

一、背景
携程Redis集群规模和数据规模在过去几年里快速增长,我们通过容器化解决了Redis集群快速部署的问题,并根据实际业务进行的一系列尝试,比如二次调度、自动化漂移等,在内存超分的情况下保证了宿主机的可靠性。
扩缩容方面,我们主要通过垂直扩缩容的方式解决Redis集群容量的问题,但随着集群规模扩大,这种方式逐渐遇到了瓶颈。一方面,单个Redis实例过大,会带来较大的运维风险和困难;另一方面,宿主机容量有上限,不能无止境的扩容。考虑到运维便利性和资源利用率的平衡,我们希望单个Redis实例的上限为15GB。
但实际操作中却很难做到:某些业务发展很快,经常性需要给Redis进行扩容,导致单个实例大小远超15GB;一些业务萎缩,实际使用量远低于初始申请的量,造成资源的浪费。
如何有效控制Redis实例大小呢?接下来本文将带着这个问题,逐步讲解携程Redis治理和扩缩容方面的演进历程。
二、Redis水平扩分拆
在携程开始使用Redis很长一段时间里,一直只有垂直扩缩容,原因有两点:
第一,一开始业务规模比较小,垂直扩缩容可以满足需求。垂直扩缩容对于Redis来说只是Maxmemory的配置更改,对业务透明。
第二,水平拆分/扩缩容的实现难度和成本较高。
之前文章《携程Redis治理演进之路》中已经提到,携程访问所有的Redis集群使用的是自主研发的CRedis,而部署在应用端的CRedis通过一致性hash来访问实际承载数据的Redis实例。但一致性hash是无法支持直接水平扩缩容的。因为无论增加一个节点或者删除一个节点,都会导致整个hash环的调整。
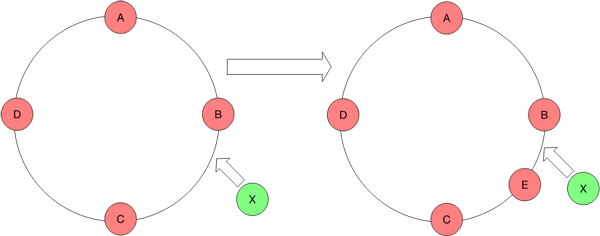
图1
如图所示,假设原始有4个分片(图1)。当添加一个节点后,它会导致某一部分的key本来是写到nodeC上而现在会被写到nodeE上,也就是无法命中之前的节点。从客户端的角度来看,key就像是丢失了。而变动的节点越多,key丢失的也越多,假设某个集群从10分片直接添加到20分片,它直接会导致50%的key丢失。删除一个节点同理,就不再赘述。
因此尽管一致性hash是个比较简单优秀的集群方案,但无法直接水平扩容一直困扰着运维和架构团队。为此,CRedis团队在2019年提出了水平拆分的方案。
CRedis水平分拆的思路比较朴素,因为在一致性hash同一个水平位置增加节点会导致数据丢失,那么不改变原来层次节点的hash规则,以某个节点为hash的起点,再来进行一次一致性hash,演变成树的结构(图2)。
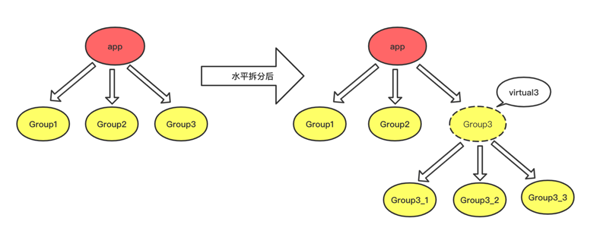
图2
如上图所示,将树形结构从一层拓展成二层,如果继续拆分新的叶子Group,则可以将树形结构拓展到三层,拆分方案可以支持到十层。叶子 Group是物理分片,直接对应的 Redis 实例,分支 Group 是虚拟分片,当Hash 命中到分支 Group 后,并没有找不到对应的Redis实例,需要再继续向下寻找,直到找到叶子 Group 为止。
