


一、前言
今天我要给大家分享的是如何爬取中农网产品报价数据,并分别用普通的单线程、多线程和协程来爬取,从而对比单线程、多线程和协程在网络爬虫中的性能。
目标URL:https://www.zhongnongwang.com/quote/product-htm-page-1.html
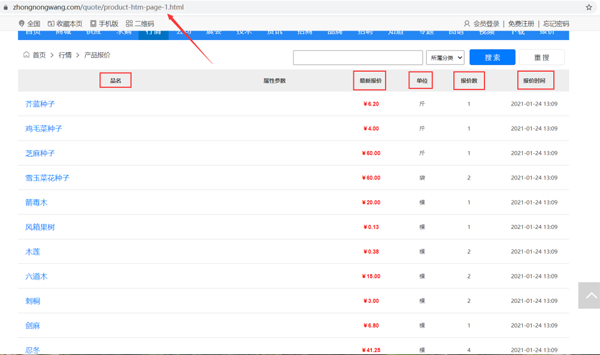
爬取产品品名、最新报价、单位、报价数、报价时间等信息,保存到本地Excel。
二、爬取测试
翻页查看 URL 变化规律:
- https://www.zhongnongwang.com/quote/product-htm-page-1.html
- https://www.zhongnongwang.com/quote/product-htm-page-2.html
- https://www.zhongnongwang.com/quote/product-htm-page-3.html
- https://www.zhongnongwang.com/quote/product-htm-page-4.html
- https://www.zhongnongwang.com/quote/product-htm-page-5.html
- https://www.zhongnongwang.com/quote/product-htm-page-6.html
检查网页,可以发现网页结构简单,容易解析和提取数据。
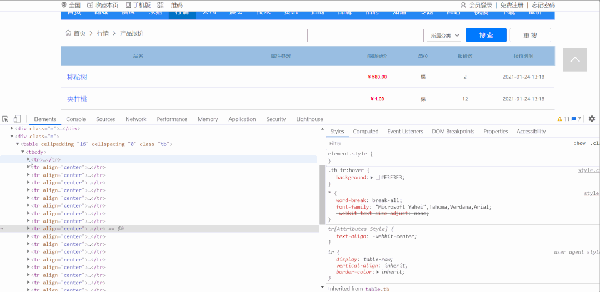
思路:每一条产品报价信息在 class 为 tb 的 table 标签下的 tbody 下的 tr 标签里,获取到所有 tr 标签的内容,然后遍历,从中提取出每一个产品品名、最新报价、单位、报价数、报价时间等信息。
- # -*- coding: UTF-8 -*-
- """
- @File :demo.py
- @Author :叶庭云
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- import logging
- from fake_useragent import UserAgent
- from lxml import etree
- # 日志输出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- url = 'https://www.zhongnongwang.com/quote/product-htm-page-1.html'
- # 伪装请求头
- headers = {
- "Accept-Encoding": "gzip", # 使用gzip压缩传输数据让访问更快
- "User-Agent": ua.random
- }
- # 发送请求 获取响应
- rep = requests.get(url, headersheaders=headers)
- print(rep.status_code) # 200
- # Xpath定位提取数据
- html = etree.HTML(rep.text)
- items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
- logging.info(f'该页有多少条信息:{len(items)}') # 一页有20条信息
- # 遍历提取出数据
- for item in items:
- name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
- price = ''.join(item.xpath('.//td[3]/text()')) # 最新报价
- unit = ''.join(item.xpath('.//td[4]/text()')) # 单位
- nums = ''.join(item.xpath('.//td[5]/text()')) # 报价数
- time_ = ''.join(item.xpath('.//td[6]/text()')) # 报价时间
- logging.info([name, price, unit, nums, time_])
运行结果如下:
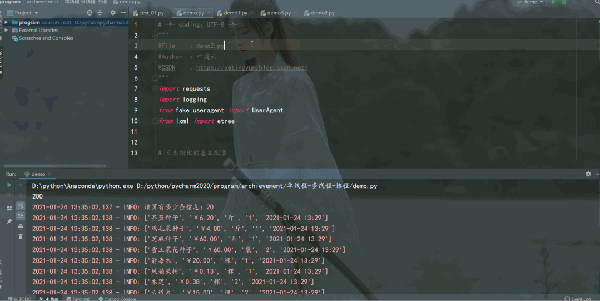
可以成功爬取到数据,接下来分别用普通的单线程、多线程和协程来爬取 50 页的数据、保存到Excel。
三、单线程爬虫
- # -*- coding: UTF-8 -*-
- """
- @File :单线程.py
- @Author :叶庭云
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- import logging
- from fake_useragent import UserAgent
