

Hadoop文件格式初学者指南
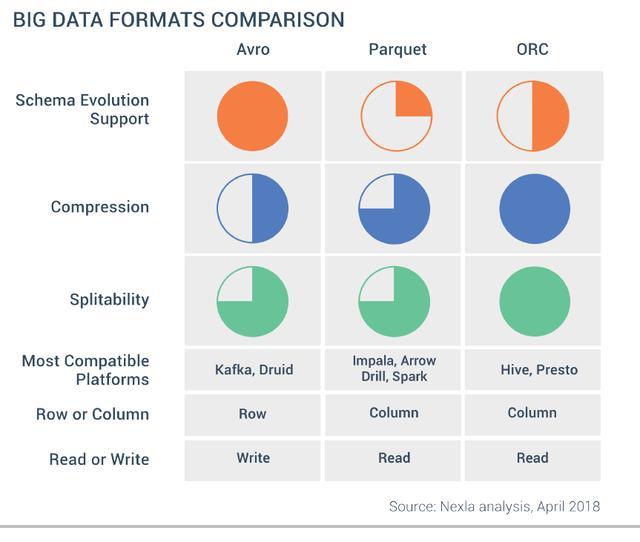
几周前,我写了一篇有关Hadoop的文章,并谈到了它的不同部分。 以及它如何在数据工程中扮演重要角色。 在本文中,我将总结Hadoop中不同的文件格式。 本主题将是一个简短而快速的主题。 如果您想了解Hadoop的工作原理以及它在数据工程师中的重要作用,请在此处访问我关于Hadoop的文章,或乐于跳过。
Hadoop中的文件格式大致分为两类:面向行和面向列:


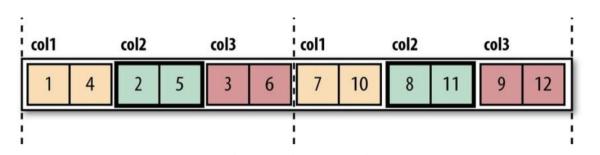
如果仍不清楚行和列的方向,请不用担心,您可以访问此链接,了解它们之间的区别。
以下是在Hadoop系统上广泛使用的一些相关文件格式:
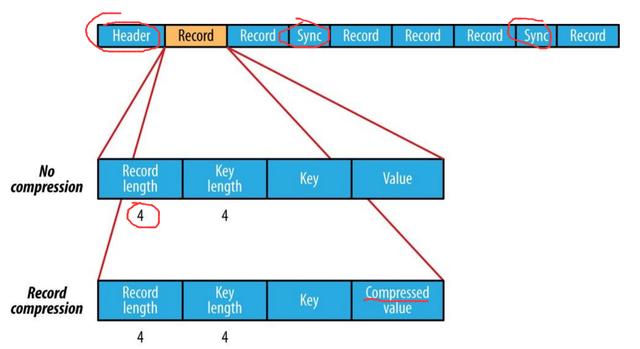
序列文件
存储格式取决于是否压缩以及使用记录压缩还是块压缩而有所不同:

地图文件
MapFile是SequenceFile的变体。 将索引添加到SequenceFile并对其进行排序后,它就是MapFile。 索引存储为单独的文件,通常每128条记录存储一个索引。 可以将索引加载到内存中以进行快速查找-存储按Key定义的顺序排列的数据的文件。 MapFile记录必须按顺序编写。 否则,将引发IOException。
MapFile的派生类型:
Hadoop系统下面列出的文件包括RCFile,ORCFile和Parquet。 Avro的面向列的版本是Trevni。
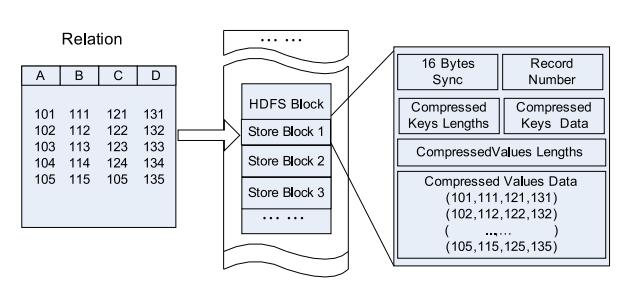
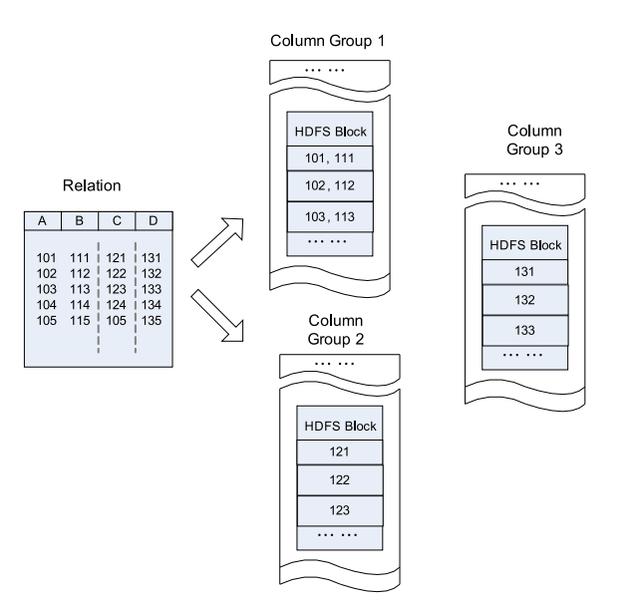
RC文件
Hive的Record Columnar File(记录列文件),这种类型的文件首先将数据按行划分为行组,然后在行组内部将数据存储在列中。 其结构如下:

与纯面向行和面向列的比较:
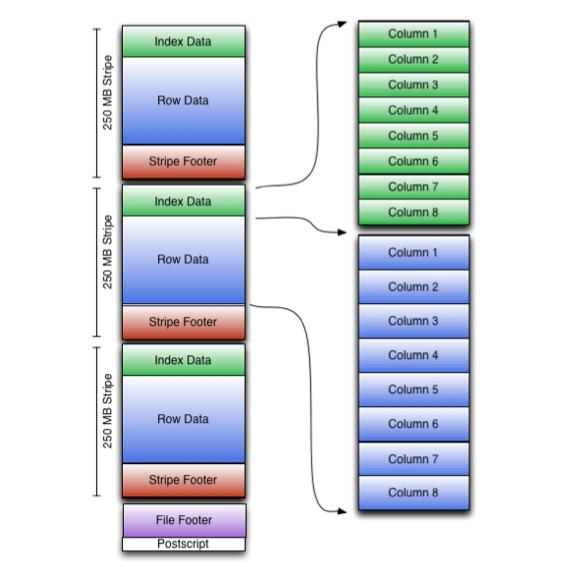
ORC文件
ORCFile(优化的记录列文件)提供了比RCFile更有效的文件格式。 它在内部将数据划分为默认大小为250M的Stripe。 每个条带均包含索引,数据和页脚。 索引存储每列的最大值和最小值以及列中每一行的位置。
在Hive中,以下命令用于使用ORCFile:
CREATE TABLE ...STORED AAS ORC ALTER TABLE ... SET FILEFORMAT ORC SET hive.default.fileformat=ORC
Parquet
一种通用的基于列的存储格式,基于Google的Dremel。 特别擅长处理深度嵌套的数据。
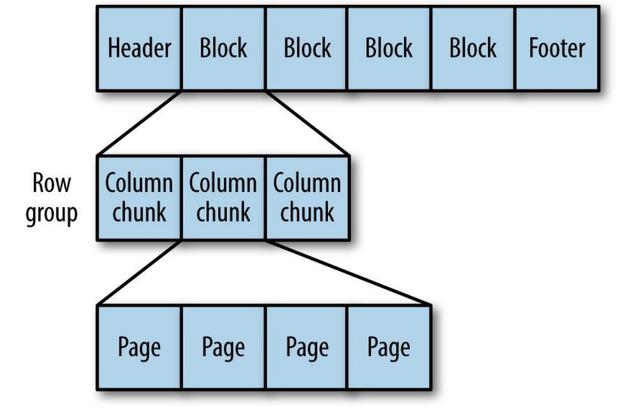
对于嵌套结构,Parquet会将其转换为平面列存储,该存储由重复级别和定义级别(R和D)表示,并在读取数据以重建整个文件时使用元数据来重建记录。 结构体。 以下是R和D的示例:
AddressBook { contacts: { phoneNumber: "555 987 6543" } contacts: { } } AddressBook { }

就这样,现在,您知道了Hadoop中不同的文件格式。 如果您发现任何错误并提出建议,请随时与我联系。 您可以在我的LinkedIn上与我联系。

近几年,互联网行业蓬勃发展,在互联网浪潮的冲击下,互联网创业已成为一种比较...
在Python开发过程中,我们难免会遇到多重条件判断的情况的情况,此时除了用很多...
背景 我们知道 如果在Kubernetes中支持GPU设备调度 需要做如下的工作 节点上安装...
本文转载自微信公众号「bugstack虫洞栈」,作者小傅哥 。转载本文请联系bugstack...
基本介绍 给定 n 个权值作为 n 个叶子节点,构造一颗二叉树,若该树的带权路径长...
前言 统计科学家使用交互式的统计工具(比如R)来回答数据中的问题,获得全景的认...
想了解更多内容,请访问: 51CTO和华为官方战略合作共建的鸿蒙技术社区 https://...
溢价 域名 的续费价格如何?通常来说,因为溢价域名的价值高于普通域名,所以溢...
本文转载自公众号读芯术(ID:AI_Discovery)。 这一刻你正在应对什么挑战?这位前...
TIOBE 公布了 2021 年 3 月的编程语言排行榜。 本月 TIOBE 指数没有什么有趣的变...