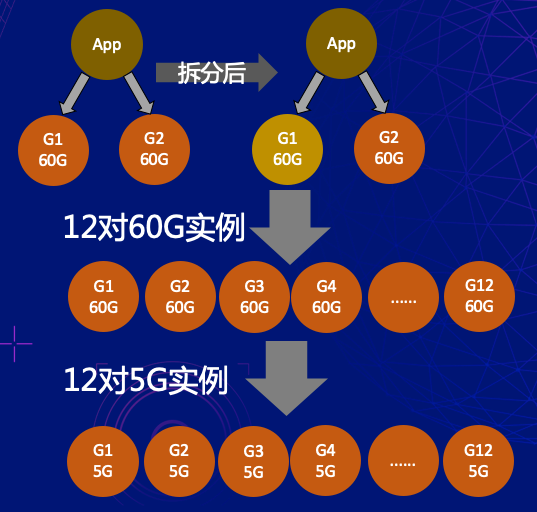
图3
CRedis水平分拆上线后,DBA将现存的绝大部分超过15G的实例都拆分成更小的实例,在一段时间内缓解了大内存实例的运维治理压力。但随着Redis规模的快速增长,不断有大的实例集群出现,此外CRedis水平分拆的缺点也逐渐暴露出来:
由此可见,水平分拆的方案虽然解决了实例过大的问题,但不能缩容的弊端也逐渐凸现了出来。尤其是在今年因疫情影响需要降本增效的背景下,一方面资源比充足,一方面宿主机上跑的都是无法缩容的实例。那么是否有更好的解决方案呢?答案是有的。
三、Redis水平扩缩容
1、设计思路
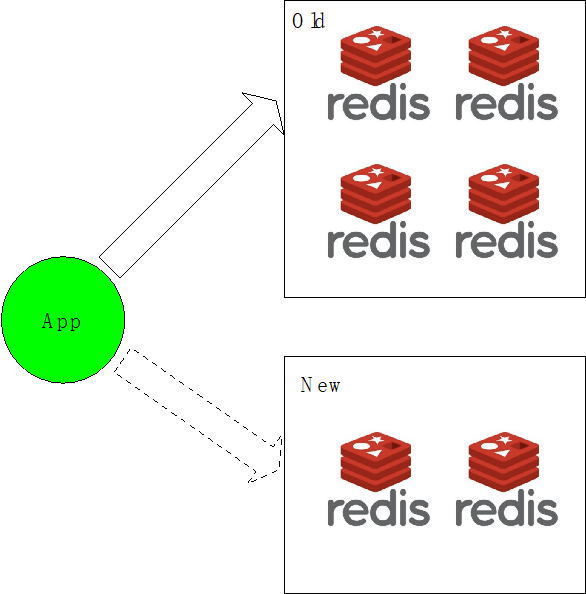
图4
既然缩分片比较困难,我们首先想到的是业务双写集群的方法,也就是业务同时双写2个新老集群,新老集群的分片数是不一样的,并且大小配置也不一样。比如之前申请4个分片现在发现资源过剩,让业务创新申请一个新的2个分片的集群,由业务来控制灰度写哪个集群(图4)。最终会迁移到新集群上,而新集群大小是满足当前业务需求的,从而达到了缩容的目的。
双写集群的方案虽然解决我们部分的问题,但对于业务的侵入比较深,此外由于双写集群引入了业务配合观察的时间,整体流程也比较长。所以,我们需要寻找更好的解决方案。
既然业务双写集群可以达到要求,基础设施如果代替业务做完这部分岂不是更好?借鉴业务双写集群的思路和云原生的不可变基础设施的理念,我们首先想到的是通过新集群替换老集群而不是原地修改集群;另外,为了在公有云上节省Redis成本,我们积累了kvrocks的实践经验,两者相结合,设计了一种高效的水平扩缩容的方案。
本方案的核心是引入了一个基于kvrocks改造的中间态binlogserver,它既是一个老集群的Slave节点,又充当了新集群的客户端。一方面,它会从Redis Master复制全量和增量数据;另一方面,它又充当客户端的角色,将复制来的数据按照新集群的一致性HASH规则写往新的集群。大致的步骤如下,具体的步骤流程可以参考下面的图所示(图5)。
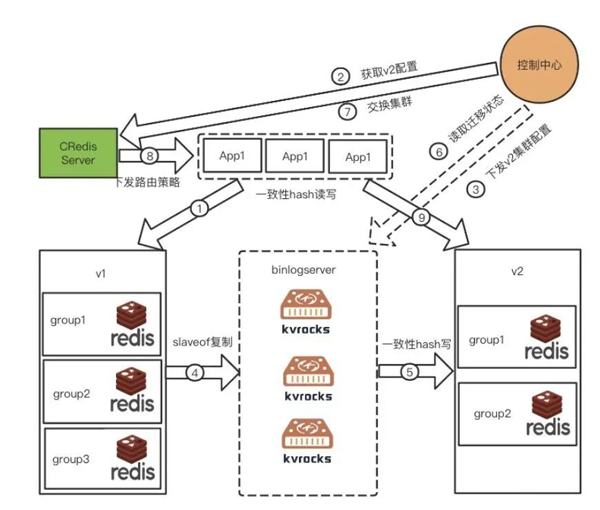
图5
通过Redis的水平扩缩容方案,我们解决了之前的几个痛点问题:
2、运维数据
水平扩缩容方案上线4个月来,已经成功完成了200多次的扩容和缩容。今年某个业务突然请求量暴增十几倍,相关集群经历了多次扩容,每次扩容大多在10分钟内完成,有效地支撑了业务发展。
另一方面,针对申请分片非常多而大但实际使用量非常小的集群,我们也借助水平扩缩容的能力快速地缩小了分片数和申请量。通过这些缩容,有效地提升了整体的资源利用率。
3、一些坑
(1)单个key过大导致key被驱逐
