?MambaDFuse 出手就知道有没有 | 模态问题怎么办?特征融合怎么解?速度怎么变快?这就是标杆!
?MambaDFuse 出手就知道有没有 | 模态问题怎么办?特征融合怎么解?速度怎么变快?这就是标杆!


多模态图像融合(MMIF)旨在将来自不同模态的互补信息整合到单一的融合图像中,以全面地表征成像场景并促进下游视觉任务的完成。近年来,由于深度神经网络的进步,在MMIF任务上取得了显著的进展。 然而,现有方法受到固有的局部还原性偏差(CNN)或二次计算复杂度(Transformers)的限制,无法有效且高效地提取模态特定和模态融合特征。为了克服这个问题,作者提出了一个基于Mamba的双阶段融合(MambaDFuse)模型。 首先,设计了一个双 Level 特征提取器,通过从CNN和Mamba块中提取低 Level 和高 Level 特征来捕获单模态图像中的长距离特征。然后,提出了一个双阶段特征融合模块,以获取结合来自不同模态互补信息的融合特征。 它使用通道交换方法进行浅层融合,以及增强的多模态Mamba(M3)块进行深层融合。最后,融合图像重建模块利用特征提取的逆变换来生成融合结果。通过广泛的实验,作者的方法在红外-可见图像融合和医学图像融合中取得了有希望的融合效果。 此外,在统一的基准测试中,MambaDFuse在下游任务(如目标检测)上也展示了性能的改进。经过同行评审过程后,将提供带有预训练权重的代码。
1. Introduction
图像融合旨在从多个源图像中结合基本的信息表示,以生成高质量、内容丰富的融合图像。根据成像设备或成像设置的不同,图像融合可以分为多种类型,包括多模态图像融合(MMIF)、数字摄影图像融合和遥感图像融合。红外-可见光图像融合(IVF)和医学图像融合(MIF)是MMIF的两个典型任务,它们对来自所有传感器的跨模态特征进行建模和融合。特别是,红外传感器捕捉热辐射数据,突出显示显著目标,而可见光传感器捕捉反射光信息,生成富含纹理细节的数字图像。IVF旨在整合源图像中的互补信息,生成在突出显著目标的同时保留丰富纹理细节的高对比度融合图像。这些融合图像提供了增强的场景表示和视觉感知,有助于后续的实际视觉应用,如多模态显著性检测、目标检测和语义分割。
