

案例背景
小打卡是国内最大的兴趣社群平台,每天能够产生上百万条新的内容。在这样超大的内容生产背景下,平台也面临着千人千面、内容分发上的巨大挑战。依托于阿里云MaxCompute,小打卡已经完成了TB级数据仓库方案。在此基础之上,结合机器学习PAI,实现了千人千面的推荐算法。本文将从技术选型、推荐架构、开源算法结合三个方面,讲述小打卡在MaxCompute上的一些实战经验。
为什么选择阿里云
MaxCompute是阿里云完全自研的一种快速、完全托管的TB/PB级的数据仓库解决方案,并且上层提供了DataWorks以实现工作流可视化开发、调度运维托管的一站式海量数据离线加工分析平台。除此之外,MaxCompute还与阿里云服务的多个产品集成,比如:
- 数据集成:完成MaxCompute与各种数据源的相互同步。
- 机器学习PAI:实现直接基于MaxCompute完成数据处理、模型训练、服务部署的一站式机器学习。
- QuickBI:对MaxCompute 表数据进行报表制作,实现数据可视化分析。
- 表格存储:阿里云自研的分布式NoSQL 数据存储服务,MaxCompute 离线计算的机器学 习特征可以很方便的写入,以供在线模型使用。
相反,如果完全基于开源的Hadoop 框架,从服务部署、可视化开发、代码管理、 任务调度、集群运维等多方面,均需要大量的人力来开发与维护。基于MaxCompute, 不论是人力成本,还是计算成本,还是运维成本,都已经降到了最低。
系统架构
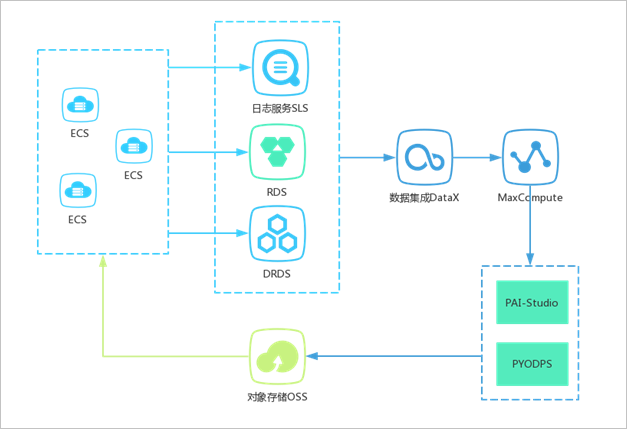
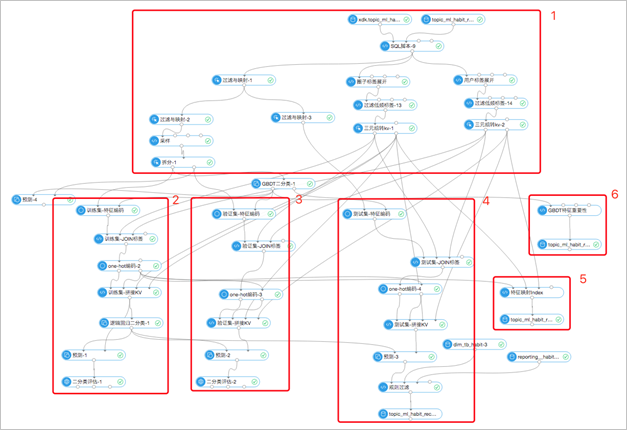
图中采用了丰富的PAI 机器学习组件,主要包括6 个部分:1- 特征加工,2- 训 练模型,3- 验证模型,4- 测试模型,5- 特征映射关系,6- 特征重要性。开发完成 后,可以加载到DataWorks 中进行调度,运行完成会生成GBDT 模型文件(pmml 格式)、LR 模型文件(pmml 格式)、特征映射表,以便线上使用。由于我们后端主 服务均在华北1,而PAI 的模型在线部署在华东2,存在着公网访问问题,因此我们 暂时无法使用PAI 的模型在线部署功能,建议大家将两部分放在同一地域。鉴于此问 题,幸好PAI 的同学提供了将pmml 模型文件写入oss 的脚本,相关代码如下:
-DmodelName=xlab_m_GBDT_LR_1_1806763_v0
-DossPath="oss://test.oss-cn-shanghai-internal.aliyuncs.com/model/"
-Darn="acs:ram::123456789:role/aliyunodpspaidefaultrole"
-Doverwrite=true
-Dformat=pmml;因此我们可以将pmml 文件写入oss,然后后端服务读取pmml 模型文件,自 行创建模型在线预测。对于解析pmml 模型文件,虽然有开源项目支持pmml 模型加 载,但是由于pmml 过于通用,导致性能存在问题,因此我们定制化自解析模型。
如何结合开源算法
