【玩转 GPU】英伟达GPU架构演变
原创

一、GPU架构发展历史
1999年,英伟达发布第一代GPU架构GeForce 256,标志着GPU时代的开始。随后,英伟达推出了Tesla、Fermi、Kepler、Maxwell、Pascal、Volta、Turing和Ampere等GPU架构,不断增强GPU的计算能力和程序性,推动GPU在图形渲染、人工智能和高性能计算等领域的应用。
二、Tesla架构
2006年,英伟达发布首个通用GPU计算架构Tesla。它采用全新的CUDA架构,支持使用C语言进行GPU编程,可以用于通用数据并行计算。Tesla架构具有128个流处理器,带宽高达86GB/s,标志着GPU开始从专用图形处理器转变为通用数据并行处理器。
三、Fermi架构
2009年,英伟达发布Fermi架构,是第一款采用40nm制程的GPU。Fermi架构带来了重大改进,包括引入L1/L2快速缓存、错误修复功能和 GPUDirect技术等。Fermi GTX 480拥有480个流处理器,带宽达到177.4GB/s,比Tesla架构提高了一倍以上,代表了GPU计算能力的提升。
四、Kepler架构
2012年,英伟达发布Kepler架构,采用28nm制程,是首个支持超级计算和双精度计算的GPU架构。Kepler GK110具有2880个流处理器和高达288GB/s的带宽,计算能力比Fermi架构提高3-4倍。Kepler架构的出现使GPU开始成为高性能计算的关注点。
五、Maxwell架构
2014年,英伟达发布Maxwell架构,采用28nm制程。Maxwell架构在功耗效率、计算密度上获得重大提升,一个流处理器拥有128个CUDA核心,而Kepler仅有64个。GM200具有3072个CUDA核心和336GB/s带宽,但功耗只有225W,计算密度是Kepler的两倍。Maxwell标志着GPU的节能计算时代到来。
六、Pascal架构
2016年,英伟达发布Pascal架构,采用16nm FinFETPlus制程,增强了GPU的能效比和计算密度。Pascal GP100具有3840个CUDA核心和732GB/s的显存带宽,但功耗只有300W,比Maxwell架构提高50%以上。Pascal架构使GPU可以进入更广泛的人工智能、汽车等新兴应用市场。
七、Volta架构
2017年,英伟达发布Volta架构,采用12nm FinFET制程。Volta 架构新增了张量核心,可以大大加速人工智能和深度学习的训练与推理。Volta GV100具有5120个CUDA 核心和900GB/s的带宽,加上640个张量核心,AI计算能力达到112 TFLOPS,比Pascal架构提高了近3倍。Volta的出现标志着AI成为GPU发展的新方向。
八、Turing架构
2018年,英伟达发布Turing 架构,采用12nm FinFET制程。Turing架构新增了Ray Tracing核心(RT Core),可硬件加速光线追踪运算。Turing TU102具有4608个CUDA核心、576个张量核心和72个RT核心,支持GPU光线追踪,代表了图形技术的新突破。同时,Turing架构在人工智能方面性能也有较大提升。