同样,在医学成像中,如计算机断层扫描(CT)和磁共振成像(MRI)的结构图像主要提供结构和解剖信息,而如正电子发射断层扫描(PET)和单光子发射计算机断层扫描(SPECT)的功能图像反映正常和病态组织的代谢活动以及脑血流量信号。MIF通过整合多种成像模态可以精确检测异常位置,从而协助诊断和治疗。
近年来,为应对多模态融合(MMF)的挑战,已经开发了众多方法。这些方法主要包括卷积神经网络(CNNs)和自动编码器(AEs),生成对抗网络(GANs),扩散模型,以及基于Transformer的方法。上述范式的最主要缺点是它们无法在MMF中同时实现高效和有效性。首先,基于CNN的方法由于其有限的感受野而难以捕捉全局上下文,这使得生成高质量融合图像变得具有挑战性。
此外,使用AE进行特征提取或图像重建时,设计一个能够捕捉特定模态和共享特征的编码器具有挑战性。其次,基于生成模型的方法虽然可以生成高质量的融合图像,但可能无法高效地完成融合任务。GANs存在训练不稳定和模式坍塌的问题,而扩散模型面临如训练时间长和采样率慢等挑战。最后,基于Transformer或Transformer与其他模型结合的方法在全球建模方面表现出色,但由于自注意力机制下资源与 Token 数量的二次增长,存在显著的计算开销。
改进型54(也被称作Mamba )的出现,凭借其选择机制和高效的硬件感知设计,为上述挑战提供了新的解决方案。Mamba已被证明在需要长期依赖建模的任务中,如自然语言处理,优于Transformers,这是由于它的输入自适应和全局信息建模能力,同时保持了线性复杂度,降低了计算成本,提高了推理速度。最近,Mamba的一些变体在计算机视觉任务中,如图像分类,医学图像分割等也显示出有希望的结果。然而,Mamba在MMIF任务中的作用尚未得到充分探索,因为Mamba缺乏类似于跨注意力设计。这促使作者研究如何利用Mamba在MMIF中整合多模态信息。
因此,作者提出了一个基于Mamba的双阶段多模态图像融合模型(MambaDFuse)。它包括三个阶段:双 Level 特征提取、双阶段特征融合和融合图像重建。层次特征提取包括卷积层和多个堆叠的Mamba块,利用CNN在视觉任务早期阶段的优秀处理能力以及Mamba在提取长距离特征上的效率。然后在特征融合阶段,浅层融合模块利用人工设计的融合规则来融合全局概览特征。