- from lxml import etree
- import openpyxl
- from datetime import datetime
- # 日志输出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook()
- sheet = wb.active
- sheet.append(['品名', '最新报价', '单位', '报价数', '报价时间'])
- start = datetime.now()
- for page in range(1, 51):
- # 构造URL
- url = f'https://www.zhongnongwang.com/quote/product-htm-page-{page}.html'
- # 伪装请求头
- headers = {
- "Accept-Encoding": "gzip", # 使用gzip压缩传输数据让访问更快
- "User-Agent": ua.random
- }
- # 发送请求 获取响应
- rep = requests.get(url, headersheaders=headers)
- # print(rep.status_code)
- # Xpath定位提取数据
- html = etree.HTML(rep.text)
- items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
- logging.info(f'该页有多少条信息:{len(items)}') # 一页有20条信息
- # 遍历提取出数据
- for item in items:
- name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
- price = ''.join(item.xpath('.//td[3]/text()')) # 最新报价
- unit = ''.join(item.xpath('.//td[4]/text()')) # 单位
- nums = ''.join(item.xpath('.//td[5]/text()')) # 报价数
- time_ = ''.join(item.xpath('.//td[6]/text()')) # 报价时间
- sheet.append([name, price, unit, nums, time_])
- logging.info([name, price, unit, nums, time_])
- wb.save(filename='data1.xlsx')
- delta = (datetime.now() - start).total_seconds()
- logging.info(f'用时:{delta}s')
运行结果如下:
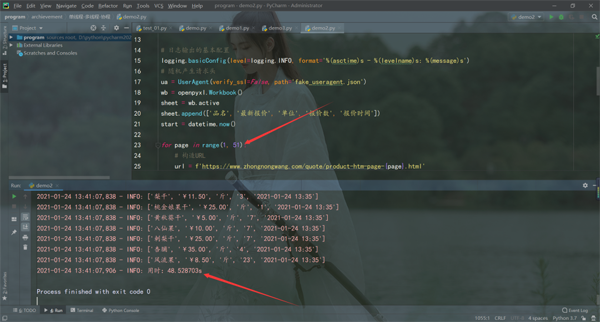
单线程爬虫必须上一个页面爬取完成才能继续爬取,还可能受当时网络状态影响,用时48.528703s,才将数据爬取完,速度比较慢。
四、多线程爬虫
- # -*- coding: UTF-8 -*-
- """
- @File :多线程.py
- @Author :叶庭云
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import requests
- import logging
- from fake_useragent import UserAgent
- from lxml import etree
- import openpyxl
- from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
- from datetime import datetime
- # 日志输出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook()
- sheet = wb.active
- sheet.append(['品名', '最新报价', '单位', '报价数', '报价时间'])
- start = datetime.now()
- def get_data(page):
- # 构造URL
- url = f'https://www.zhongnongwang.com/quote/product-htm-page-{page}.html'
- # 伪装请求头
- headers = {
- "Accept-Encoding": "gzip", # 使用gzip压缩传输数据让访问更快
- "User-Agent": ua.random
- }
- # 发送请求 获取响应
- rep = requests.get(url, headersheaders=headers)
