码如下:
- # -*- coding: UTF-8 -*-
- """
- @Author :叶庭云
- @公众号 :修炼Python
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- from pyquery import PyQuery as pq
- import openpyxl
- from fake_useragent import UserAgent
- import logging
- # 日志输出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook() # 创建工作簿对象
- sheet = wb.active # 获取工作簿的活动表
- sheet.title = "movie" # 工作簿重命名
- sheet.append(["排名", "电影名", "导演和主演", "上映时间", "上映地区", "电影类型", "评分", "评价人数", "引言"])
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "Connection": "keep-alive",
- "User-Agent": ua.random
- }
- return headers
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('请求网页失败')
- def get_data(page):
- global rank
- url = f"https://movie.douban.com/top250?start={25 * page}&filter="
- html_text = scrape_html(url)
- doc = pq(html_text)
- lis = doc('.grid_view li')
- for li in lis.items():
- name = li('.hd a span:first-child').text()
- temp = li('.bd p:first-child').text().split('\n')
- director_actor = temp[0]
- temptemp1 = temp[1].rsplit('/', 2)
- time_, area, genres = [item.strip() for item in temp1]
- quote = li('.quote span').text()
- rating_score = li('.star .rating_num').text()
- rating_num = li('.star span:last-child').text()
- sheet.append([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- logging.info([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- rank += 1
- if __name__ == '__main__':
- rank = 1
- for i in range(10):
- get_data(i)
- wb.save(filename='movie_info3.xlsx')
五、Xpath
Xpath是一个非常好用的解析方法,同时也作为爬虫学习的基础,在后面的 Selenium 以及 Scrapy 框架中也会涉及到这部分知识。
首先我们使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。其中,这里体现了 lxml 的一个非常实用的功能就是自动修正 html 代码,大家应该注意到了,最后一个 li 标签,其实我把尾标签删掉了,是不闭合的。不过,lxml 因为继承了 libxml2 的特性,具有自动修正 HTML 代码的功能,通过 xpath 表达式可以提取标签里的内容,如下所示:
- from lxml import etree
- text = '''
- <div>
- <ul>
- <li class="item-0"><a href="link1.html">first item</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-inactive"><a href="link3.html">third item</a></li>
- <li class="item-1"><a href="link4.html">fourth item</a></li>
- <li class="item-0"><a href="link5.html">fifth item</a>
- </ul>
- </div>
- '''
- html = etree.HTML(text)
- result = etree.tostring(html)
- result1 = html.xpath('//li/@class') # xpath表达式
- print(result1)
- print(result)
- ['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
- <html><body>
- <div>
- <ul>
- <li class="item-0"><a href="link1.html">first item</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-inactive"><a href="link3.html">third item</a></li>
- <li class="item-1"><a href="link4.html">fourth item</a></li>
- <li class="item-0"><a href="link5.html">fifth item</a></li>
- </ul>
- </div>
- </body></html>
代码如下:
- # -*- coding: UTF-8 -*-
- """
- @Author :叶庭云
- @公众号 :修炼Python
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- from lxml import etree
- import openpyxl
- from fake_useragent import UserAgent
- import logging
- # 日志输出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook() # 创建工作簿对象
- sheet = wb.active # 获取工作簿的活动表
- sheet.title = "movie" # 工作簿重命名
- sheet.append(["排名", "电影名", "导演和主演", "上映时间", "上映地区", "电影类型", "评分", "评价人数", "引言"])
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "Connection": "keep-alive",
- "User-Agent": ua.random
- }
- return headers
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('请求网页失败')
- def get_data(page):
- global rank
- url = f"https://movie.douban.com/top250?start={25 * page}&filter="
- html = etree.HTML(scrape_html(url))
- lis = html.xpath('//ol[@class="grid_view"]/li')
- # 每个li标签里有每部电影的基本信息
- for li in lis:
- name = li.xpath('.//div[@class="hd"]/a/span[1]/text()')[0]
- director_actor = li.xpath('.//div[@class="bd"]/p/text()')[0].strip()
- info = li.xpath('.//div[@class="bd"]/p/text()')[1].strip()
- # 按"/"切割成列表
- _info = info.split("/")
- # 得到 上映时间 上映地区 电影类型信息 去除两端多余空格
- time_, area, genres = _info[0].strip(), _info[1].strip(), _info[2].strip()
- # print(time, area, genres)
- rating_score = li.xpath('.//div[@class="star"]/span[2]/text()')[0]
- rating_num = li.xpath('.//div[@class="star"]/span[4]/text()')[0]
- quote = li.xpath('.//p[@class="quote"]/span/text()')
- # 有些电影信息没有一句话引言 加条件判断 防止报错
- if len(quote) == 0:
- quote = None
- else:
- quotequote = quote[0]
- sheet.append([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- logging.info([rank, name, director_actor, time_, area, genres, rating_score, rating_num, quote])
- rank += 1
- if __name__ == '__main__':
- rank = 1
- for i in range(10):
- get_data(i)
- wb.save(filename='movie_info1.xlsx')
六、总结
对于爬取网页结构简单的 Web 页面,有些代码是可以复用的,如下所示:
- from fake_useragent import UserAgent
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- def random_ua():
- headers = {
- "Accept-Encoding": "gzip",
- "User-Agent": ua.random
- }
- return headers
伪装请求头,并可以随机切换,封装为函数,便于复用。
- def scrape_html(url):
- resp = requests.get(url, headers=random_ua())
- # print(resp.status_code, type(resp.status_code))
- # print(resp.text)
- if resp.status_code == 200:
- return resp.text
- else:
- logging.info('请求网页失败')
请求网页,返回状态码为 200 说明能正常请求,并返回网页源代码文本。

一、Lambda架构需求 Lambda架构背后的需求是由于MR架构的延迟问题。MR虽然实现了...
大数据是科技界的流行语。这项技术引领着企业的大型项目,现在,DevOps自动化正...
数字经济时代 越来越多的企业通过数据驱动业务增长、流程优化及更多的业务创新。...
物联网的传感器源源不断产生的大量数据,构成了大数据的重要来源。没有物联网的...
我们都知道开发过程中应该编写单元测试,实际上我们中的许多人都这样做。对于生...
随着前端项目不断扩大,浏览器渲染的压力变得越来越重。配置好一点的计算机可以...
基本概念 从数据存储来看,数组存储方式和树的存储方式可以相互转换,即数组可以...
包年/包月方式购买的裸金属服务器到期后,如果没有按时续费,华为云会提供一定的...
今天跟大家介绍4款比较常用的,前端开发工具,大家可以根据自己的使用情况,说说...
从诞生到开放使用 随着中国的发展,很多技术因为一些原因越来越受制于人,尤其是...