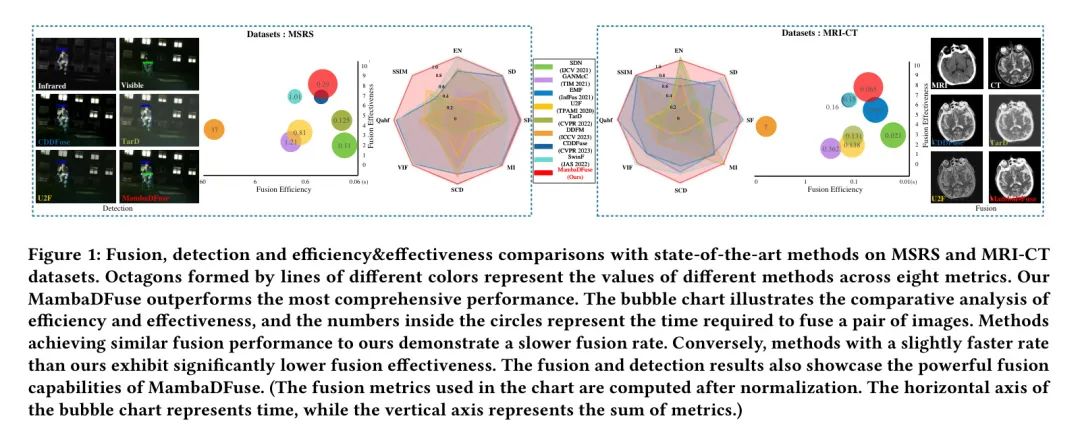
相比之下,深层融合模块使用改进的多模态Mamba(M3)块进行跨模态深度特征融合,以获得由各自模态特征引导的局部细节特征。最终,融合特征被用于重建融合图像。重建采用的损失函数是在(Zhu等人,2019年)中提出的,包括SSIM损失、纹理损失和强度损失,驱使网络在呈现最佳视觉强度的同时保留丰富的纹理细节和结构信息。图1显示,作者提出的MambaDFuse在主观视觉评估和客观评价指标方面优于现有技术水平。
作者的主要贡献可以总结如下:
- 据作者所知,MambaDFuse是首次将Mamba用于MMIF,它是CNN和Transformers的有效且高效的替代方案。
- 为了捕获具有长距离信息的低 Level 和高 Level 模态特定特征,作者设计了一个双 Level 特征提取器。这些特征包括显著物体、环境光照和纹理细节。
- 为了获得具有全局概览和局部细节信息的模态融合特征,作者提出了一个双阶段特征融合模块。具体来说,通道交换用于浅层融合,而M3块是为深层融合设计的。
- 作者的方法在IVF和MIF的图像融合性能方面取得了领先。作者还提供了一个统一的测量基准,以证明IVF融合图像如何有助于下游的目标检测。
2. Related Works
在本节中,作者回顾了与作者的方法密切相关的工作。作者将它们分为三个主要流派:
- 传统方法,
- 基于深度学习的方法,
- 其他相关方法。
Multi-Modality image fusion
基于深度学习的多模态图像融合研究利用了神经网络的强大拟合能力,实现了有效的特征提取和信息融合。根据模型的架构,现有方法可以分为三类:基于CNN和AE的方法、采用生成模型如GAN和扩散模型的方法以及利用Transformer(有些结合了CNN)的方法。