- # print(rep.status_code)
- # Xpath定位提取数据
- html = etree.HTML(rep.text)
- items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
- logging.info(f'该页有多少条信息:{len(items)}') # 一页有20条信息
- # 遍历提取出数据
- for item in items:
- name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
- price = ''.join(item.xpath('.//td[3]/text()')) # 最新报价
- unit = ''.join(item.xpath('.//td[4]/text()')) # 单位
- nums = ''.join(item.xpath('.//td[5]/text()')) # 报价数
- time_ = ''.join(item.xpath('.//td[6]/text()')) # 报价时间
- sheet.append([name, price, unit, nums, time_])
- logging.info([name, price, unit, nums, time_])
- def run():
- # 爬取1-50页
- with ThreadPoolExecutor(max_workers=6) as executor:
- future_tasks = [executor.submit(get_data, i) for i in range(1, 51)]
- wait(future_tasks, return_when=ALL_COMPLETED)
- wb.save(filename='data2.xlsx')
- delta = (datetime.now() - start).total_seconds()
- print(f'用时:{delta}s')
- run()
运行结果如下:
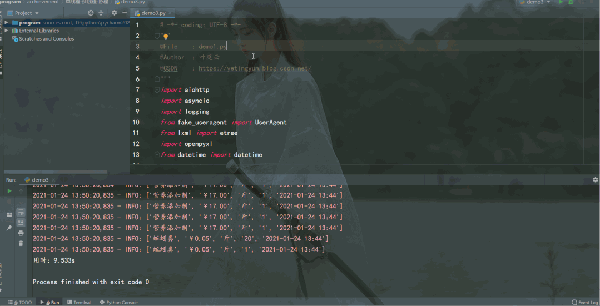
多线程爬虫爬取效率提升非常可观,用时 2.648128s,爬取速度很快。
五、异步协程爬虫
- # -*- coding: UTF-8 -*-
- """
- @File :demo1.py
- @Author :叶庭云
- @CSDN :https://yetingyun.blog.csdn.net/
- """
- import aiohttp
- import asyncio
- import logging
- from fake_useragent import UserAgent
- from lxml import etree
- import openpyxl
- from datetime import datetime
- # 日志输出的基本配置
- logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
- # 随机产生请求头
- ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
- wb = openpyxl.Workbook()
- sheet = wb.active
- sheet.append(['品名', '最新报价', '单位', '报价数', '报价时间'])
- start = datetime.now()
- class Spider(object):
- def __init__(self):
- # self.semaphore = asyncio.Semaphore(6) # 信号量,有时候需要控制协程数,防止爬的过快被反爬
- self.header = {
- "Accept-Encoding": "gzip", # 使用gzip压缩传输数据让访问更快
- "User-Agent": ua.random
- }
- async def scrape(self, url):
- # async with self.semaphore: # 设置最大信号量,有时候需要控制协程数,防止爬的过快被反爬
- session = aiohttp.ClientSession(headers=self.header, connector=aiohttp.TCPConnector(ssl=False))
- response = await session.get(url)
- result = await response.text()
- await session.close()
- return result
- async def scrape_index(self, page):