遗憾的是,PAI 提供的机器学习算法仍然有限,如果想要使用开源项目来实现算 法部分怎么办呢?我们对此也做了尝试,我们则结合MaxCompute+PAI+xLearn 实现了基于FM 算法的CTR 预估模型。 xLearn 需要在单独的一台ECS 上执行,因此引出了以下问题:
- 如何从MaxCompute 拉取数据,又如何上传结果? MaxCompute 提供了pyodps,可以很方便的使用python 读写MaxCompute 的离线表。因此,我们在python 循环检测PAI 任务的特征工程结果表是否生成完 成。生成完成,则启动下载数据和算法训练任务。算法执行结束后,则将模型文件通 过pyodps 写入MaxCompute,当然也可以使用tunnel 工具来完成。
- 如何周期性调度? DataWorks 上的任务与ECS 上的任务,如何形成依赖 关系? 对于拉取,我们通过循环实现了python 与MaxCompute 表的依赖关系,那么
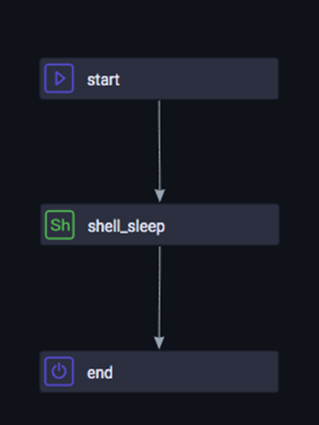
算法训练完成了,DataWorks 的下游怎么知道呢?幸好,DataWorks 提供了dowhile 控制流组件,我们可以在while 条件中检测模型表相应分区的数据是否存在了,
在 do 组件中,则采用shell 执行sleep。跳出while 后,则下游也开始正常执行了。 之后便可以将模型和映射文件同步写入到oss,以供后端使用了。其中
do-while 结 构如下:
上云价值
除了排序算法之外,我们还使用PAI 和SQL,分别实现了item_cf 和user_cf 的召回算法,整个推荐系统完全打通。基于MaxCompute 利用DataWorks 调度系 统,我们实现了推荐算法模型的每日自动更新。相比于模型不更新,我们对比了60 天前的模型,新的模型效果提升10% 左右。 期待阿里云提供越来越丰富的功能,例如基于MaxCompute 的Spark 机器学习。
相关产品
- 大数据计算服务 · MaxCompute
MaxCompute(原ODPS)是一项大数据计算服务,它能提供快速、完全托管的PB级数据仓库解决方案,使您可以经济并高效的分析处理海量数据。
更多关于阿里云MaxCompute的介绍,参见MaxCompute产品详情页。
- 机器学习PAI
阿里云机器学习平台PAI(Platform of Artificial Intelligence),为传统机器学习和深度学习提供了从数据处理、模型训练、服务部署到预测的一站式服务。
更多关于机器学习PAI的介绍,参见机器学习PAI产品详情页。
- DataWorks
DataWorks是一个提供了大数据OS能力、并以all in one box的方式提供专业高效、安全可靠的一站式大数据智能云研发平台。 同时能满足用户对数据治理、质量管理需求,赋予用户对外提供数据服务的能力。
更多关于阿里云DataWorks的介绍,参见DataWorks 产品详情页。
- 对象存储OSS
阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。其数据设计持久性不低于 99.9999999999%(12 个 9),服务设计可用性(或业务连续性)不低于 99.995%。
更多关于对象存储OSS的介绍,参见对象存储OSS产品详情页。