首先,对于基于CNN和AE的方法,典型的流程包括使用CNN或编码器进行特征提取,然后使用AE进行图像重建。利用上下文无关的CNN在提取全局信息以生成高质量融合图像方面的局限性导致了坚实的局部还原性偏见。因此,CNN是否足以从所有模态中提取特征还有待观察。此外,编码器设计需要仔细考虑。共享编码器可能无法区分模态特定的特征,而使用单独的编码器可能会忽视模态间共享的特征。
其次,对于基于生成模型的方法,GAN将图像融合问题建模为一个生成器和一个判别器之间的对抗游戏,使用对抗性训练生成与源图像具有相同分布的融合图像。然而,训练不稳定、缺乏可解释性以及模式坍塌一直是影响GAN生成能力的关键问题。此外,由扩散和逆扩散阶段组成的扩散模型在图像生成方面取得了显著的成功。
最后,基于Transformer或CNN-Transformer 的方法由于其强大的长距离依赖建模能力而显示出有希望的结果。Transformer及其变体用于特征提取、融合和图像重建。然而,与自注意力机制相关的二次时间复杂度和计算资源消耗使得它们在多模态图像融合任务上效率低下。即使像(Wang等人,2017)这样使用移位窗口注意力来提高性能的方法,也牺牲了长期依赖关系,并且从根本上未能解决二次复杂性问题。
总之,图像融合作为高级视觉任务的前处理步骤,需要实时处理和强大的融合能力。然而,现有方法尚未实现有效和高效的图像融合性能。因此,迫切需要一个新的架构来推动多模态图像融合(MMIF)的进展和发展。
State Space Models (SSMs)
状态空间模型(SSM),起源于经典控制理论,由于在分析连续长序列数据方面的卓越性能,已成为构建深度网络的实用组件。结构化状态空间序列模型(S4)是状态空间模型在建模长距离依赖方面的开创性工作。随后,基于S4的S5层被提出,它在一个对角化线性SSM上进行并行扫描。H3模型进一步改进并扩展了这项工作,使模型能够与Transformer在语言建模任务中取得可比的结果。
一项名为Mamba的最新研究通过引入选择机制进一步改进了S4,使模型能够根据输入有选择地选择相关信息。同时,还提出了一个硬件感知算法以实现高效的训练和推理。与同等规模的Transformer模型相比,Mamba展现出更高的推理速度、吞吐量和整体性能。随后,许多研究将Mamba从自然语言处理(NLP)扩展到其他领域。
