

本篇我们从底层存储数据结构出发,讲一讲Hive是如何组织数据的。
行式存储 v.s. 列式存储
传统数据库大多基于行(Row-based)实现数据存储,即一行行的记录。此类存储结构对大多数的传统数据工作都是非常有效的,下面我们先来回顾一下数据库系统中数据工作的概念:
OLTP是传统数据工作的主要应用,主要是基本的、日常的事务处理,即插入、修改、查询和删除等操作。
OLAP是数据分析和数据挖掘工作的主要应用。OLAP支持复杂的分析操作,侧重决策支持并提供直观易懂的查询结果。

在Row-based数据库中,一行记录中的每一列都是紧挨着另一列存放在硬盘中的,行之间也成线性存储。这样的模式十分适用于OLTP工作,由于每次操作对象都是某几行记录,每次查询只需要从硬盘中加载最少的数据。
OLAP更倾向于访问百万、千万甚至上亿条记录。传统的行式存储(Row-oriented Storage)使得我们需要花费时间加载每一行,而真正需要的数据可能仅是每行中的几个数据列而已。如果存储结构基于列(Column-based),那么单列查询就只需要加载硬盘中的最小列块,这种方式在磁盘IO上是比较高效的。正是如此,我们可以说OLAP促成了列式存储(Columnar Storage)的出现。
下图展示了Row-oriented Storage和Columnar Storage的原理:
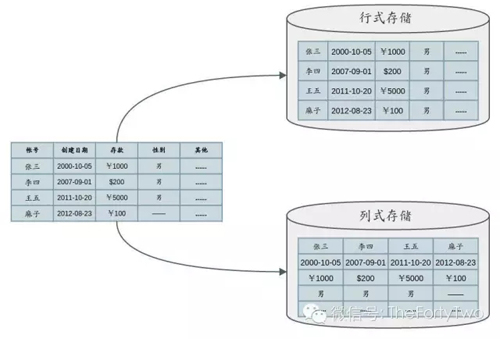
当然,列式存储也并非***。单纯给Column-based数据表加索引,并不能使其在OLTP工作流上表现高效。就删改记录等需求而言,查询任务需要加载磁盘中的很多列块才能整合一条完整的记录。如果一个数据表的列项过于丰富,那么Columnar Storage反而会加重OLTP工作流的磁盘I/O负载。相比而言,Row-oriented Storage则更适合对单一整行记录的处理。
如何选择存储结构取决于你的企业对OLTP/OLAP业务的需求。目前还有一些行列混合存储技术结合了两种架构的优势。例如针对Columnar Storage提出的列组(Column Group)概念,多个列形成一个组。如果访问的列属于同一组,查询工作流就可以避免多个数据列的合并。这种结构能够同时满足OLTP和OLAP的查询需求。
Columnar Storage从一开始就是面向大数据环境下数据仓库的数据分析而产生的。下文我们就从Hive的实际应用中介绍Columnar Storage的优点。
Hive的数据格式
目前Hive所支持的数据格式如下:
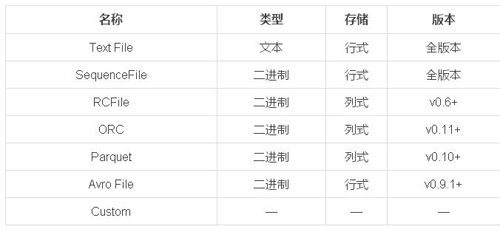
我们根据Hive文档的描述,简单介绍几类Columnar Storage的数据格式。
RCFile
RCFile(Record Columnar File)是为基于MapReduce的数据仓库系统设计的一个列式存储结构。Hive在0.6.0版本后纳入了RCFile。
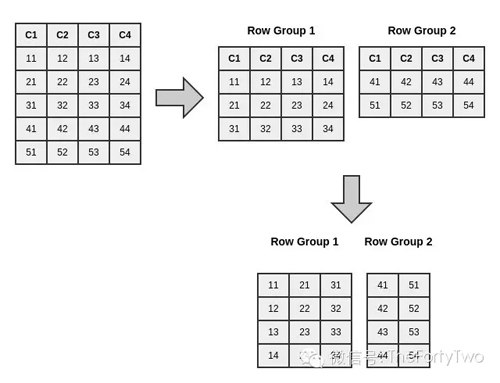
RCFile采用二进制的key/value对来存储数据。首先,它在行上进行水平分块,然后每块又以列式的方式垂直切割。RCFile将一个数据块的metadata作为一条记录的key,而数据块本身作为value。这样结合行式和列式的优点,满足了高效的数据加载和查询处理,以及有效利用存储空间等需求。下图为RCFile的数据分块原理:
ORC
ORC(Optimized Row Columnar)在RCFile基础上改进,提供了更加高效的数据存取格式。和RCFile相比,ORC有如下优势:
Parquet
Apache基金会的Parquet是在Hadoop生态圈中受到广泛支持的列式存储格式。Parquet借鉴Dremel文章中提到的Shredding and assembly算法,将复杂、嵌套的数据结构展开来存储。同时它还支持非常高效的压缩方法和编码格式。目前很多实际应用也证实了这种压缩和编码的优越性能。下面是Parquet目前所支持的项目和数据描述语言:
MapReduce、Hive、Drill、Impala、Crunch、Pig、Cascading、Spark
Avro、Thrift、Google Protocol Buffers
Hive 0.13后,Parquet已经被作为原生态支持而正式加入Apache Hive项目。在之前的版本中,你需要将parquet-hive-bundle.jar作为第三方支持包加载到Hive中方可使用Parquet。
Why Columnar Storage?
下面从实战角度出发,用一系列的实验给读者展示在数据仓库中使用Columnar Storage的优势。
我们选择以下维度作为PB.LZO(LZO压缩)、RCFile、ORC以及Parquet的性能标准:
为了达成这些指标的测试,我们选取910GB的文本数据。这些数据一方面转换为PB.LZO格式保存;另一方面采用上述后三种Columnar Storage数据格式保存,并以Snappy或Gzip/Zlib压缩。实验结果如下:
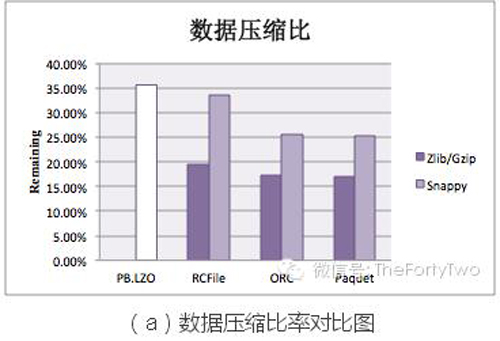
从图(a)中可以得知,Columnar Storage比Row-oriented Storage具有更高的压缩比。同一列内的数据比之不同列之间,具有更高的相似度。所以列块比行的压缩效果更加明显。
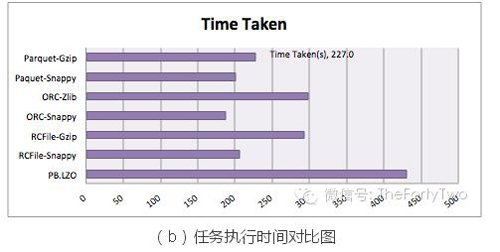
图(b)表示任务执行时间。由于任务执行时间受诸多因素(例如集群计算资源闲忙情况、实验次数是否能充分消除随机性、网络吞吐等等)影响,我们这里只将其作为参考。
复杂查询会增加Reduce的计算时间,而Columnar Storage技术并不会加速Reduce的业务逻辑计算。所以我们选择的测试任务均为:
select count(col1) from table。