九、Ampere架构
2020年,英伟达发布Ampere架构,采用Samsung 8nm制程。Ampere GA100具有6912个CUDA核心、108个张量核心和hr个RT核心,比Turing架构提高约50%。Ampere 架构在人工智能、光线追踪和图形渲染等方面性能大幅跃升,功耗却只有400W,能效比显著提高。
从Tesla架构到Ampere架构,英伟达GPU在体系结构、性能和功能上不断创新,不断推动图形渲染、高性能计算和人工智能等技术发展。随着GPU架构的不断演进,GPU已经从图形渲染的专用加速器,发展成通用的数据并行处理器,在人工智能、自动驾驶、高性能计算等领域获得广泛应用。
从Tesla架构到Ampere架构,全面而深入地剖析了英伟达GPU近15年来的架构演变历史,详细介绍了各GPU架构的制程、规格、特性以及技术意义。通过这些分析可以清晰地看出,英伟达GPU架构在不断演进中实现了跨越式的提高,不但加强了图形渲染和通用计算功能,也在人工智能和光线追踪等新兴技术上作出了持续创新,成就了GPU在各领域的广泛应用,希望本文能够对读者理解英伟达GPU发展历史和未来走向提供全面而深入的认知。

Part One: 介绍与概述
互联网的发展速度越来越快,对于计算机的运行速度和计算能力提出了更高的要求。因此,GPU作为一种专门用于图形处理和运算的显卡,成为了性能升级的关键部分。英伟达是一家全球领先的GPU制造商,英伟达显卡作为目前最流行的显卡之一,广泛应用于游戏、数据分析、深度学习、虚拟现实等领域。本文将从互联网专家的角度出发,详细介绍英伟达显卡的运行原理、结构组成、各组件的介绍、应用技术、多模态构成及GPU运行原理等内容。
Part Two: 几个重要的概念

首先,我们需要了解以下几个重要的概念:
1.显卡:
显卡(Graphics Processing Unit, GPU)是负责计算机图形显示的计算机零部件,它在计算机系统中起到了至关重要的作用。GPU主要用于图像渲染、物理模拟、人工智能等运算。
2.流处理器:
流处理器(Stream Processor)是指显卡上用于执行相关操作的计算单元,每个流处理器可以同时执行多个线程,从而提高运算效率。
3.并行计算:
并行计算(Parallel Computing)是指使用多个CPU或GPU同时进行运算,以提高运算效率。并行计算应用程序一般采用线程池、消息传递等技术,通过多线程、多进程或多节点,并行执行任务,实现执行效率的提升。
Part Three: 英伟达显卡的结构组成

英伟达显卡是由以下几个部分组成的:
1.GPU核心:
GPU核心是整个显卡最重要的部分,它负责承担所有的计算任务,包括图形渲染、物理模拟、人工智能等运算。
2.内存:
内存(Memory)是显卡用于存储数据和代码的部分,它可以快速访问大量数据,大大提高了显卡的运算速度。
3.显存:
显存(Video Memory)是显卡专门用来存储图形数据的部分,它比普通内存更快速,可以更好地支持图形运算。
4.电源:
电源(Power)是显卡运行所必需的部分,它通过电源供应器向显卡供电,保证整个显卡系统正常运行。