视觉Mamba 将Mamba应用于Vision Transformer(ViT)架构,提出了一种基于双向Mamba块的新型通用视觉 Backbone 网络。这个 Backbone 网络将位置嵌入到图像序列中,并通过双向状态空间模型压缩视觉表示。视觉状态空间模型(Vamba)引入了跨扫描机制来弥合一维数组扫描和二维平面遍历之间的差距。在医学图像分割任务中,也应用了Mamba,取得了有希望的结果。由于Mamba缺乏像跨注意力这样的机制来促进多模态信息的融合,研究在MMIF中有效利用Mamba是值得探讨的。
总之,与(Wang等人,2017)等类似工作一样,MambaDFuse包括特征提取、特征融合和图像重建。然而,作者的方法与众不同的地方在于利用并增强了Mamba块。具体来说,作者设计了一个双 Level 特征提取器、一个M3块和一个针对MMIF的双阶段特征融合模块。通过这样的设计,MambaDFuse可以成为MMIF中的一个强大工具。
3. Method
方法部分描述了作者在研究中采用的方法和技术。作者首先概述了数据集以及涉及到的预处理步骤。随后,作者详细说明了神经网络的架构和训练过程,接着是用于评估作者模型性能的评价指标
Overall Architecture
提出的MambaDFuse可以分为三个功能组件:双级特征提取器、双阶段特征融合模块和融合图像重建模块。详细的工作流程如图2所示。作者的流程可以描述如下:
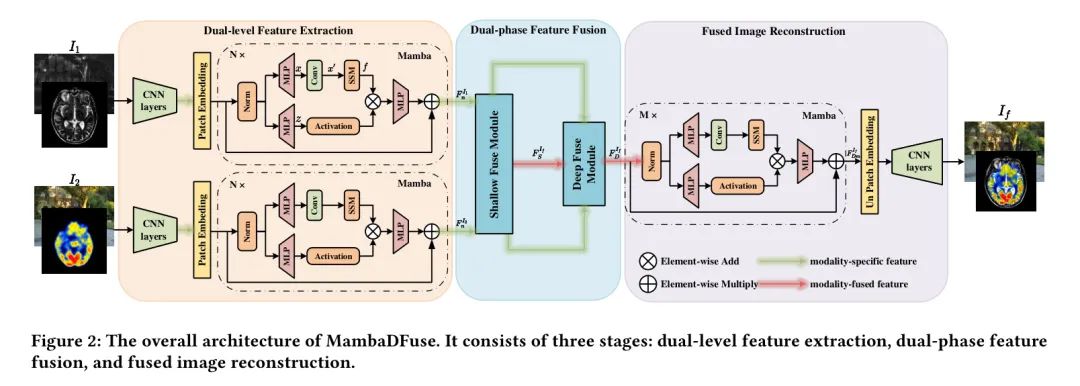
Dual-level Feature Extraction
低级特征提取。 卷积层在早期视觉处理中表现出色,提高了优化稳定性和优秀的结果(Wang等人,2017年)。此外,它们提供了一种简单而高效的方法来捕捉局部语义细节并将它们投影到高维特征空间中。低级特征提取包括两个使用Leaky ReLU激活函数的卷积层,每个卷积层的核大小为3*3,步长为1。
高级特征提取。 当提取特征时,CNN受到局部感受野的限制,而Transformers也遇到二次复杂度的问题。考虑到这一点,mambo块是进一步提取高级特定模态特征的理想选择。输入特征序列 首先进行层归一化以获得 。