图(c)展示的文件输入量对比充分显示了Columnar Storage的优势。相比PB.LZO,采用各类Columnar Storage技术的任务Map输入量都仅占各自数据存储大小的一半以下,是PB.LZO输入量的约三分之一。Parquet和ORC在这里表现***。值得一提的是,就执行select count(*) from table而言,Parquet和ORC可以将Map输入量缩减到100MB以下,这几乎不造成太大的网络I/O开销。
Columnar Storage如何降低文件输入量,取决于其列组的分割方式。越细粒度的列组越能降低简单OLAP工作流的文件读取量。但是多列交叉查询就会导致频繁的数据列合并,从而降低查询效率。所以我们需要平衡列式存储查询效率和文件吞吐量之间的收益。
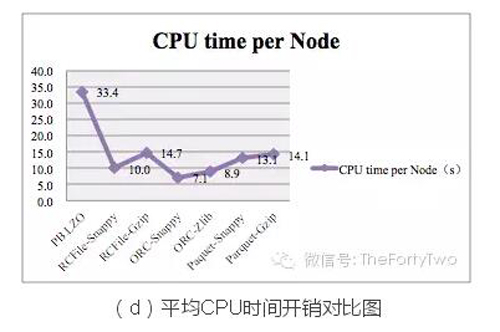
图(d)中,CPU开销从小到大依次是:ORC-Snappy > ORC-Zlib > RCFile-Snappy > Paquet-Snappy > Parquet-Gzip >RCFile-Gzip > PB.LZO。实验中我们通过设置不同的min.split.size调整Mapper数均为600,***程度降低环境因素影响。
上述实验中,以ORC-Snappy为例,性能优化比之PB.LZO如下:
我们可以看到,各类Columnar Storage技术在OLAP工作流上的优势是很明显的。

【51CTO.com原创稿件】在大数据时代的当下,越来越多的企业希望借助高效的IT系统...
做网站,必然要使用主机空间,或者服务器。因为网站规模、访问流量等原因,个人...
无论是CDN缓存加速,还是CPU的三级缓存,又或者是在如今互联网时代流量红利所带...
【51CTO.com原创稿件】2018年5月18-19日,由51CTO主办的全球软件与运维技术峰会...
香港云服务器选什么系统比较好 ?大家在租用香港云服务器时,不知道该如何挑选服...
【51CTO.com原创稿件】新春伊始,一场突如其来的新冠肺炎,迅速席卷全国,令原本...
云计算的兴起,让企业数据存储需求出现了长期、稳定的下滑。尽管目前还没有逆转...
1.数据中心是什么 数据中心,指用于安置计算机系统及相关部件的设施,例如电信和...
随着应用程序的不断增长,内存被迫承担着更大压力。目前不管是服务器还是PC领域...
美国由于坐落于国际性的大数据中心,因此其可靠性都是较为强的,并且美国免备案...