在实际水平扩缩容过程中,我们发现有些集群,单个实例中可能会有巨大的key(大于3G),由于V2集群的大小是根据V1大小实时算出来的平均值,一旦V1中某个实例过大,可能会导致写到V2中的某个实例大小大于预期的平均值,从而引起某些key被驱逐。因此,针对这种情况:
(2)mget扩容后会导致性能下降
对于极个别的场景,我们还发现,mget请求耗时会有明显上升,主要原因还是在于,扩容之前mget需要访问的实例数少,而分拆后访问的实例数变多。一般这种情况,我们建议业务控制单次mget的key的数量,或者将string类型改造为hash类型,通过hmget来访问数据,保证每次只会访问到一个实例,这样扩容后其吞吐量是随着分片数量线性增加,而延迟不会有增加。
四、总结和未来规划
1、Xpipe支持
目前水平扩缩容和漂移以及二次调度等一系列治理工具和策略组成了一个比较完善的闭环,有效地支撑了生产几千台宿主机,几万带超分能力Redis实例的运维治理。
但目前受制于xpipe的架构,对于接入了xpipe的集群,必须先扩缩容后再将DR端的xpipe人工补齐,自动化程度还不足,而补齐xpipe的时间比较长,比如之前是就近读本机房的Redis集群的APP,在扩缩容后可能一段时间里只能跨机房读取,必然导致延迟上升。而这种延迟上升又会影响我们对于水平扩缩容逻辑是否正确,是否需要回退的判断。因此后续我们会针对xpipe集群,也做到和普通集群一样,也就是V2集群在扩缩容写流量之前就是带DR架构的集群。
2、持久化KV存储的支持
除了Redis本身受业务欢迎使用广泛外,我们还发现有些业务需要相比Redis 更可靠的KV存储方式,比如数据保存在磁盘上而不是保存在内存里,再比如业务需要支持一些增减库存逻辑,对某个key的独占访问,实现语义近似INCRBY操作,但实际上是对于一些字符串进行merge操作。此外数据可靠性要求更高,master宕机不能丢失数据等。针对这些需求目前我们已经也有一些实践经验,将在后续文章中分享。

近几年,互联网行业蓬勃发展,在互联网浪潮的冲击下,互联网创业已成为一种比较...
TIOBE 公布了 2021 年 3 月的编程语言排行榜。 本月 TIOBE 指数没有什么有趣的变...
溢价 域名 的续费价格如何?通常来说,因为溢价域名的价值高于普通域名,所以溢...
本文转载自公众号读芯术(ID:AI_Discovery)。 这一刻你正在应对什么挑战?这位前...
想了解更多内容,请访问: 51CTO和华为官方战略合作共建的鸿蒙技术社区 https://...
在Python开发过程中,我们难免会遇到多重条件判断的情况的情况,此时除了用很多...
背景 我们知道 如果在Kubernetes中支持GPU设备调度 需要做如下的工作 节点上安装...
本文转载自微信公众号「bugstack虫洞栈」,作者小傅哥 。转载本文请联系bugstack...
前言 统计科学家使用交互式的统计工具(比如R)来回答数据中的问题,获得全景的认...
基本介绍 给定 n 个权值作为 n 个叶子节点,构造一颗二叉树,若该树的带权路径长...