然后,在两个独立的分支上, 通过两个多层感知机(MLP)投影到 和 。在第一个分支上,经过卷积和SiLU激活以获得 。随后, 经过状态空间模型(方程3和4)来计算 。在另一个分支上, 通过SiLU激活函数,作为门控因子门控 ,得到 。最后,经过MLP层和残差连接后,得到高级特征提取的输出 。详细过程如算法1所示。

Dual-phase Feature Fusion
实用的融合特征应该包含显著物体、环境光照和纹理细节等重要的信息。
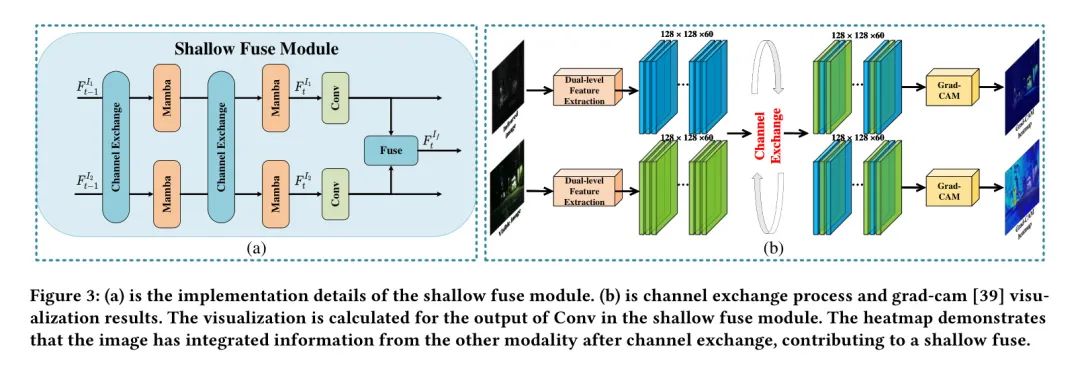
在第一阶段,可以通过手动设计的融合规则快速产生初始融合特征(如图3(a)所示)。然而,由于其无法适应更复杂的融合场景,在第二阶段使用了增强的Mamba M3块(如图4所示)来融合深层纹理细节特征。
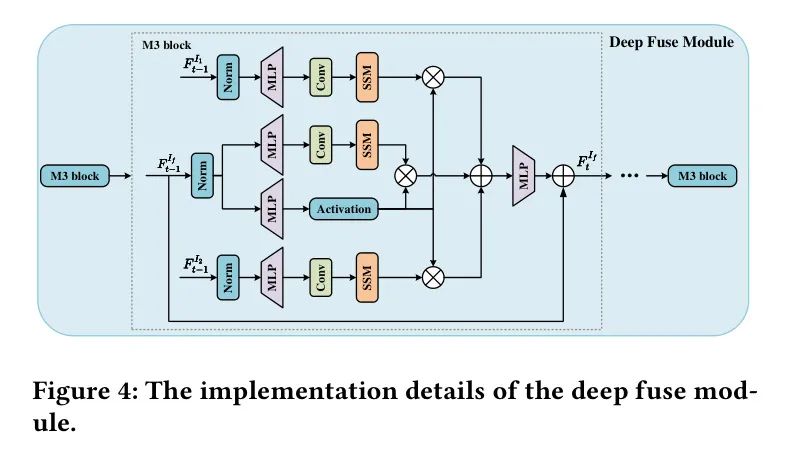
深融合模块。 当前的Mamba架构由于缺乏类似交叉注意力的机制,不能直接处理多模态图像信息。作为改进,作者设计了一个多模态Mamba(M3)块。它利用模态特定特征指导模态融合特征的生成,旨在从不同模态中融入局部细节特征,受(Han等人,2017年)的启发。输入是来自浅融合模块的初始融合特征。此外,引入了两个额外的分支,每个分支都接收来自不同模态的特征作为输入。同样,这些分支经过层归一化、卷积、SiLU激活和参数离散化,并通过SSM获得输出。经过门控因子的调制后,它被加到原始分支的输出上,从而产生最终的融合特征。具体细节请参考算法2。一系列M3块构成了深融合模块。

实现细节。 实验使用了两块NVIDIA GeForce RTX 4090 GPU。采用批大小为12,每个融合任务进行10,000个训练步骤。在每步中,训练集中的图像被随机裁剪成128 大小的块,随后被归一化到[0, 1]的范围内。MambaDFuse的参数使用Adam优化器进行优化。损失函数与SwinFusion中使用的相似。
对于RGB输入。 作者采用了与先前工作相同的处理方法。首先,将RGB图像转换到YCbCr颜色空间,其中Y通道代表亮度通道,而Cb和Cr通道代表色度。仅使用Y通道进行融合。随后,通过逆映射将融合后的Y、Cb和Cr通道转换回RGB颜色空间。
Comparison with SOTA methods
