

有时候,我们要从一段很长的 URL 里面提取出域名。例如从
https://www.kingname.info/2020/10/02/copy-from-ssh/,我需要获取的是kingname.info。

可能有人会这样写代码:
- url = 'https://www.kingname.info/2020/10/02/copy-from-ssh/'
- domain = '.'.join(url.split('/')[2].split('.')[1:])
运行效果如下图所示:

但如果我给出的 URL 没有带 https://,这段代码的结果就有问题。
而且,有些域名可能有三级、四级域名,例如:blog.exercise.kingname.com.cn。显然,使用点分割以后,也不知道怎么拿到真正的域名kingname.com.cn。
还有一些人的需求可能只需要域名中的名字,例如kingname.info只要kingname,google.com.hk只要google。
对于这些需求,如果手动写规则来提取的话,会非常麻烦。
不过好在 Python 有一个第三方库已经解决了这个问题,这就是tld。
我们先来安装它:
- python3 -m pip install tld
安装完成以后,我们来看看它的使用方法:
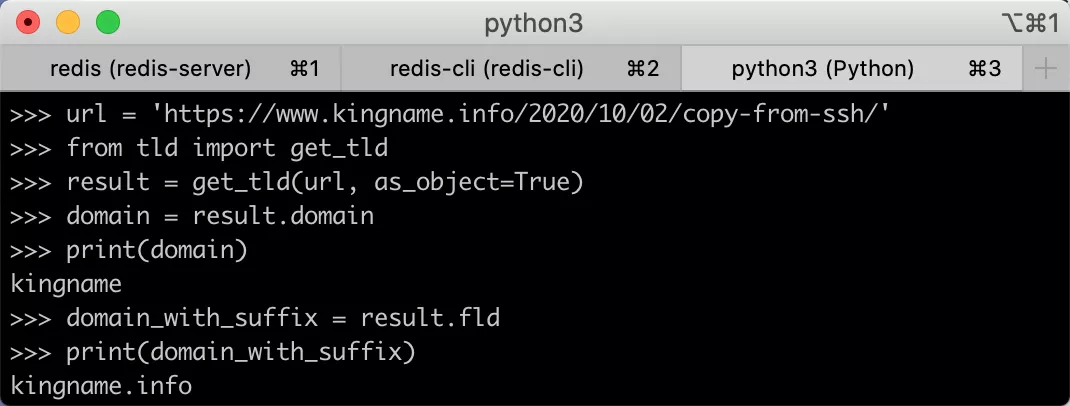
- >>> url = 'https://www.kingname.info/2020/10/02/copy-from-ssh/'
- >>> from tld import get_tld
- >>> result = get_tld(url, as_object=True)
- >>> domain = result.domain
- >>> print(domain)
- kingname
- >>> domain_with_suffix = result.fld
- >>> print(domain_with_suffix)
- kingname.info
首先使用get_tld生成一个对象,然后通过对象的.domain属性获得纯域名,使用.fld属性,获得带有后缀的域名。
运行效果如下图所示:
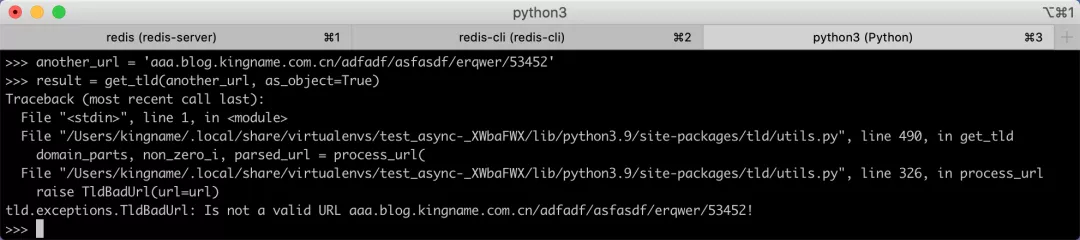
对于不含https的网址,直接使用会报错,如下图所示:
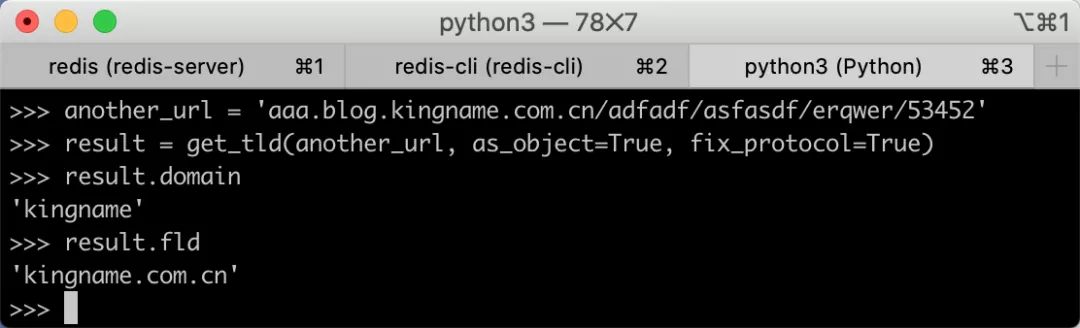
但只要加上一个参数fix_protocol=True就可以解决问题:

三千兆将落地武汉。这意味着,将来无论是室内还是室外、有线还是无线、手机还是...
据印度《金融快报》报道称,印度政府已经禁用了我国224款App,而且这个数量有望...
如今,随着国家新兴数字化基础设施的推进,5G、云计算、大数据等模块的成熟,人...
工信部近日印发《工业互联网创新发展行动计划(2021-2023年)》指出,到2023年将在...
全球知名的一些科技公司承诺为其运营的数据中心提供100%可再生能源的电力。许多...
今年双11,手机是各电商平台销售最为火爆的产品品类之一,其中5G手机为销售主流...
本文转载自微信公众号「编程杂技 」,作者theanarkh。转载本文请联系编程杂技 众...
1.这个世界除了你,再不会有人这样让我坚定到失控。 2.你逢场作戏,我将计就计...
【责任编辑: 贺鑫 TEL:(010)68476606】 本文转载自网络,原文链接:...
无论您是尝试解决问题,确保带宽密集型客户端都能正常工作、微调性能还是对Wi-Fi...