- url = f'https://www.zhongnongwang.com/quote/product-htm-page-{page}.html'
- text = await self.scrape(url)
- await self.parse(text)
- async def parse(self, text):
- # Xpath定位提取数据
- html = etree.HTML(text)
- items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
- logging.info(f'该页有多少条信息:{len(items)}') # 一页有20条信息
- # 遍历提取出数据
- for item in items:
- name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
- price = ''.join(item.xpath('.//td[3]/text()')) # 最新报价
- unit = ''.join(item.xpath('.//td[4]/text()')) # 单位
- nums = ''.join(item.xpath('.//td[5]/text()')) # 报价数
- time_ = ''.join(item.xpath('.//td[6]/text()')) # 报价时间
- sheet.append([name, price, unit, nums, time_])
- logging.info([name, price, unit, nums, time_])
- def main(self):
- # 50页的数据
- scrape_index_tasks = [asyncio.ensure_future(self.scrape_index(page)) for page in range(1, 51)]
- loop = asyncio.get_event_loop()
- tasks = asyncio.gather(*scrape_index_tasks)
- loop.run_until_complete(tasks)
- if __name__ == '__main__':
- spider = Spider()
- spider.main()
- wb.save('data3.xlsx')
- delta = (datetime.now() - start).total_seconds()
- print("用时:{:.3f}s".format(delta))
运行结果如下:
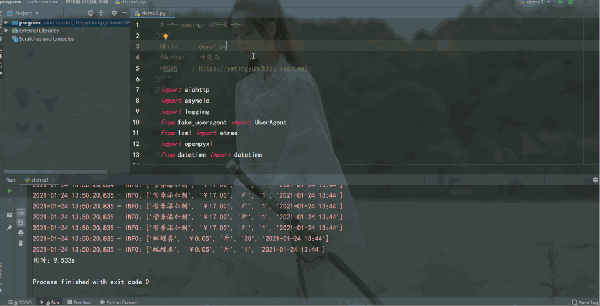
而到了协程异步爬虫,爬取速度更快,嗖的一下,用时 0.930s 就爬取完 50 页数据,aiohttp + asyncio 异步爬虫竟恐怖如斯。异步爬虫在服务器能承受高并发的前提下增加并发数量,爬取效率提升是非常可观的,比多线程还要快一些。
三种爬虫都将 50 页的数据爬取下来保存到了本地,结果如下:
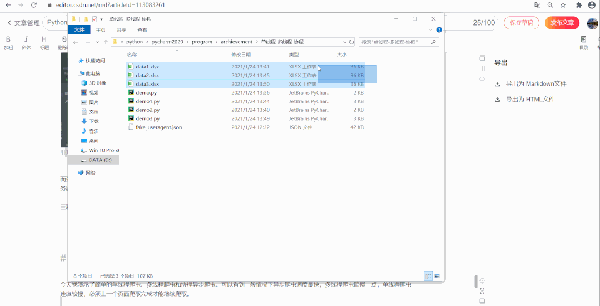
六、总结回顾
今天我演示了简单的单线程爬虫、多线程爬虫和协程异步爬虫。可以看到一般情况下异步爬虫速度最快,多线程爬虫略慢一点,单线程爬虫速度较慢,必须上一个页面爬取完成才能继续爬取。
但协程异步爬虫相对来说并不是那么好编写,数据抓取无法使用 request 库,只能使用aiohttp,而且爬取数据量大时,异步爬虫需要设置最大信号量来控制协程数,防止爬的过快被反爬。所以在实际编写 Python 爬虫时,我们一般都会使用多线程爬虫来提速,但必须注意的是网站都有 ip 访问频率限制,爬的过快可能会被封ip,所以一般我们在多线程提速的同时可以使用代理 ip 来并发地爬取数据。

近几年,互联网行业蓬勃发展,在互联网浪潮的冲击下,互联网创业已成为一种比较...
本文转载自微信公众号「bugstack虫洞栈」,作者小傅哥 。转载本文请联系bugstack...
背景 我们知道 如果在Kubernetes中支持GPU设备调度 需要做如下的工作 节点上安装...
在Python开发过程中,我们难免会遇到多重条件判断的情况的情况,此时除了用很多...
溢价 域名 的续费价格如何?通常来说,因为溢价域名的价值高于普通域名,所以溢...
基本介绍 给定 n 个权值作为 n 个叶子节点,构造一颗二叉树,若该树的带权路径长...
本文转载自公众号读芯术(ID:AI_Discovery)。 这一刻你正在应对什么挑战?这位前...
前言 统计科学家使用交互式的统计工具(比如R)来回答数据中的问题,获得全景的认...
TIOBE 公布了 2021 年 3 月的编程语言排行榜。 本月 TIOBE 指数没有什么有趣的变...
想了解更多内容,请访问: 51CTO和华为官方战略合作共建的鸿蒙技术社区 https://...