在本节中,将MambaDFuse与现有技术水平的方法进行了比较,包括基于CNN和AE的方法组:SDN [54],EMF [46],U2F [47];生成方法组:GANMcC [30],TarD [21],DDFM [57];以及基于Transformer的方法组:CDDFuse [56],SwinF [26]。其中,EMF是专为MIF任务设计的架构,因此在IVF任务中不进行比较。
定量比较。采用了八种指标来定量比较上述结果,这些指标显示在表1和表2中。
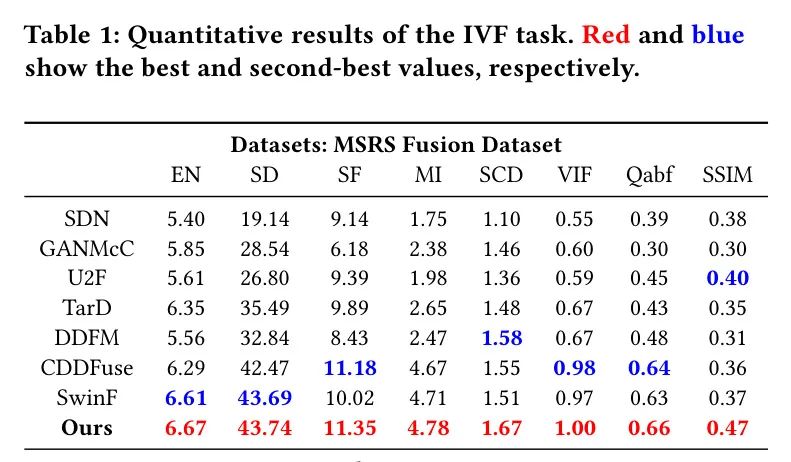
MambaDFuse在几乎所有指标上都表现出色,证实了其适用于各种光照条件和目标类别。在作者的方法的成果中,MI、Qabf和SSIM的较高值表明,源图像传输到融合图像的信息量很大,且失真最小。更好的SD表明MambaDFuse在对比度方面有所改进。同时,SF的优异表现也意味着边缘和纹理细节更加丰富。改进的VIF进一步证实了其能力与人类视觉感知相一致。
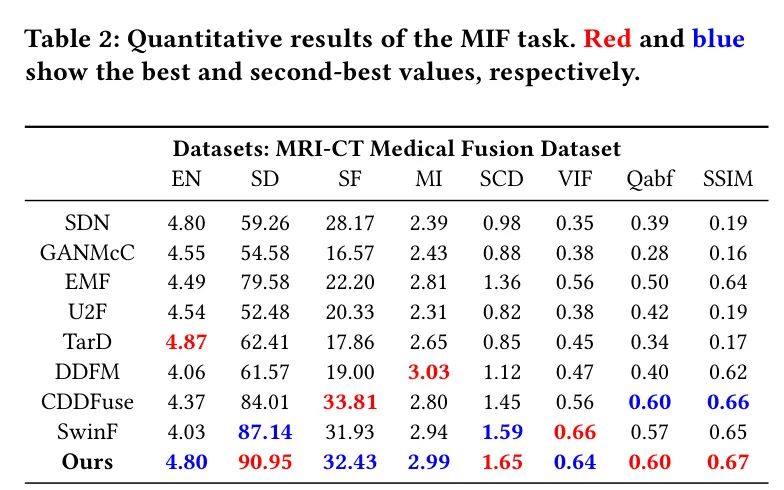
定性比较。随后,作者在图5、6和7中展示了定性比较。MambaDFuse有效地将红外图像中的热辐射信息与可见图像中的详细纹理和光照信息相结合。因此,位于昏暗环境中的物体被显著突出,使得前景物体容易区分。


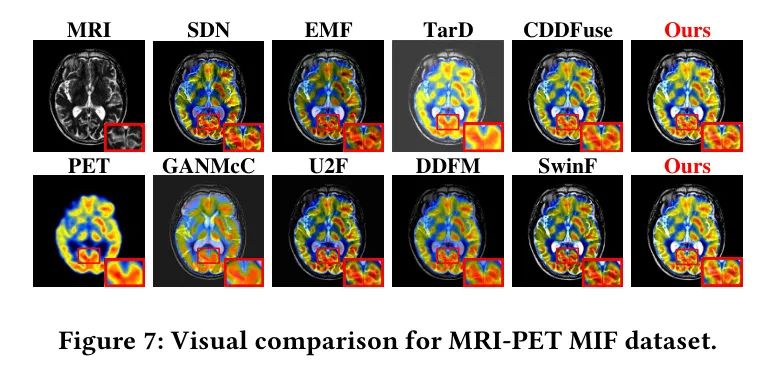
Ablation Study
进行了消融实验来验证不同设计和模块的合理性。使用EN、SD、VIF、MI、VIF和Qabf来定量验证融合效果。实验组的结果展示在表3中。
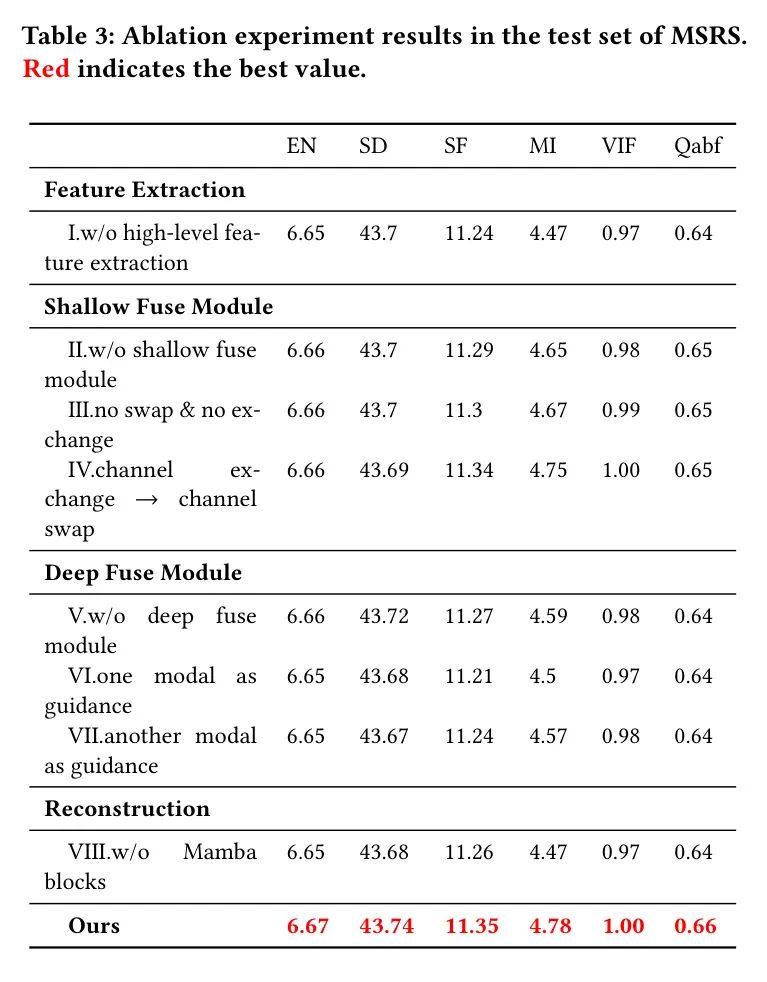
作者在三个阶段进行了消融实验:特征提取、特征融合和融合图像重建。在特征提取阶段,验证了高级特征提取的有效性。在特征融合阶段,通过分别移除浅层和深层融合模块进行了实验。结果显示,在两种情况下性能都有所下降,
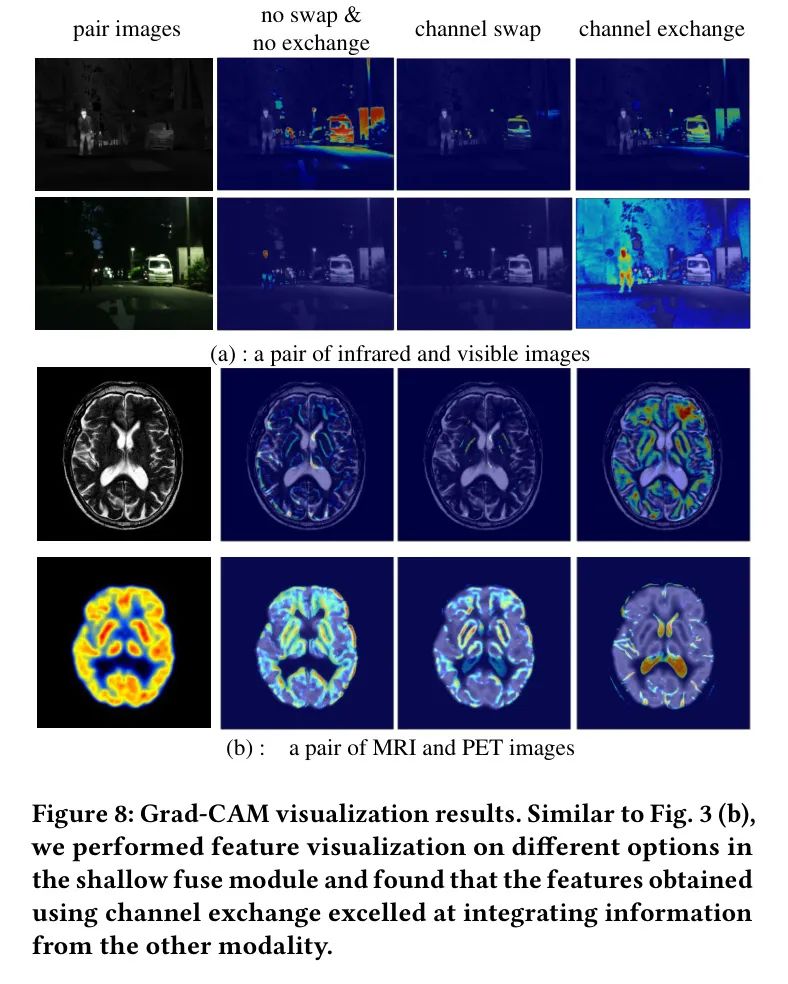