5.散热系统:
散热系统(Cooling System)是显卡用于控制温度的部分,它通过散热风扇或水冷等方式降低显卡内部温度,保护显卡硬件。

Part Four: 各组件的详细介绍

1.GPU核心
GPU核心是整个显卡最重要的部分,它是显卡上的一种高性能ASIC(Application Specific Integrated Circuit,应用特定的集成电路)。它具有非常高的计算能力,可以同时处理大量数据,实现实时渲染、物理模拟、人工智能等运算。
GPU核心通过内部的流处理器(Stream Processor)来实现高效的并行计算,其中每个流处理器可以同时执行多个线程,从而大大提高运算效率。英伟达显卡的GPU核心一般由多个GPU芯片组成,从而实现更高的计算能力和速度。
2.内存
内存(Memory)是显卡用于存储数据和代码的部分,它可以快速访问大量数据,大大提高了显卡的运算速度。当前英伟达显卡的内存主要分为两种:GDDR5和GDDR6。GDDR5内存具有高带宽、低延迟和低功耗等特点,通常用于较低端的显卡;而GDDR6内存则具有更高的带宽、更低的延迟和更高的功耗,适用于高端游戏等需要更高性能的应用。
3.显存
显存(Video Memory)是显卡专门用来存储图形数据的部分,它比普通内存更快速,可以更好地支持图形运算。英伟达显卡的显存一般分为两种:GDDR5和GDDR6。GDDR5显存通常用于中低端显卡,而GDDR6显存则主要适用于高端的游戏和图形应用。
4.电源
电源(Power)是显卡运行所必需的部分,它通过电源供应器向显卡供电,保证整个显卡系统正常运行。英伟达显卡的电源一般需要较大的功率,因为GPU核心的高性能计算需要较高的能源。目前,英伟达显卡的电源工作在250W到500W之间,高端的显卡功率甚至可以达到1000W以上。
5.散热系统
散热系统(Cooling System)是显卡用于控制温度的部分,它通过散热风扇或水冷等方式降低显卡内部温度,保护显卡硬件。英伟达显卡的散热系统通常采用液态金属散热或双风扇散热技术,以有效地控制显卡温度。此外,在近几年,英伟达显卡开始采用雷电三接口,极大地加强了显卡的稳定性和扩展性。
Part Five: 英伟达显卡的应用技术

1.物理模拟技术
英伟达显卡的物理模拟技术采用了粒子动态模拟方式,在三维空间内模拟多个物体的运动状态。粒子动态模拟可以更好地模拟现实世界的物理极限,例如烟雾、火焰等。
2.深度学习技术
英伟达显卡的深度学习技术主要通过CUDA(Compute Unified Device Architecture)平台实现。CUDA平台能够利用GPU的并行计算能力,高效地进行深度学习数据处理,极大地提高了深度学习的速度和精度。例如,英伟达的Tensor Core技术可以将深度学习计算的速度提高到原计算的128倍,大大节约了深度学习的运算时间。
3.虚拟现实技术
英伟达显卡的虚拟现实技术是采用了VXGI和VRWorks等技术,提高了虚拟现实应用的画面效果和流畅度,同时,英伟达显卡的支持能力及不同的软件开放接口都能更好的整合和优化各种应用程序。
Part Six: 多模态构成
