

读时模式和写时模式
Hive使用Hadoop来执行查询,其查询执行速度是很慢的,但是使用load data向Hive中导入数据却非常快,这是因为Hive采取的是读时模式(Schema On Read)。
将数据存到Hive的数据表时,Hive采用的是“读时模式”,意思是针对写操作不会做任何校验,只是简单的将文件复制到Hive的表对应的HDFS目录。跟“读时模式”相对应的是“写时模式”,RDBMS一般采用“写时模式”,在将数据写入到数据表的时候会检查每一条记录是否合法,如果检查不通过会直接返回失败信息。
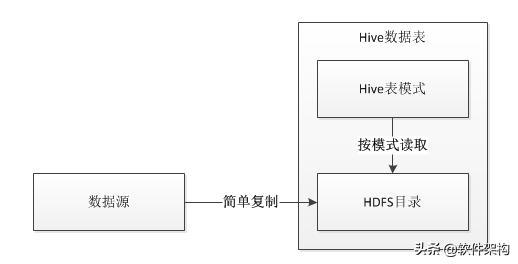
由于向Hive中存入数据的只是简单的文件复制和粘贴,所以导入数据速度非常的快。当读取、查询的时候,才会根据表模式来解释数据,这个时候如果遇到了不符合模式的数据,Hive会直接将数据解析成NULL。
读时模式的好处
Hive采用读时模式带来了以下几个好处:
导入数据
- hive> load data local inpath '/root/usr.data' into table usr;


本文转载自微信公众号「bugstack虫洞栈」,作者小傅哥 。转载本文请联系bugstack...
近几年,互联网行业蓬勃发展,在互联网浪潮的冲击下,互联网创业已成为一种比较...
TIOBE 公布了 2021 年 3 月的编程语言排行榜。 本月 TIOBE 指数没有什么有趣的变...
本文转载自公众号读芯术(ID:AI_Discovery)。 这一刻你正在应对什么挑战?这位前...
基本介绍 给定 n 个权值作为 n 个叶子节点,构造一颗二叉树,若该树的带权路径长...
在Python开发过程中,我们难免会遇到多重条件判断的情况的情况,此时除了用很多...
前言 统计科学家使用交互式的统计工具(比如R)来回答数据中的问题,获得全景的认...
想了解更多内容,请访问: 51CTO和华为官方战略合作共建的鸿蒙技术社区 https://...
溢价 域名 的续费价格如何?通常来说,因为溢价域名的价值高于普通域名,所以溢...
背景 我们知道 如果在Kubernetes中支持GPU设备调度 需要做如下的工作 节点上安装...