证明了特征融合两个阶段的必要性。此外,在浅层融合模块中,作者研究了使用通道交换、通道交换进行特征交换或两者都不使用的选择。图8可视化了特征,证实了模块中通道交换的有效性。在深层融合模块中,作者消除了M3块中的引导选择,并发现只有当两种模态都用于引导时,才能达到最佳指标。最后,在融合图像重建中,通过移除Mamba块进行了消融实验,证实了设计原理的合理性。
Downstream IVF applications
MMF的目的是为了促进进一步的视觉任务应用,如目标检测、语义分割等。因此,为了确定一种方法的有效性,融合后的图像应该在下游任务中使用,以评估它们是否对这些任务有积极的贡献。在作者的工作中,采用了IVF图像融合进行目标检测。从MSRS数据集中选择了80对红外图像和可见光图像,主要标注了人和汽车。所有融合后的图像以及原始的红外和可见光图像,都使用预训练的YOLOv5模型(Redmon等人,2016年)(在COCO数据集上训练)进行目标检测。
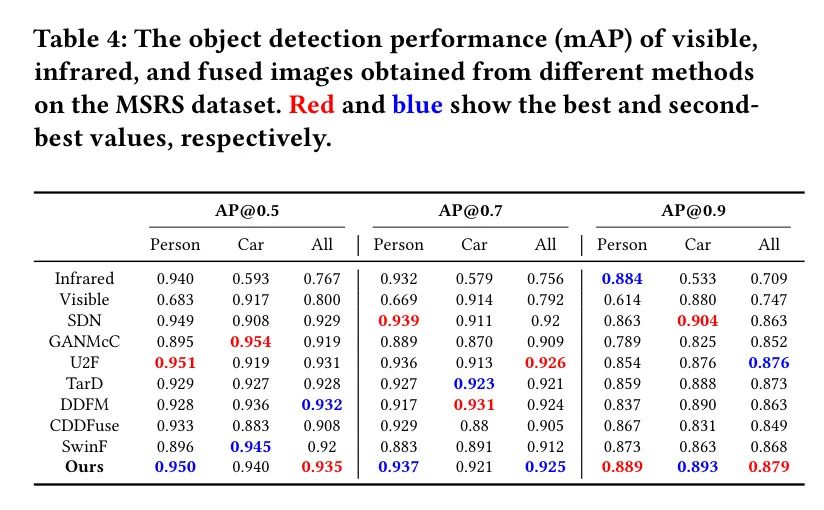
表4展示了平均精度(mAP),其中AP(\varnothing0.5, AP@0.7和AP@0.9分别表示IoU阈值为0.5、0.7和0.9时的AP值。观察到可见光图像和红外图像单独提供的信息有限。例如,目标检测器在可见光图像中更容易检测到汽车,在红外图像中更容易检测到人。然而,作者的融合图像相互补充,提供了更全面的场景描述,使得检测人和汽车都更加容易,没有任何缺点。在比较的多种融合方法中,MambaDFuse展示了最佳的检测性能。图9还提供了一个可视化的例子。

5. Conclusion
在本文中,作者首次探索了Mamba在多模态图像融合中的潜力,提出了一个基于Mamba的高效且有效的双阶段模型,并设计了一个多模态Mamba(M3)块。一方面,双 Level 特征提取提高了模态特定特征的提取。另一方面,双阶段特征融合模块促进了综合且互补的模态融合特征的产生。广泛的实验表明,MambaDFuse可以取得有希望的融合结果,并提高下游任务(如目标检测)的准确性。
参考
[1].MambaDFuse: A Mamba-based Dual-phase Model for Multi-modality Image Fusion.