英伟达显卡的多模态构成主要由CUDA、OpenGL及OpenCL等技术构成。
1.CUDA
CUDA(Compute Unified Device Architecture)平台是英伟达推出的一种并行计算技术,主要用于加速GPU的计算能力。通过CUDA平台,英伟达显卡可以高效地处理复杂的计算任务,提高计算性能。
2.OpenGL
OpenGL是一种开放的图形编程接口,可以在不同的操作系统和硬件平台上运行。英伟达显卡支持OpenGL技术,并可以通过OpenGL实现硬件加速的图形渲染。
3.OpenCL
OpenCL是一种开放的并行计算框架,可以同时利用多个处理器来进行运算。英伟达显卡支持OpenCL技术,可以通过OpenCL实现硬件加速的数据处理和计算。
Part Seven: GPU运行原理

GPU核心通过内部的流处理器(Stream Processor)来实现高效的并行计算,其中每个流处理器可以同时执行多个线程,从而大大提高运算效率。GPU核心的运行方式与CPU略有不同,在GPU核心中,CPU将数据和指令传送到GPU中去,GPU再将数据加载到GPU的内存中,并利用内部的流处理器执行计算任务。执行完成后,将计算结果传回CPU中。以图形运算为例,GPU核心会根据CPU传送过来的图形指令,对图形进行计算,再将计算结果加载到显卡的显存中,最后再将计算出来的图像输出到显示器上。
Part Eight: 结论
本文通过从互联网专家的角度出发,详细介绍了英伟达显卡的运行原理、结构组成、各组件的介绍、应用技术、多模态构成及GPU运行原理等内容。英伟达显卡以其高效的计算能力、卓越的图形处理能力和广泛的应用领域,成为了目前最流行的显卡之一。当前,英伟达显卡正在加速推进技术的研发,通过更高端的技术在游戏、数据分析、深度学习、虚拟现实、人工智能等领域发挥着重要的作用。
英伟达显卡是当今最先进的图形处理器之一,在GPU领域处于技术领先地位。本文将从显卡的发展历史、运行原理、系统结构、关键组件、核心技术以及多模态构成等方面进行全面而深入的分析阐述。
一、发展历史
英伟达显卡的前身可追溯至1999年推出的GeForce 256显卡,它是第一款采用“GPU”这个概念的产品,标志着GPU时代的开始。随后,英伟达推出了GeForce系列显卡产品,在PC游戏和其他图形应用中获得主流地位。2006年,英伟达推出第一代CUDA架构GPU,可以用于通用数据并行计算,开启了GPU计算时代。2016年,英伟达推出支持光线追踪的Quadro RTX系列显卡,实现实时光线追踪的突破。最近几年,英伟达还在GPU中加入了张量核心和RT核心,可以支持 AI和神经网络计算等新型工作负载。可以看出,英伟达显卡在GPU应用和体系结构上不断创新,推动着整个GPU技术发展。
二、运行原理
英伟达显卡属于并行结构的高性能计算设备。其核心理念是将图像的渲染任务分解为大量小的子任务,由成千上万个流处理器同时并行执行,从而达到极高的计算效率。这种并行结构决定了GPU必须处理海量的数据,才能充分发挥其计算优势。因此,英伟达显卡都是设计为处理大规模图像运算和图形渲染的高性能专用设备。
三、系统结构
