LSTM依然能打!最新xLSTM架构:怒超先进Transformer和状态空间模型(SSM)
LSTM依然能打!最新xLSTM架构:怒超先进Transformer和状态空间模型(SSM)

引言
LSTM( Long Short-Term Memory)最早源于20世纪90年代,为人工智能的发展做出了重要贡献。然而,随着Transformer技术的出现,LSTM逐渐淡出了人们的视野。那么,如果将 LSTM 扩展到数十亿个参数,利用LLM技术打破LSTM的局限性,LSTM在语言建模方面还能走多远呢?
基于这个问题,本文作者提出xLSTM架构,与最先进的 Transformer 和状态空间模型(SSM)相比,在性能还是扩展方面都得到了显著的提升。LSTM迎来第二春?

https://arxiv.org/pdf/2405.04517
背景介绍
长短期记忆网络(Long Short-Term Memory, LSTM)的基本概念和它在深度学习中的重要作用。LSTM是一种特殊的循环神经网络(Recurrent Neural Network, RNN),它通过引入常量误差旋转CEC(Constant Rrror Carousel,CEC)和门控机制(Gating)来解决传统RNN中的梯度消失问题。
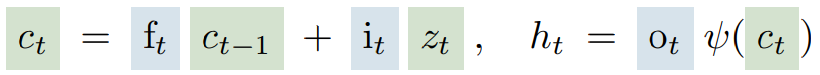
CEC是单元状态
(绿色)通过加上由输入门
控制的输入
来进行更新,这个过程由sigmoid门控(通常表示为蓝色)调节,确保更新是适度的。输入门
决定新信息的流入,而遗忘门
决定旧信息的保留或遗忘。输出门
控制着记忆单元的输出,即隐藏状态
,它决定了单元状态如何影响网络的下一步输出。通过激活函数
(通常是双曲正切函数tanh),单元状态被规范化或压缩到一个较小的范围内,以保持数值的稳定性。
长短期记忆网络(LSTM)自从1990年代被提出后,在多个领域取得了显著的成功,并在Transformer模型(2017年)出现之前,一直是文本生成等序列任务的主导技术。LSTM在各种序列处理任务中展现了其强大的能力,包括文本生成、手写模拟、序列到序列翻译、计算机程序评估、图像字幕生成、源代码生成、降雨-径流模拟、洪水预警水文模型等。
特别在强化学习领域,LSTM表现卓越,例如Dota 2中的OpenAI Five模型,以及核聚变磁控制器模型。LSTM之所以在这些任务中表现出色,归功于其在抽象学习方面的能力,能够有效提取和存储语义信息。例如,通过LSTM可以观察到数字、句法、语言和情感神经元的活动。尽管Transformer模型在规模化和并行处理方面具有优势,但LSTM仍然在许多重要应用中发挥着作用,并持续展现出其时间考验的价值。
长短期记忆网络(LSTM)在处理序列数据方面虽然取得了巨大成功,但它们面临三个主要的局限性。首先,LSTM在处理最近邻搜索问题时难以修订其存储决策,这限制了其在动态更新信息方面的能力。其次,LSTM的存储容量有限,这导致它在处理稀有标记预测任务时表现不佳,因为信息必须被压缩进标量单元状态中。最后,由于隐藏状态之间的连接,LSTM缺乏并行处理的能力,这影响了其在大规模数据处理中的效率。
为了克服这些限制,文章提出了xLSTM模型,它引入了指数门控和矩阵记忆等新技术,以提升LSTM的性能,使其在语言建模等任务中能够与Transformer等先进技术相媲美。
xLSTM
xLSTM(Extended Long Short-Term Memory)是对传统LSTM的一种扩展,旨在解决LSTM在处理大模型时遇到的一些限制,如下图所示:
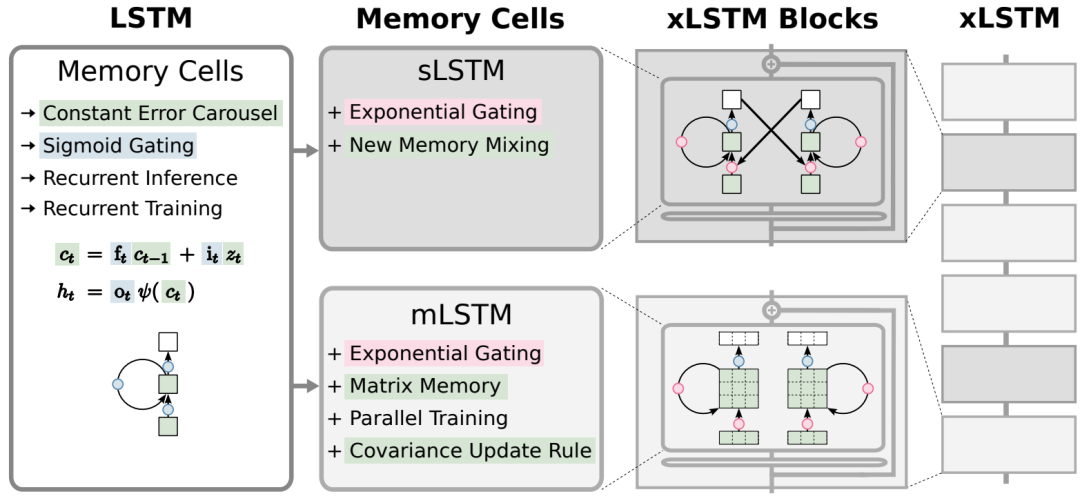
xLSTM通过引入两个主要的改进来增强LSTM的能力:1)引入指数门控;2)引入新型记忆结构
「1)指数门控(Exponential Gating)」:这是对LSTM中传统门控机制的一种改进,允许模型更有效地更新其内部状态。指数门控通过引入适当的归一化和稳定技术,使得LSTM能够更好地处理信息流,特别是在需要修订存储决策的场景中。
「2)新型记忆结构」:xLSTM引入了两种新的记忆单元,分别是:「sLSTM、mLSTM」
- 「sLSTM(Scalar LSTM)」:具有标量记忆和更新机制,以及新的记忆混合技术。sLSTM通过引入多个头(heads)和在每个头内部的记忆混合,但不跨越头之间,从而提供了一种新的记忆混合方式。
- 「mLSTM(Matrix LSTM)」:使用矩阵记忆和协方差(covariance)更新规则,完全可并行化。mLSTM通过矩阵乘法来增强存储容量,解决了LSTM在处理稀有标记预测时的局限性。这两种新的记忆单元都通过指数门控来增强LSTM的功能。此外,mLSTM放弃了记忆混合,从而实现了并行化处理,而sLSTM则保留了记忆混合,但通过引入头部来形成新的记忆混合方式。
xLSTM的架构通过将这些新变体(sLSTM、mLSTM)集成到残差块模块中,形成了xLSTM块,然后将这些块以残差堆叠的方式构建成完整的xLSTM架构。这种架构不仅提高了性能,还在规模化方面与现有的Transformer和状态空间模型相比具有优势。
实验结果
下表在Long Range Arena基准上的实验结果,旨在评估了模型处理长序列的能力。可以发现xLSTM在所有测试任务上均表现出色,显示了其在处理长上下文问题方面的高效性。

下表展示了,在SlimPajama(300B)数据集上,不同模型尺寸的xLSTM与其他模型在验证集困惑度和下游任务性能上的比较。可以发现xLSTM在不同模型尺寸下,在验证集上的困惑度最低,证明了其在语言建模任务上的优势。