英伟达显卡是一个非常复杂的集成电路系统。其主要组成部分包括:图形处理器(GPU)、视频记忆体(Video Memory)、显存接口、显示输出接口(Display Interface)等。GPU是显卡的核心,负责执行复杂的运算任务。视频记忆体用于存储图像和图形数据以供GPU访问。显存接口负责GPU和视频记忆体之间的高速数据传输。显示输出接口将渲染后的图像信号输出到显示设备。
四、关键组件
英伟达GPU采用异构体系结构,主要由流处理器(Streaming Processor)、张量核心(Tensor Core)和RT核心(RT Core)组成。流处理器用于通用计算和图形渲染。张量核心用于AI加速和神经网络运算。RT核心专门用于光线追踪运算。这种设计使得GPU既可用于图形渲染,也可用于人工智能和光线追踪等新兴工作负载。
五、核心技术
英伟达显卡有多种核心技术,如:
1) CUDA:一种GPU通用计算架构,使开发人员可以利用GPU进行通用数据并行计算。
2) OptiX:一种GPU光线追踪框架,提供光线追踪算法和程序库。
3) DLSS:一种利用AI实现超分辨率和提高渲染性能的技术。它使用神经网络对低分辨率图像进行 predicts,输出高分辨率图像。
4) RTX:英伟达针对光线追踪开发的 GPU架构,提供硬件级光线追踪支持。
六、多模态构成
英伟达GPU通过流处理器、张量核心和RT核心实现了多模态设计,可以支持多种工作负载:
1) 流处理器用于支持传统的图形渲染和通用GPU计算,代表了英伟达GPU的渲染和计算能力。
2) 张量核心用于加速深度学习神经网络的训练和推理,代表了英伟达GPU在人工智能领域的布局。
3) RT核心用于硬件级实时光线追踪,代表了英伟达在下一代图形技术上的探索。
这种多模态设计使得英伟达显卡不仅可以用于传统的图形渲染,也适用于人工智能、光线追踪等新兴工作负载,具有更强的前瞻性。
七、展望
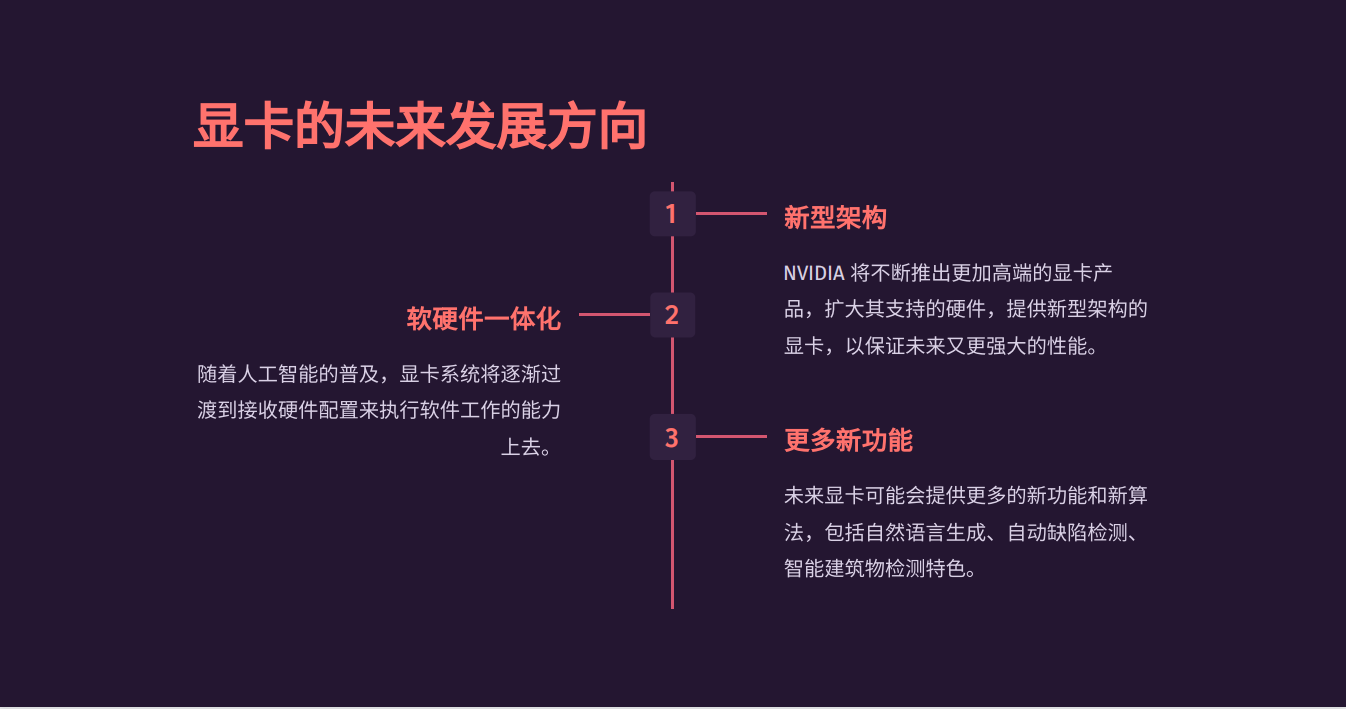
未来,英伟达显卡将继续在以下几个方向发展:
1) 改进体系结构,提高流处理器和张量核心的性能与功效。这将提高GPU在传统图形应用和人工智能上的计算能力。
2) 加强光线追踪技术,提供更强大的RT核心与程序支持。光线追踪将是下一代图形技术的重点,这将使英伟达保持在高质量图形渲染上的优势。
3) 加强人工智能技术,提供更丰富的深度学习库和工具支持。人工智能将是GPU发展的新方向,这有利于英伟达在数据中心和边缘计算市场的渗透。
4) 继续推动技术创新,在VR、AR和其他新兴图形技术上进行布局。这将有利于英伟达显卡继续保持在高端GPU市场的领先地位。
5) 加强及时的产品更新,推出新一代GPU架构和显卡产品。及时更新产品是显卡市场的重要规则,这将使英伟达显卡始终处于技术前沿。
综上,英伟达显卡将在体系结构、人工智能、光线追踪以及产品更新等方面不断创新,继续推动GPU技术发展,保持高端GPU市场的领先地位。本文从多个角度全面解析了英伟达显卡,希望能够为读者提供深入的认知。如有任何疑问或需求,欢迎与我讨论
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。